 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Action Manifold with Multi-view Latent Priors for Robotic Manipulation
May 12, 2026This paper tackles spatial perception and manipulation challenges in Vision-Language-Action (VLA) models. To address depth ambiguity from monocular input, we leverage a pre-trained multi-view diffusion model to synthesize latent novel views and propose a Geometry-Guided Gated Transformer (G3T) that aligns multi-view features under 3D geometric guidance while adaptively filtering occlusion noise. To improve action learning efficiency, we introduce Action Manifold Learning (AML), which directly predicts actions on the valid action manifold, bypassing inefficient regression of unstructured targets like noise or velocity. Experiments on LIBERO, RoboTwin 2.0, and real-robot tasks show our method achieves superior success rate and robustness over SOTA baselines. Project page: https://junjxiao.github.io/Multi-view-VLA.github.io/.
ALAM: Algebraically Consistent Latent Transitions for Vision-Language-Action Models
May 11, 2026Vision-language-action (VLA) models remain constrained by the scarcity of action-labeled robot data, whereas action-free videos provide abundant evidence of how the physical world changes. Latent action models offer a promising way to extract such priors from videos, but reconstruction-trained latent codes are not necessarily suitable for policy generation: they may predict future observations while lacking the structure needed to be reused or generated coherently with robot actions. We introduce ALAM (Algebraic Latent Action Model), an Algebraically Consistent Latent Action Model that turns temporal relations in action-free video into structural supervision. Given frame triplets, ALAM learns latent transitions that are grounded by reconstruction while being regularized by composition and reversal consistency, encouraging a locally additive transition space. For downstream VLA learning, we freeze the pretrained encoder and use its latent transition sequences as auxiliary generative targets, co-generated with robot actions under a joint flow-matching objective. This couples structured latent transitions with flow-based policy generation, allowing the policy to exploit ALAM's locally consistent transition geometry without requiring latent-to-action decoding. Representation probes show that ALAM reduces additivity and reversibility errors by 25-85 times over unstructured latent-action baselines and improves long-horizon cumulative reconstruction. When transferred to VLA policies, ALAM raises the average success rate from 47.9% to 85.0% on MetaWorld MT50 and from 94.1% to 98.1% on LIBERO, with consistent gains on real-world manipulation tasks. Ablations further confirm that the strongest improvements arise from the synergy between algebraically structured latent transitions and joint flow matching.
ABot-Claw: A Foundation for Persistent, Cooperative, and Self-Evolving Robotic Agents
Apr 11, 2026Current embodied intelligent systems still face a substantial gap between high-level reasoning and low-level physical execution in open-world environments. Although Vision-Language-Action (VLA) models provide strong perception and intuitive responses, their open-loop nature limits long-horizon performance. Agents incorporating System 2 cognitive mechanisms improve planning, but usually operate in closed sandboxes with predefined toolkits and limited real-system control. OpenClaw provides a localized runtime with full system privileges, but lacks the embodied control architecture required for long-duration, multi-robot execution. We therefore propose ABot-Claw, an embodied extension of OpenClaw that integrates: 1) a unified embodiment interface with capability-driven scheduling for heterogeneous robot coordination; 2) a visual-centric cross-embodiment multimodal memory for persistent context retention and grounded retrieval; and 3) a critic-based closed-loop feedback mechanism with a generalist reward model for online progress evaluation, local correction, and replanning. With a decoupled architecture spanning the OpenClaw layer, shared service layer, and robot embodiment layer, ABot-Claw enables real-world interaction, closes the loop from natural language intent to physical action, and supports progressively self-evolving robotic agents in open, dynamic environments.
ABot-PhysWorld: Interactive World Foundation Model for Robotic Manipulation with Physics Alignment
Mar 24, 2026Video-based world models offer a powerful paradigm for embodied simulation and planning, yet state-of-the-art models often generate physically implausible manipulations - such as object penetration and anti-gravity motion - due to training on generic visual data and likelihood-based objectives that ignore physical laws. We present ABot-PhysWorld, a 14B Diffusion Transformer model that generates visually realistic, physically plausible, and action-controllable videos. Built on a curated dataset of three million manipulation clips with physics-aware annotation, it uses a novel DPO-based post-training framework with decoupled discriminators to suppress unphysical behaviors while preserving visual quality. A parallel context block enables precise spatial action injection for cross-embodiment control. To better evaluate generalization, we introduce EZSbench, the first training-independent embodied zero-shot benchmark combining real and synthetic unseen robot-task-scene combinations. It employs a decoupled protocol to separately assess physical realism and action alignment. ABot-PhysWorld achieves new state-of-the-art performance on PBench and EZSbench, surpassing Veo 3.1 and Sora v2 Pro in physical plausibility and trajectory consistency. We will release EZSbench to promote standardized evaluation in embodied video generation.
