 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgoverse
Papers and Code
Visual Implicit Geometry Transformer for Autonomous Driving
Feb 05, 2026We introduce the Visual Implicit Geometry Transformer (ViGT), an autonomous driving geometric model that estimates continuous 3D occupancy fields from surround-view camera rigs. ViGT represents a step towards foundational geometric models for autonomous driving, prioritizing scalability, architectural simplicity, and generalization across diverse sensor configurations. Our approach achieves this through a calibration-free architecture, enabling a single model to adapt to different sensor setups. Unlike general-purpose geometric foundational models that focus on pixel-aligned predictions, ViGT estimates a continuous 3D occupancy field in a birds-eye-view (BEV) addressing domain-specific requirements. ViGT naturally infers geometry from multiple camera views into a single metric coordinate frame, providing a common representation for multiple geometric tasks. Unlike most existing occupancy models, we adopt a self-supervised training procedure that leverages synchronized image-LiDAR pairs, eliminating the need for costly manual annotations. We validate the scalability and generalizability of our approach by training our model on a mixture of five large-scale autonomous driving datasets (NuScenes, Waymo, NuPlan, ONCE, and Argoverse) and achieving state-of-the-art performance on the pointmap estimation task, with the best average rank across all evaluated baselines. We further evaluate ViGT on the Occ3D-nuScenes benchmark, where ViGT achieves comparable performance with supervised methods. The source code is publicly available at \href{https://github.com/whesense/ViGT}{https://github.com/whesense/ViGT}.
Unified Sensor Simulation for Autonomous Driving
Feb 05, 2026In this work, we introduce \textbf{XSIM}, a sensor simulation framework for autonomous driving. XSIM extends 3DGUT splatting with a generalized rolling-shutter modeling tailored for autonomous driving applications. Our framework provides a unified and flexible formulation for appearance and geometric sensor modeling, enabling rendering of complex sensor distortions in dynamic environments. We identify spherical cameras, such as LiDARs, as a critical edge case for existing 3DGUT splatting due to cyclic projection and time discontinuities at azimuth boundaries leading to incorrect particle projection. To address this issue, we propose a phase modeling mechanism that explicitly accounts temporal and shape discontinuities of Gaussians projected by the Unscented Transform at azimuth borders. In addition, we introduce an extended 3D Gaussian representation that incorporates two distinct opacity parameters to resolve mismatches between geometry and color distributions. As a result, our framework provides enhanced scene representations with improved geometric consistency and photorealistic appearance. We evaluate our framework extensively on multiple autonomous driving datasets, including Waymo Open Dataset, Argoverse 2, and PandaSet. Our framework consistently outperforms strong recent baselines and achieves state-of-the-art performance across all datasets. The source code is publicly available at \href{https://github.com/whesense/XSIM}{https://github.com/whesense/XSIM}.
Correcting and Quantifying Systematic Errors in 3D Box Annotations for Autonomous Driving
Jan 20, 2026Accurate ground truth annotations are critical to supervised learning and evaluating the performance of autonomous vehicle systems. These vehicles are typically equipped with active sensors, such as LiDAR, which scan the environment in predefined patterns. 3D box annotation based on data from such sensors is challenging in dynamic scenarios, where objects are observed at different timestamps, hence different positions. Without proper handling of this phenomenon, systematic errors are prone to being introduced in the box annotations. Our work is the first to discover such annotation errors in widely used, publicly available datasets. Through our novel offline estimation method, we correct the annotations so that they follow physically feasible trajectories and achieve spatial and temporal consistency with the sensor data. For the first time, we define metrics for this problem; and we evaluate our method on the Argoverse 2, MAN TruckScenes, and our proprietary datasets. Our approach increases the quality of box annotations by more than 17% in these datasets. Furthermore, we quantify the annotation errors in them and find that the original annotations are misplaced by up to 2.5 m, with highly dynamic objects being the most affected. Finally, we test the impact of the errors in benchmarking and find that the impact is larger than the improvements that state-of-the-art methods typically achieve with respect to the previous state-of-the-art methods; showing that accurate annotations are essential for correct interpretation of performance. Our code is available at https://github.com/alexandre-justo-miro/annotation-correction-3D-boxes.
