 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARBOR: A Harness Framework for Agentic Robot Reinforcement Learning
Jun 07, 2026Reinforcement learning (RL) has become a powerful paradigm for robot learning, particularly in sim-to-real settings, but its broader adoption remains limited by the engineering pipeline surrounding the algorithms. Building tasks, shaping rewards, and tuning hyperparameters require substantial expert effort, making RL workflows costly and difficult to scale. We introduce HARBOR, an agentic framework that frames robot RL automation as a harness-engineering problem: given a simulator codebase and a task specification, it automates the workflow from environment setup to policy training in simulation. HARBOR decomposes such high-level objectives into bounded stages executed by specialized agents through standardized commands, persistent artifacts, executable gates, and reusable knowledge, and scales iteration via decentralized parallel trials and experience learning across runs. We evaluate HARBOR across 6 benchmarks and 16 tasks in total, spanning manipulation, locomotion, and bimanual dexterous control. We demonstrate that HARBOR automates the simulation RL workflow end-to-end, designs rewards, tunes algorithms to match or improve over default configurations, and reduces engineering effort at practical token and wall-clock cost; the resulting policies can also be transferred to real robots.
Multi-Resolution Tactile Imitation Learning for Contact-Rich Robotic Manipulation
Jun 04, 2026Touch sensing is beneficial for solving a wide variety of manipulation tasks. While there exists a wide range of tactile sensors with different properties, exploiting the fusion of multiple heterogeneous tactile sensors to improve manipulation learning remains underexplored. We present Multi-Resolution Tactile Sensing (MiTaS), a representation framework that leverages multiple tactile sensors operating at different temporal resolutions in order to solve complex contact-rich manipulation tasks. We propose a novel architecture using modality-specific convolutional stems and transformer-based fusion that effectively fuses information from an RGB camera stream, a vision-based GelSight Mini sensor and a high-frequency event-based Evetac sensor. This multi-sensor representation then conditions a flow-matching policy for solving downstream tasks. Experimental results across five contact-rich manipulation tasks demonstrate the effectiveness of multi-resolution tactile features in imitation learning. MiTaS achieves an average success rate of 80 %, while vision-only (31 %) and visual-tactile (54 %) baselines cannot solve the task reliably. Co-training a visuo-tactile model with multi-tactile data boosts performance by over 10 \% in certain tasks, without having access to the Evetac sensor during policy evaluation. A detailed sensor-reading and attention analysis reveals the importance of different sensors throughout task execution, validating our multi-resolution tactile sensing approach. Project Page: http://mitas-touch.github.io.
Nautilus: From One Prompt to Plug-and-Play Robot Learning
May 12, 2026Robot learning research is fragmented across policy families, benchmark suites, and real robots; each implementation is entangled with the others in a complex combination matrix, making it an engineering nightmare to port any single element. General-purpose coding agents may occasionally bridge specific setups, but cannot close this gap at scale because they lack the procedural priors and validation practices that characterize robotics research workflows. We propose NAUTILUS, an open-source harness that turns a single user prompt -- for example, "Evaluate policy A with benchmark B" -- into ready-to-use reproduction, evaluation, fine-tuning, and deployment workflows. NAUTILUS provides: plug-and-play agent skill sets with distilled priors from robotics research; typed contracts among policies, simulators/benchmarks, and real-world robots; unified interfaces and execution environments; and a trustworthy agentic coding workflow with explicit, automated validation, and testing at each milestone. NAUTILUS can not only automatically generate the required adapters and containers for existing implementations, but also wrap and onboard new or user-provided policies, simulators/benchmarks, and robots, all connected via a uniform interface. This expands cross-validation coverage without hand-written glue code. Like a nautilus shell that grows by adding chambers, NAUTILUS scales by extending its execution in chambered units, making it a research harness for scalability rather than a hand-curated framework, and aiming to reduce the engineering burden of cross-family reproduction and evaluation in the ever-growing robot learning ecosystem.
Think Twice, Act Once: Verifier-Guided Action Selection For Embodied Agents
May 12, 2026Building generalist embodied agents capable of solving complex real-world tasks remains a fundamental challenge in AI. Multimodal Large Language Models (MLLMs) have significantly advanced the reasoning capabilities of such agents through strong vision-language knowledge and chain-of-thought (CoT) reasoning, yet remain brittle when faced with challenging out-of-distribution scenarios. To address this, we propose Verifier-Guided Action Selection (VegAS), a test-time framework designed to improve the robustness of MLLM-based embodied agents through an explicit verification step. At inference time, rather than committing to a single decoded action, VeGAS samples an ensemble of candidate actions and uses a generative verifier to identify the most reliable choice, without modifying the underlying policy. Crucially, we find that using an MLLM off-the-shelf as a verifier yields no improvement, motivating our LLM-driven data synthesis strategy, which automatically constructs a diverse curriculum of failure cases to expose the verifier to a rich distribution of potential errors at training time. Across embodied reasoning benchmarks spanning the Habitat and ALFRED environments, VeGAS consistently improves generalization, achieving up to a 36% relative performance gain over strong CoT baselines on the most challenging multi-object, long-horizon tasks.