Neural Implicit Action Fields: From Discrete Waypoints to Continuous Functions for Vision-Language-Action Models
Mar 02, 2026Despite the rapid progress of Vision-Language-Action (VLA) models, the prevailing paradigm of predicting discrete waypoints remains fundamentally misaligned with the intrinsic continuity of physical motion. This discretization imposes rigid sampling rates, lacks high-order differentiability, and introduces quantization artifacts that hinder precise, compliant interaction. We propose Neural Implicit Action Fields (NIAF), a paradigm shift that reformulates action prediction from discrete waypoints to continuous action function regression. By utilizing an MLLM as a hierarchical spectral modulator over a learnable motion prior, NIAF synthesizes infinite-resolution trajectories as continuous-time manifolds. This formulation enables analytical differentiability, allowing for explicit supervision of velocity, acceleration, and jerk to ensure mathematical consistency and physical plausibility. Our approach achieves state-of-the-art results on CALVIN and LIBERO benchmarks across diverse backbones. Furthermore, real-world experiments demonstrate that NIAF enables stable impedance control, bridging the gap between high-level semantic understanding and low-level dynamic execution.
MindDriver: Introducing Progressive Multimodal Reasoning for Autonomous Driving
Feb 25, 2026Vision-Language Models (VLM) exhibit strong reasoning capabilities, showing promise for end-to-end autonomous driving systems. Chain-of-Thought (CoT), as VLM's widely used reasoning strategy, is facing critical challenges. Existing textual CoT has a large gap between text semantic space and trajectory physical space. Although the recent approach utilizes future image to replace text as CoT process, it lacks clear planning-oriented objective guidance to generate images with accurate scene evolution. To address these, we innovatively propose MindDriver, a progressive multimodal reasoning framework that enables VLM to imitate human-like progressive thinking for autonomous driving. MindDriver presents semantic understanding, semantic-to-physical space imagination, and physical-space trajectory planning. To achieve aligned reasoning processes in MindDriver, we develop a feedback-guided automatic data annotation pipeline to generate aligned multimodal reasoning training data. Furthermore, we develop a progressive reinforcement fine-tuning method to optimize the alignment through progressive high- level reward-based learning. MindDriver demonstrates superior performance in both nuScences open-loop and Bench2Drive closed-loop evaluation. Codes are available at https://github.com/hotdogcheesewhite/MindDriver.
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Feb 11, 2026Building general-purpose embodied agents across diverse hardware remains a central challenge in robotics, often framed as the ''one-brain, many-forms'' paradigm. Progress is hindered by fragmented data, inconsistent representations, and misaligned training objectives. We present ABot-M0, a framework that builds a systematic data curation pipeline while jointly optimizing model architecture and training strategies, enabling end-to-end transformation of heterogeneous raw data into unified, efficient representations. From six public datasets, we clean, standardize, and balance samples to construct UniACT-dataset, a large-scale dataset with over 6 million trajectories and 9,500 hours of data, covering diverse robot morphologies and task scenarios. Unified pre-training improves knowledge transfer and generalization across platforms and tasks, supporting general-purpose embodied intelligence. To improve action prediction efficiency and stability, we propose the Action Manifold Hypothesis: effective robot actions lie not in the full high-dimensional space but on a low-dimensional, smooth manifold governed by physical laws and task constraints. Based on this, we introduce Action Manifold Learning (AML), which uses a DiT backbone to predict clean, continuous action sequences directly. This shifts learning from denoising to projection onto feasible manifolds, improving decoding speed and policy stability. ABot-M0 supports modular perception via a dual-stream mechanism that integrates VLM semantics with geometric priors and multi-view inputs from plug-and-play 3D modules such as VGGT and Qwen-Image-Edit, enhancing spatial understanding without modifying the backbone and mitigating standard VLM limitations in 3D reasoning. Experiments show components operate independently with additive benefits. We will release all code and pipelines for reproducibility and future research.