SMc2f: Robust Scenario Mining for Robotic Autonomy from Coarse to Fine
Jan 17, 2026The safety validation of autonomous robotic vehicles hinges on systematically testing their planning and control stacks against rare, safety-critical scenarios. Mining these long-tail events from massive real-world driving logs is therefore a critical step in the robotic development lifecycle. The goal of the Scenario Mining task is to retrieve useful information to enable targeted re-simulation, regression testing, and failure analysis of the robot's decision-making algorithms. RefAV, introduced by the Argoverse team, is an end-to-end framework that uses large language models (LLMs) to spatially and temporally localize scenarios described in natural language. However, this process performs retrieval on trajectory labels, ignoring the direct connection between natural language and raw RGB images, which runs counter to the intuition of video retrieval; it also depends on the quality of upstream 3D object detection and tracking. Further, inaccuracies in trajectory data lead to inaccuracies in downstream spatial and temporal localization. To address these issues, we propose Robust Scenario Mining for Robotic Autonomy from Coarse to Fine (SMc2f), a coarse-to-fine pipeline that employs vision-language models (VLMs) for coarse image-text filtering, builds a database of successful mining cases on top of RefAV and automatically retrieves exemplars to few-shot condition the LLM for more robust retrieval, and introduces text-trajectory contrastive learning to pull matched pairs together and push mismatched pairs apart in a shared embedding space, yielding a fine-grained matcher that refines the LLM's candidate trajectories. Experiments on public datasets demonstrate substantial gains in both retrieval quality and efficiency.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025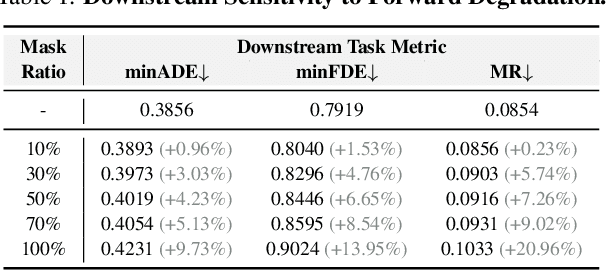
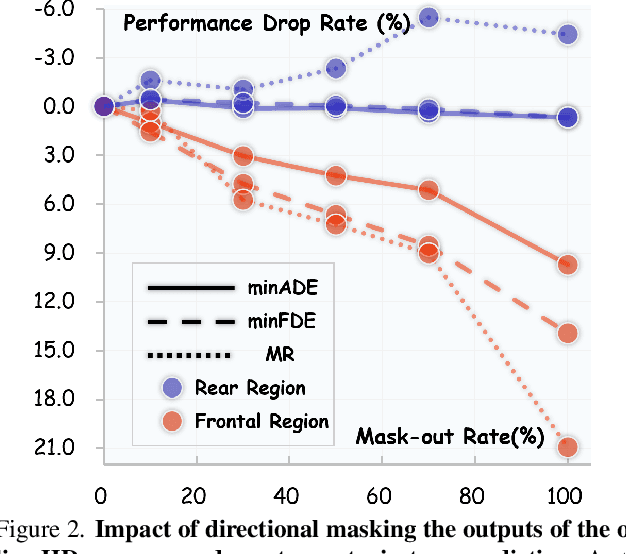
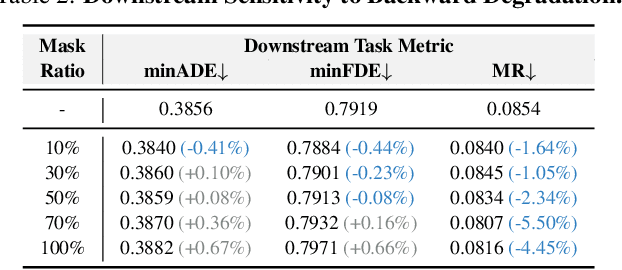
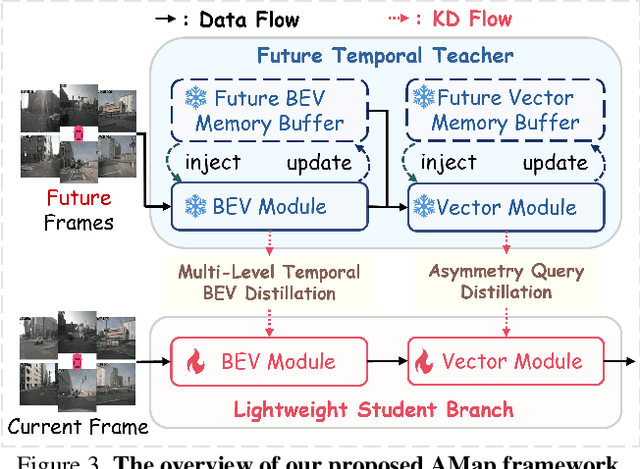
Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
StereoMV2D: A Sparse Temporal Stereo-Enhanced Framework for Robust Multi-View 3D Object Detection
Dec 19, 2025



Multi-view 3D object detection is a fundamental task in autonomous driving perception, where achieving a balance between detection accuracy and computational efficiency remains crucial. Sparse query-based 3D detectors efficiently aggregate object-relevant features from multi-view images through a set of learnable queries, offering a concise and end-to-end detection paradigm. Building on this foundation, MV2D leverages 2D detection results to provide high-quality object priors for query initialization, enabling higher precision and recall. However, the inherent depth ambiguity in single-frame 2D detections still limits the accuracy of 3D query generation. To address this issue, we propose StereoMV2D, a unified framework that integrates temporal stereo modeling into the 2D detection-guided multi-view 3D detector. By exploiting cross-temporal disparities of the same object across adjacent frames, StereoMV2D enhances depth perception and refines the query priors, while performing all computations efficiently within 2D regions of interest (RoIs). Furthermore, a dynamic confidence gating mechanism adaptively evaluates the reliability of temporal stereo cues through learning statistical patterns derived from the inter-frame matching matrix together with appearance consistency, ensuring robust detection under object appearance and occlusion. Extensive experiments on the nuScenes and Argoverse 2 datasets demonstrate that StereoMV2D achieves superior detection performance without incurring significant computational overhead. Code will be available at https://github.com/Uddd821/StereoMV2D.
