 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6D Pose Estimation Using Rgb-d
Papers and Code
Pickalo: Leveraging 6D Pose Estimation for Low-Cost Industrial Bin Picking
Apr 06, 2026Bin picking in real industrial environments remains challenging due to severe clutter, occlusions, and the high cost of traditional 3D sensing setups. We present Pickalo, a modular 6D pose-based bin-picking pipeline built entirely on low-cost hardware. A wrist-mounted RGB-D camera actively explores the scene from multiple viewpoints, while raw stereo streams are processed with BridgeDepth to obtain refined depth maps suitable for accurate collision reasoning. Object instances are segmented with a Mask-RCNN model trained purely on photorealistic synthetic data and localized using the zero-shot SAM-6D pose estimator. A pose buffer module fuses multi-view observations over time, handling object symmetries and significantly reducing pose noise. Offline, we generate and curate large sets of antipodal grasp candidates per object; online, a utility-based ranking and fast collision checking are queried for the grasp planning. Deployed on a UR5e with a parallel-jaw gripper and an Intel RealSense D435i, Pickalo achieves up to 600 mean picks per hour with 96-99% grasp success and robust performance over 30-minute runs on densely filled euroboxes. Ablation studies demonstrate the benefits of enhanced depth estimation and of the pose buffer for long-term stability and throughput in realistic industrial conditions. Videos are available at https://mesh-iit.github.io/project-jl2-camozzi/
Exploring 6D Object Pose Estimation with Deformation
Apr 08, 2026We present DeSOPE, a large-scale dataset for 6DoF deformed objects. Most 6D object pose methods assume rigid or articulated objects, an assumption that fails in practice as objects deviate from their canonical shapes due to wear, impact, or deformation. To model this, we introduce the DeSOPE dataset, which features high-fidelity 3D scans of 26 common object categories, each captured in one canonical state and three deformed configurations, with accurate 3D registration to the canonical mesh. Additionally, it features an RGB-D dataset with 133K frames across diverse scenarios and 665K pose annotations produced via a semi-automatic pipeline. We begin by annotating 2D masks for each instance, then compute initial poses using an object pose method, refine them through an object-level SLAM system, and finally perform manual verification to produce the final annotations. We evaluate several object pose methods and find that performance drops sharply with increasing deformation, suggesting that robust handling of such deformations is critical for practical applications. The project page and dataset are available at https://desope-6d.github.io/}{https://desope-6d.github.io/.
MLRecon: Robust Markerless Freehand 3D Ultrasound Reconstruction via Coarse-to-Fine Pose Estimation
Mar 01, 2026Freehand 3D ultrasound (US) reconstruction promises volumetric imaging with the flexibility of standard 2D probes, yet existing tracking paradigms face a restrictive trilemma: marker-based systems demand prohibitive costs, inside-out methods require intrusive sensor attachment, and sensorless approaches suffer from severe cumulative drift. To overcome these limitations, we present MLRecon, a robust markerless 3D US reconstruction framework delivering drift-resilient 6D probe pose tracking using a single commodity RGB-D camera. Leveraging the generalization power of vision foundation models, our pipeline enables continuous markerless tracking of the probe, augmented by a vision-guided divergence detector that autonomously monitors tracking integrity and triggers failure recovery to ensure uninterrupted scanning. Crucially, we further propose a dual-stage pose refinement network that explicitly disentangles high-frequency jitter from low-frequency bias, effectively denoising the trajectory while maintaining the kinematic fidelity of operator maneuvers. Experiments demonstrate that MLRecon significantly outperforms competing sensorless and sensor-aided methods, achieving average position errors as low as 0.88 mm on complex trajectories and yielding high-quality 3D reconstructions with sub-millimeter mean surface accuracy. This establishes a new benchmark for low-cost, accessible volumetric US imaging in resource-limited clinical settings.
IndustryShapes: An RGB-D Benchmark dataset for 6D object pose estimation of industrial assembly components and tools
Feb 05, 2026We introduce IndustryShapes, a new RGB-D benchmark dataset of industrial tools and components, designed for both instance-level and novel object 6D pose estimation approaches. The dataset provides a realistic and application-relevant testbed for benchmarking these methods in the context of industrial robotics bridging the gap between lab-based research and deployment in real-world manufacturing scenarios. Unlike many previous datasets that focus on household or consumer products or use synthetic, clean tabletop datasets, or objects captured solely in controlled lab environments, IndustryShapes introduces five new object types with challenging properties, also captured in realistic industrial assembly settings. The dataset has diverse complexity, from simple to more challenging scenes, with single and multiple objects, including scenes with multiple instances of the same object and it is organized in two parts: the classic set and the extended set. The classic set includes a total of 4,6k images and 6k annotated poses. The extended set introduces additional data modalities to support the evaluation of model-free and sequence-based approaches. To the best of our knowledge, IndustryShapes is the first dataset to offer RGB-D static onboarding sequences. We further evaluate the dataset on a representative set of state-of-the art methods for instance-based and novel object 6D pose estimation, including also object detection, segmentation, showing that there is room for improvement in this domain. The dataset page can be found in https://pose-lab.github.io/IndustryShapes.
