 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025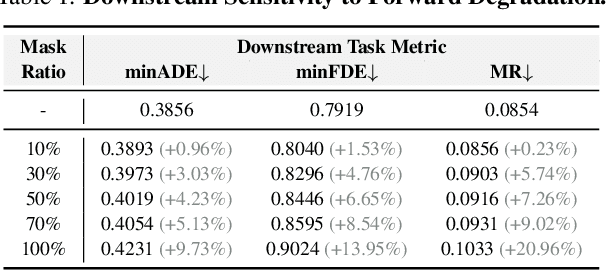
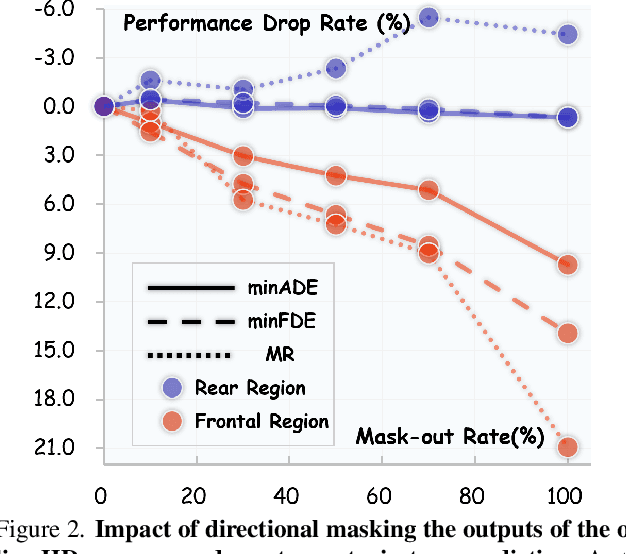
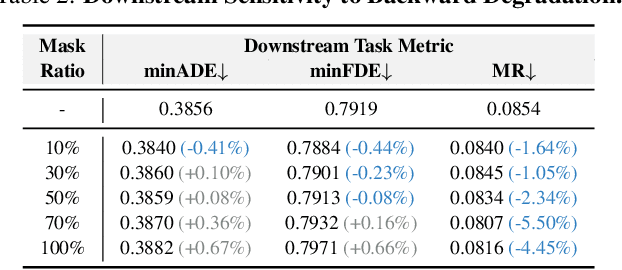
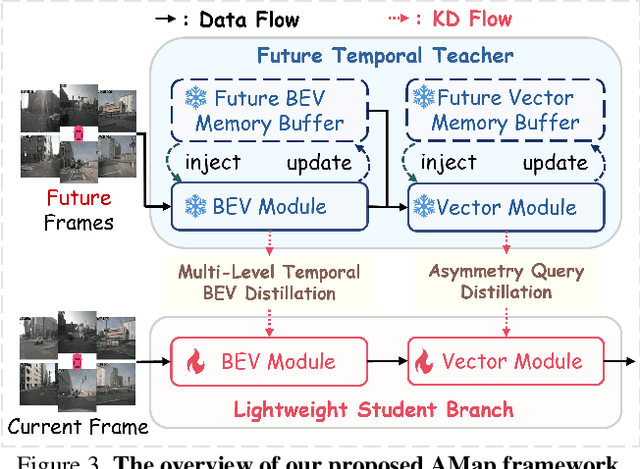
Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
EagleVision: A Dual-Stage Framework with BEV-grounding-based Chain-of-Thought for Spatial Intelligence
Dec 17, 2025Recent spatial intelligence approaches typically attach 3D cues to 2D reasoning pipelines or couple MLLMs with black-box reconstruction modules, leading to weak spatial consistency, limited viewpoint diversity, and evidence chains that cannot be traced back to supporting views. Frameworks for "thinking with images" (e.g., ChatGPT-o3 and DeepEyes) show that stepwise multimodal reasoning can emerge by interleaving hypothesis formation with active acquisition of visual evidence, but they do not address three key challenges in spatial Chain-of-Thought (CoT): building global space perception under strict token budgets, explicitly associating 3D hypotheses with video frames for verification, and designing spatially grounded rewards for reinforcement learning. To address these issues, we present EagleVision, a dual-stage framework for progressive spatial cognition through macro perception and micro verification. In the macro perception stage, EagleVision employs a semantics-perspective-fusion determinantal point process (SPF-DPP) to select a compact set of geometry- and semantics-aware keyframes from long videos under a fixed token budget. In the micro verification stage, we formalize spatial CoT as BEV-grounded pose querying: the agent iteratively predicts poses on a BEV plane, retrieves the nearest real frames, and is trained purely by reinforcement learning with a spatial grounding reward that scores the consistency between predicted poses and observed views. On VSI-Bench, EagleVision achieves state-of-the-art performance among open-source vision-language models, demonstrating strong and generalizable spatial understanding.
Driving by Hybrid Navigation: An Online HD-SD Map Association Framework and Benchmark for Autonomous Vehicles
Jul 10, 2025



Autonomous vehicles rely on global standard-definition (SD) maps for road-level route planning and online local high-definition (HD) maps for lane-level navigation. However, recent work concentrates on construct online HD maps, often overlooking the association of global SD maps with online HD maps for hybrid navigation, making challenges in utilizing online HD maps in the real world. Observing the lack of the capability of autonomous vehicles in navigation, we introduce \textbf{O}nline \textbf{M}ap \textbf{A}ssociation, the first benchmark for the association of hybrid navigation-oriented online maps, which enhances the planning capabilities of autonomous vehicles. Based on existing datasets, the OMA contains 480k of roads and 260k of lane paths and provides the corresponding metrics to evaluate the performance of the model. Additionally, we propose a novel framework, named Map Association Transformer, as the baseline method, using path-aware attention and spatial attention mechanisms to enable the understanding of geometric and topological correspondences. The code and dataset can be accessed at https://github.com/WallelWan/OMA-MAT.
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
May 23, 2025Visual language models (VLMs) have attracted increasing interest in autonomous driving due to their powerful reasoning capabilities. However, existing VLMs typically utilize discrete text Chain-of-Thought (CoT) tailored to the current scenario, which essentially represents highly abstract and symbolic compression of visual information, potentially leading to spatio-temporal relationship ambiguity and fine-grained information loss. Is autonomous driving better modeled on real-world simulation and imagination than on pure symbolic logic? In this paper, we propose a spatio-temporal CoT reasoning method that enables models to think visually. First, VLM serves as a world model to generate unified image frame for predicting future world states: where perception results (e.g., lane divider and 3D detection) represent the future spatial relationships, and ordinary future frame represent the temporal evolution relationships. This spatio-temporal CoT then serves as intermediate reasoning steps, enabling the VLM to function as an inverse dynamics model for trajectory planning based on current observations and future predictions. To implement visual generation in VLMs, we propose a unified pretraining paradigm integrating visual generation and understanding, along with a progressive visual CoT enhancing autoregressive image generation. Extensive experimental results demonstrate the effectiveness of the proposed method, advancing autonomous driving towards visual reasoning.