CARScenes: Semantic VLM Dataset for Safe Autonomous Driving
Nov 18, 2025CAR-Scenes is a frame-level dataset for autonomous driving that enables training and evaluation of vision-language models (VLMs) for interpretable, scene-level understanding. We annotate 5,192 images drawn from Argoverse 1, Cityscapes, KITTI, and nuScenes using a 28-key category/sub-category knowledge base covering environment, road geometry, background-vehicle behavior, ego-vehicle behavior, vulnerable road users, sensor states, and a discrete severity scale (1-10), totaling 350+ leaf attributes. Labels are produced by a GPT-4o-assisted vision-language pipeline with human-in-the-loop verification; we release the exact prompts, post-processing rules, and per-field baseline model performance. CAR-Scenes also provides attribute co-occurrence graphs and JSONL records that support semantic retrieval, dataset triage, and risk-aware scenario mining across sources. To calibrate task difficulty, we include reproducible, non-benchmark baselines, notably a LoRA-tuned Qwen2-VL-2B with deterministic decoding, evaluated via scalar accuracy, micro-averaged F1 for list attributes, and severity MAE/RMSE on a fixed validation split. We publicly release the annotation and analysis scripts, including graph construction and evaluation scripts, to enable explainable, data-centric workflows for future intelligent vehicles. Dataset: https://github.com/Croquembouche/CAR-Scenes
Modified-Emergency Index (MEI): A Criticality Metric for Autonomous Driving in Lateral Conflict
Oct 31, 2025Effective, reliable, and efficient evaluation of autonomous driving safety is essential to demonstrate its trustworthiness. Criticality metrics provide an objective means of assessing safety. However, as existing metrics primarily target longitudinal conflicts, accurately quantifying the risks of lateral conflicts - prevalent in urban settings - remains challenging. This paper proposes the Modified-Emergency Index (MEI), a metric designed to quantify evasive effort in lateral conflicts. Compared to the original Emergency Index (EI), MEI refines the estimation of the time available for evasive maneuvers, enabling more precise risk quantification. We validate MEI on a public lateral conflict dataset based on Argoverse-2, from which we extract over 1,500 high-quality AV conflict cases, including more than 500 critical events. MEI is then compared with the well-established ACT and the widely used PET metrics. Results show that MEI consistently outperforms them in accurately quantifying criticality and capturing risk evolution. Overall, these findings highlight MEI as a promising metric for evaluating urban conflicts and enhancing the safety assessment framework for autonomous driving. The open-source implementation is available at https://github.com/AutoChengh/MEI.
Ensemble of Pre-Trained Models for Long-Tailed Trajectory Prediction
Sep 17, 2025This work explores the application of ensemble modeling to the multidimensional regression problem of trajectory prediction for vehicles in urban environments. As newer and bigger state-of-the-art prediction models for autonomous driving continue to emerge, an important open challenge is the problem of how to combine the strengths of these big models without the need for costly re-training. We show how, perhaps surprisingly, combining state-of-the-art deep learning models out-of-the-box (without retraining or fine-tuning) with a simple confidence-weighted average method can enhance the overall prediction. Indeed, while combining trajectory prediction models is not straightforward, this simple approach enhances performance by 10% over the best prediction model, especially in the long-tailed metrics. We show that this performance improvement holds on both the NuScenes and Argoverse datasets, and that these improvements are made across the dataset distribution. The code for our work is open source.
ProgD: Progressive Multi-scale Decoding with Dynamic Graphs for Joint Multi-agent Motion Forecasting
Sep 11, 2025Accurate motion prediction of surrounding agents is crucial for the safe planning of autonomous vehicles. Recent advancements have extended prediction techniques from individual agents to joint predictions of multiple interacting agents, with various strategies to address complex interactions within future motions of agents. However, these methods overlook the evolving nature of these interactions. To address this limitation, we propose a novel progressive multi-scale decoding strategy, termed ProgD, with the help of dynamic heterogeneous graph-based scenario modeling. In particular, to explicitly and comprehensively capture the evolving social interactions in future scenarios, given their inherent uncertainty, we design a progressive modeling of scenarios with dynamic heterogeneous graphs. With the unfolding of such dynamic heterogeneous graphs, a factorized architecture is designed to process the spatio-temporal dependencies within future scenarios and progressively eliminate uncertainty in future motions of multiple agents. Furthermore, a multi-scale decoding procedure is incorporated to improve on the future scenario modeling and consistent prediction of agents' future motion. The proposed ProgD achieves state-of-the-art performance on the INTERACTION multi-agent prediction benchmark, ranking $1^{st}$, and the Argoverse 2 multi-world forecasting benchmark.