SurgPose: Generalisable Surgical Instrument Pose Estimation using Zero-Shot Learning and Stereo Vision
May 16, 2025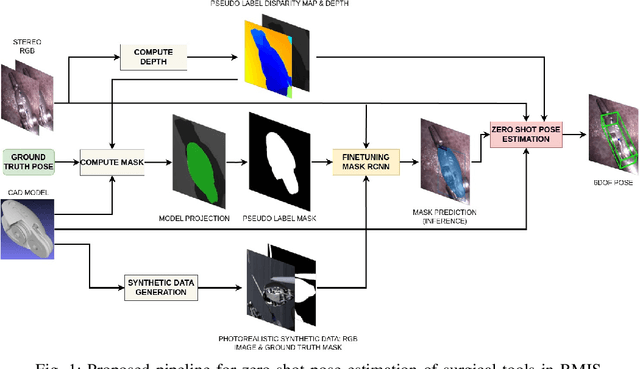


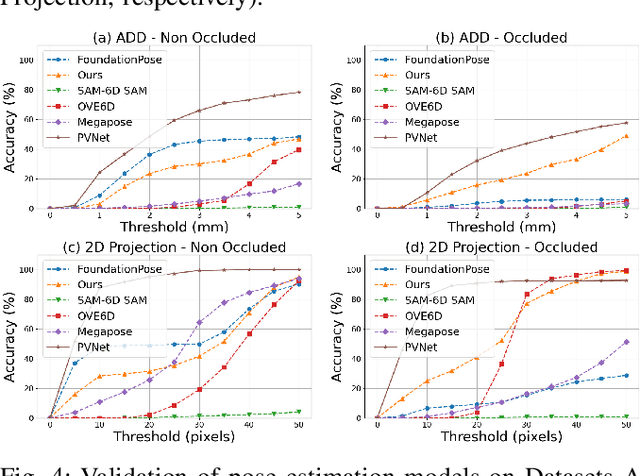
Accurate pose estimation of surgical tools in Robot-assisted Minimally Invasive Surgery (RMIS) is essential for surgical navigation and robot control. While traditional marker-based methods offer accuracy, they face challenges with occlusions, reflections, and tool-specific designs. Similarly, supervised learning methods require extensive training on annotated datasets, limiting their adaptability to new tools. Despite their success in other domains, zero-shot pose estimation models remain unexplored in RMIS for pose estimation of surgical instruments, creating a gap in generalising to unseen surgical tools. This paper presents a novel 6 Degrees of Freedom (DoF) pose estimation pipeline for surgical instruments, leveraging state-of-the-art zero-shot RGB-D models like the FoundationPose and SAM-6D. We advanced these models by incorporating vision-based depth estimation using the RAFT-Stereo method, for robust depth estimation in reflective and textureless environments. Additionally, we enhanced SAM-6D by replacing its instance segmentation module, Segment Anything Model (SAM), with a fine-tuned Mask R-CNN, significantly boosting segmentation accuracy in occluded and complex conditions. Extensive validation reveals that our enhanced SAM-6D surpasses FoundationPose in zero-shot pose estimation of unseen surgical instruments, setting a new benchmark for zero-shot RGB-D pose estimation in RMIS. This work enhances the generalisability of pose estimation for unseen objects and pioneers the application of RGB-D zero-shot methods in RMIS.
In-Hand Object Pose Estimation via Visual-Tactile Fusion
Jun 12, 2025



Accurate in-hand pose estimation is crucial for robotic object manipulation, but visual occlusion remains a major challenge for vision-based approaches. This paper presents an approach to robotic in-hand object pose estimation, combining visual and tactile information to accurately determine the position and orientation of objects grasped by a robotic hand. We address the challenge of visual occlusion by fusing visual information from a wrist-mounted RGB-D camera with tactile information from vision-based tactile sensors mounted on the fingertips of a robotic gripper. Our approach employs a weighting and sensor fusion module to combine point clouds from heterogeneous sensor types and control each modality's contribution to the pose estimation process. We use an augmented Iterative Closest Point (ICP) algorithm adapted for weighted point clouds to estimate the 6D object pose. Our experiments show that incorporating tactile information significantly improves pose estimation accuracy, particularly when occlusion is high. Our method achieves an average pose estimation error of 7.5 mm and 16.7 degrees, outperforming vision-only baselines by up to 20%. We also demonstrate the ability of our method to perform precise object manipulation in a real-world insertion task.