Bimanual Robot Manipulation via Multi-Agent In-Context Learning
Apr 22, 2026Language Models (LLMs) have emerged as powerful reasoning engines for embodied control. In particular, In-Context Learning (ICL) enables off-the-shelf, text-only LLMs to predict robot actions without any task-specific training while preserving their generalization capabilities. Applying ICL to bimanual manipulation remains challenging, as the high-dimensional joint action space and tight inter-arm coordination constraints rapidly overwhelm standard context windows. To address this, we introduce BiCICLe (Bimanual Coordinated In-Context Learning), the first framework that enables standard LLMs to perform few-shot bimanual manipulation without fine-tuning. BiCICLe frames bimanual control as a multi-agent leader-follower problem, decoupling the action space into sequential, conditioned single-arm predictions. This naturally extends to Arms' Debate, an iterative refinement process, and to the introduction of a third LLM-as-Judge to evaluate and select the most plausible coordinated trajectories. Evaluated on 13 tasks from the TWIN benchmark, BiCICLe achieves up to 71.1% average success rate, outperforming the best training-free baseline by 6.7 percentage points and surpassing most supervised methods. We further demonstrate strong few-shot generalization on novel tasks.
Whole-Body Mobile Manipulation using Offline Reinforcement Learning on Sub-optimal Controllers
Apr 14, 2026Mobile Manipulation (MoMa) of articulated objects, such as opening doors, drawers, and cupboards, demands simultaneous, whole-body coordination between a robot's base and arms. Classical whole-body controllers (WBCs) can solve such problems via hierarchical optimization, but require extensive hand-tuned optimization and remain brittle. Learning-based methods, on the other hand, show strong generalization capabilities but typically rely on expensive whole-body teleoperation data or heavy reward engineering. We observe that even a sub-optimal WBC is a powerful structural prior: it can be used to collect data in a constrained, task-relevant region of the state-action space, and its behavior can still be improved upon using offline reinforcement learning. Building on this, we propose WHOLE-MoMa, a two-stage pipeline that first generates diverse demonstrations by randomizing a lightweight WBC, and then applies offline RL to identify and stitch together improved behaviors via a reward signal. To support the expressive action-chunked diffusion policies needed for complex coordination tasks, we extend offline implicit Q-learning with Q-chunking for chunk-level critic evaluation and advantage-weighted policy extraction. On three tasks of increasing difficulty using a TIAGo++ mobile manipulator in simulation, WHOLE-MoMa significantly outperforms WBC, behavior cloning, and several offline RL baselines. Policies transfer directly to the real robot without finetuning, achieving 80% success in bimanual drawer manipulation and 68% in simultaneous cupboard opening and object placement, all without any teleoperated or real-world training data.
Task-Aware Bimanual Affordance Prediction via VLM-Guided Semantic-Geometric Reasoning
Apr 09, 2026Bimanual manipulation requires reasoning about where to interact with an object and which arm should perform each action, a joint affordance localization and arm allocation problem that geometry-only planners cannot resolve without semantic understanding of task intent. Existing approaches either treat affordance prediction as coarse part segmentation or rely on geometric heuristics for arm assignment, failing to jointly reason about task-relevant contact regions and arm allocation. We reframe bimanual manipulation as a joint affordance localization and arm allocation problem and propose a hierarchical framework for task-aware bimanual affordance prediction that leverages a Vision-Language Model (VLM) to generalize across object categories and task descriptions without requiring category-specific training. Our approach fuses multi-view RGB-D observations into a consistent 3D scene representation and generates global 6-DoF grasp candidates, which are then spatially and semantically filtered by querying the VLM for task-relevant affordance regions on each object, as well as for arm allocation to the individual objects, thereby ensuring geometric validity while respecting task semantics. We evaluate our method on a dual-arm platform across nine real-world manipulation tasks spanning four categories: parallel manipulation, coordinated stabilization, tool use, and human handover. Our approach achieves consistently higher task success rates than geometric and semantic baselines for task-oriented grasping, demonstrating that explicit semantic reasoning over affordances and arm allocation helps enable reliable bimanual manipulation in unstructured environments.
Learning Semantic-Geometric Task Graph-Representations from Human Demonstrations
Jan 16, 2026Learning structured task representations from human demonstrations is essential for understanding long-horizon manipulation behaviors, particularly in bimanual settings where action ordering, object involvement, and interaction geometry can vary significantly. A key challenge lies in jointly capturing the discrete semantic structure of tasks and the temporal evolution of object-centric geometric relations in a form that supports reasoning over task progression. In this work, we introduce a semantic-geometric task graph-representation that encodes object identities, inter-object relations, and their temporal geometric evolution from human demonstrations. Building on this formulation, we propose a learning framework that combines a Message Passing Neural Network (MPNN) encoder with a Transformer-based decoder, decoupling scene representation learning from action-conditioned reasoning about task progression. The encoder operates solely on temporal scene graphs to learn structured representations, while the decoder conditions on action-context to predict future action sequences, associated objects, and object motions over extended time horizons. Through extensive evaluation on human demonstration datasets, we show that semantic-geometric task graph-representations are particularly beneficial for tasks with high action and object variability, where simpler sequence-based models struggle to capture task progression. Finally, we demonstrate that task graph representations can be transferred to a physical bimanual robot and used for online action selection, highlighting their potential as reusable task abstractions for downstream decision-making in manipulation systems.