MerNav: A Highly Generalizable Memory-Execute-Review Framework for Zero-Shot Object Goal Navigation
Feb 05, 2026Visual Language Navigation (VLN) is one of the fundamental capabilities for embodied intelligence and a critical challenge that urgently needs to be addressed. However, existing methods are still unsatisfactory in terms of both success rate (SR) and generalization: Supervised Fine-Tuning (SFT) approaches typically achieve higher SR, while Training-Free (TF) approaches often generalize better, but it is difficult to obtain both simultaneously. To this end, we propose a Memory-Execute-Review framework. It consists of three parts: a hierarchical memory module for providing information support, an execute module for routine decision-making and actions, and a review module for handling abnormal situations and correcting behavior. We validated the effectiveness of this framework on the Object Goal Navigation task. Across 4 datasets, our average SR achieved absolute improvements of 7% and 5% compared to all baseline methods under TF and Zero-Shot (ZS) settings, respectively. On the most commonly used HM3D_v0.1 and the more challenging open vocabulary dataset HM3D_OVON, the SR improved by 8% and 6%, under ZS settings. Furthermore, on the MP3D and HM3D_OVON datasets, our method not only outperformed all TF methods but also surpassed all SFT methods, achieving comprehensive leadership in both SR (5% and 2%) and generalization.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025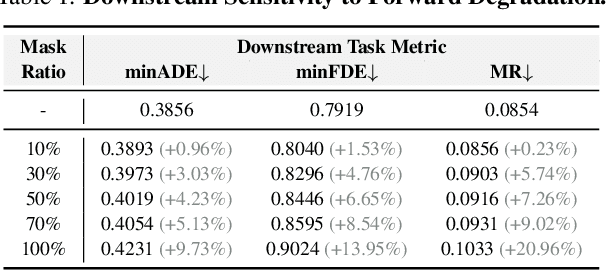
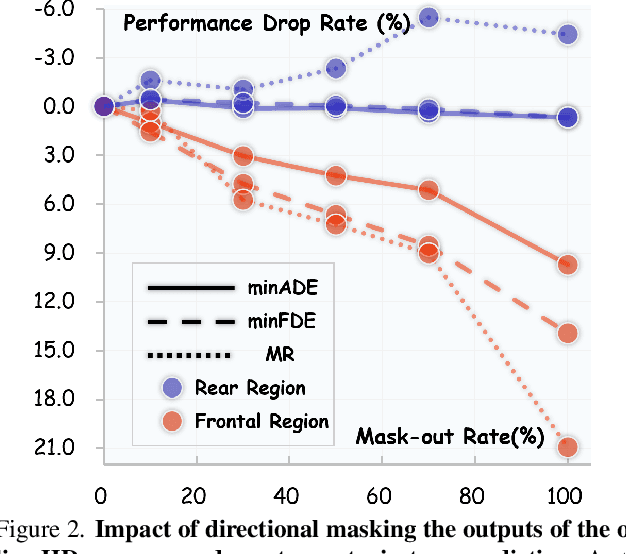
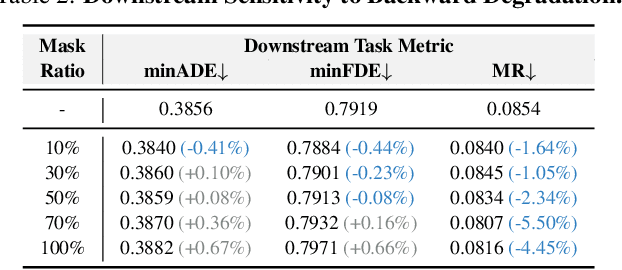
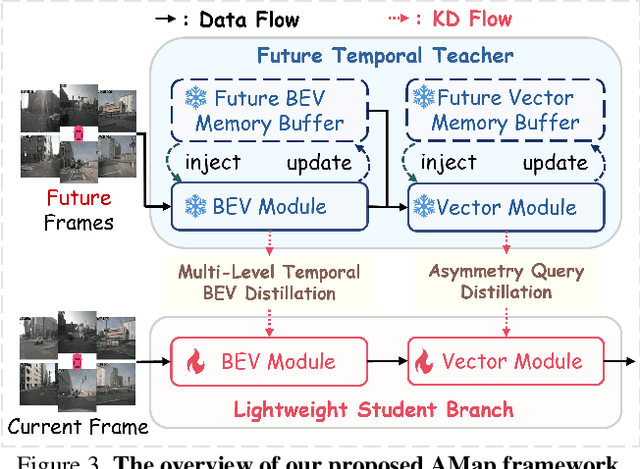
Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
Sep 26, 2025



Vision-and-Language Navigation requires an embodied agent to navigate through unseen environments, guided by natural language instructions and a continuous video stream. Recent advances in VLN have been driven by the powerful semantic understanding of Multimodal Large Language Models. However, these methods typically rely on explicit semantic memory, such as building textual cognitive maps or storing historical visual frames. This type of method suffers from spatial information loss, computational redundancy, and memory bloat, which impede efficient navigation. Inspired by the implicit scene representation in human navigation, analogous to the left brain's semantic understanding and the right brain's spatial cognition, we propose JanusVLN, a novel VLN framework featuring a dual implicit neural memory that models spatial-geometric and visual-semantic memory as separate, compact, and fixed-size neural representations. This framework first extends the MLLM to incorporate 3D prior knowledge from the spatial-geometric encoder, thereby enhancing the spatial reasoning capabilities of models based solely on RGB input. Then, the historical key-value caches from the spatial-geometric and visual-semantic encoders are constructed into a dual implicit memory. By retaining only the KVs of tokens in the initial and sliding window, redundant computation is avoided, enabling efficient incremental updates. Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance. For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data. This indicates that the proposed dual implicit neural memory, as a novel paradigm, explores promising new directions for future VLN research. Ours project page: https://miv-xjtu.github.io/JanusVLN.github.io/.