CAP-Net: A Unified Network for 6D Pose and Size Estimation of Categorical Articulated Parts from a Single RGB-D Image
Apr 15, 2025This paper tackles category-level pose estimation of articulated objects in robotic manipulation tasks and introduces a new benchmark dataset. While recent methods estimate part poses and sizes at the category level, they often rely on geometric cues and complex multi-stage pipelines that first segment parts from the point cloud, followed by Normalized Part Coordinate Space (NPCS) estimation for 6D poses. These approaches overlook dense semantic cues from RGB images, leading to suboptimal accuracy, particularly for objects with small parts. To address these limitations, we propose a single-stage Network, CAP-Net, for estimating the 6D poses and sizes of Categorical Articulated Parts. This method combines RGB-D features to generate instance segmentation and NPCS representations for each part in an end-to-end manner. CAP-Net uses a unified network to simultaneously predict point-wise class labels, centroid offsets, and NPCS maps. A clustering algorithm then groups points of the same predicted class based on their estimated centroid distances to isolate each part. Finally, the NPCS region of each part is aligned with the point cloud to recover its final pose and size. To bridge the sim-to-real domain gap, we introduce the RGBD-Art dataset, the largest RGB-D articulated dataset to date, featuring photorealistic RGB images and depth noise simulated from real sensors. Experimental evaluations on the RGBD-Art dataset demonstrate that our method significantly outperforms the state-of-the-art approach. Real-world deployments of our model in robotic tasks underscore its robustness and exceptional sim-to-real transfer capabilities, confirming its substantial practical utility. Our dataset, code and pre-trained models are available on the project page.
One2Any: One-Reference 6D Pose Estimation for Any Object
May 07, 20256D object pose estimation remains challenging for many applications due to dependencies on complete 3D models, multi-view images, or training limited to specific object categories. These requirements make generalization to novel objects difficult for which neither 3D models nor multi-view images may be available. To address this, we propose a novel method One2Any that estimates the relative 6-degrees of freedom (DOF) object pose using only a single reference-single query RGB-D image, without prior knowledge of its 3D model, multi-view data, or category constraints. We treat object pose estimation as an encoding-decoding process, first, we obtain a comprehensive Reference Object Pose Embedding (ROPE) that encodes an object shape, orientation, and texture from a single reference view. Using this embedding, a U-Net-based pose decoding module produces Reference Object Coordinate (ROC) for new views, enabling fast and accurate pose estimation. This simple encoding-decoding framework allows our model to be trained on any pair-wise pose data, enabling large-scale training and demonstrating great scalability. Experiments on multiple benchmark datasets demonstrate that our model generalizes well to novel objects, achieving state-of-the-art accuracy and robustness even rivaling methods that require multi-view or CAD inputs, at a fraction of compute.
* accepted by CVPR 2025
GraspClutter6D: A Large-scale Real-world Dataset for Robust Perception and Grasping in Cluttered Scenes
Apr 09, 2025



Robust grasping in cluttered environments remains an open challenge in robotics. While benchmark datasets have significantly advanced deep learning methods, they mainly focus on simplistic scenes with light occlusion and insufficient diversity, limiting their applicability to practical scenarios. We present GraspClutter6D, a large-scale real-world grasping dataset featuring: (1) 1,000 highly cluttered scenes with dense arrangements (14.1 objects/scene, 62.6\% occlusion), (2) comprehensive coverage across 200 objects in 75 environment configurations (bins, shelves, and tables) captured using four RGB-D cameras from multiple viewpoints, and (3) rich annotations including 736K 6D object poses and 9.3B feasible robotic grasps for 52K RGB-D images. We benchmark state-of-the-art segmentation, object pose estimation, and grasping detection methods to provide key insights into challenges in cluttered environments. Additionally, we validate the dataset's effectiveness as a training resource, demonstrating that grasping networks trained on GraspClutter6D significantly outperform those trained on existing datasets in both simulation and real-world experiments. The dataset, toolkit, and annotation tools are publicly available on our project website: https://sites.google.com/view/graspclutter6d.
6DOPE-GS: Online 6D Object Pose Estimation using Gaussian Splatting
Dec 02, 2024Efficient and accurate object pose estimation is an essential component for modern vision systems in many applications such as Augmented Reality, autonomous driving, and robotics. While research in model-based 6D object pose estimation has delivered promising results, model-free methods are hindered by the high computational load in rendering and inferring consistent poses of arbitrary objects in a live RGB-D video stream. To address this issue, we present 6DOPE-GS, a novel method for online 6D object pose estimation \& tracking with a single RGB-D camera by effectively leveraging advances in Gaussian Splatting. Thanks to the fast differentiable rendering capabilities of Gaussian Splatting, 6DOPE-GS can simultaneously optimize for 6D object poses and 3D object reconstruction. To achieve the necessary efficiency and accuracy for live tracking, our method uses incremental 2D Gaussian Splatting with an intelligent dynamic keyframe selection procedure to achieve high spatial object coverage and prevent erroneous pose updates. We also propose an opacity statistic-based pruning mechanism for adaptive Gaussian density control, to ensure training stability and efficiency. We evaluate our method on the HO3D and YCBInEOAT datasets and show that 6DOPE-GS matches the performance of state-of-the-art baselines for model-free simultaneous 6D pose tracking and reconstruction while providing a 5$\times$ speedup. We also demonstrate the method's suitability for live, dynamic object tracking and reconstruction in a real-world setting.