Self-Supervised Multisensory Pretraining for Contact-Rich Robot Reinforcement Learning
Nov 18, 2025
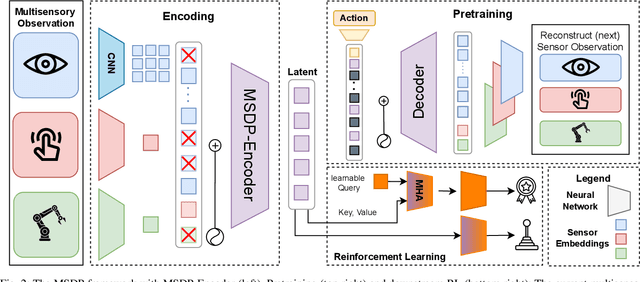
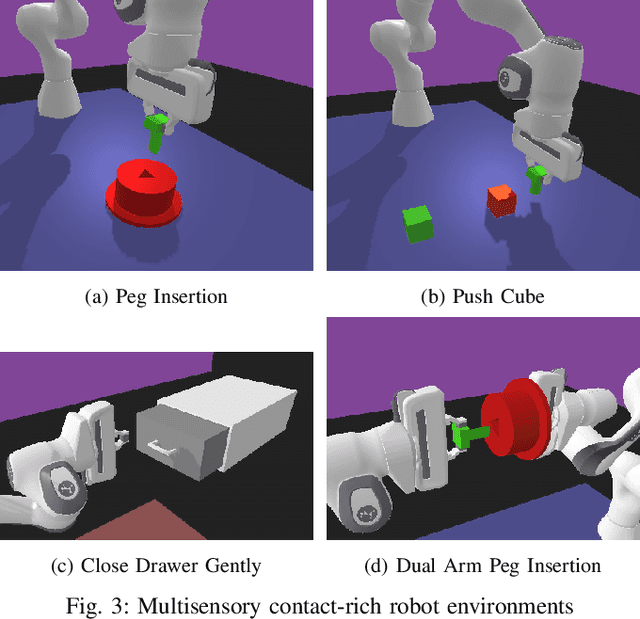
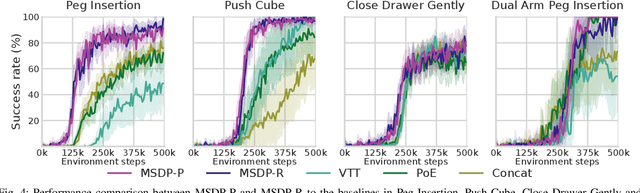
Effective contact-rich manipulation requires robots to synergistically leverage vision, force, and proprioception. However, Reinforcement Learning agents struggle to learn in such multisensory settings, especially amidst sensory noise and dynamic changes. We propose MultiSensory Dynamic Pretraining (MSDP), a novel framework for learning expressive multisensory representations tailored for task-oriented policy learning. MSDP is based on masked autoencoding and trains a transformer-based encoder by reconstructing multisensory observations from only a subset of sensor embeddings, leading to cross-modal prediction and sensor fusion. For downstream policy learning, we introduce a novel asymmetric architecture, where a cross-attention mechanism allows the critic to extract dynamic, task-specific features from the frozen embeddings, while the actor receives a stable pooled representation to guide its actions. Our method demonstrates accelerated learning and robust performance under diverse perturbations, including sensor noise, and changes in object dynamics. Evaluations in multiple challenging, contact-rich robot manipulation tasks in simulation and the real world showcase the effectiveness of MSDP. Our approach exhibits strong robustness to perturbations and achieves high success rates on the real robot with as few as 6,000 online interactions, offering a simple yet powerful solution for complex multisensory robotic control.
2HandedAfforder: Learning Precise Actionable Bimanual Affordances from Human Videos
Mar 13, 2025When interacting with objects, humans effectively reason about which regions of objects are viable for an intended action, i.e., the affordance regions of the object. They can also account for subtle differences in object regions based on the task to be performed and whether one or two hands need to be used. However, current vision-based affordance prediction methods often reduce the problem to naive object part segmentation. In this work, we propose a framework for extracting affordance data from human activity video datasets. Our extracted 2HANDS dataset contains precise object affordance region segmentations and affordance class-labels as narrations of the activity performed. The data also accounts for bimanual actions, i.e., two hands co-ordinating and interacting with one or more objects. We present a VLM-based affordance prediction model, 2HandedAfforder, trained on the dataset and demonstrate superior performance over baselines in affordance region segmentation for various activities. Finally, we show that our predicted affordance regions are actionable, i.e., can be used by an agent performing a task, through demonstration in robotic manipulation scenarios.