 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNautilus: From One Prompt to Plug-and-Play Robot Learning
May 12, 2026Robot learning research is fragmented across policy families, benchmark suites, and real robots; each implementation is entangled with the others in a complex combination matrix, making it an engineering nightmare to port any single element. General-purpose coding agents may occasionally bridge specific setups, but cannot close this gap at scale because they lack the procedural priors and validation practices that characterize robotics research workflows. We propose NAUTILUS, an open-source harness that turns a single user prompt -- for example, "Evaluate policy A with benchmark B" -- into ready-to-use reproduction, evaluation, fine-tuning, and deployment workflows. NAUTILUS provides: plug-and-play agent skill sets with distilled priors from robotics research; typed contracts among policies, simulators/benchmarks, and real-world robots; unified interfaces and execution environments; and a trustworthy agentic coding workflow with explicit, automated validation, and testing at each milestone. NAUTILUS can not only automatically generate the required adapters and containers for existing implementations, but also wrap and onboard new or user-provided policies, simulators/benchmarks, and robots, all connected via a uniform interface. This expands cross-validation coverage without hand-written glue code. Like a nautilus shell that grows by adding chambers, NAUTILUS scales by extending its execution in chambered units, making it a research harness for scalability rather than a hand-curated framework, and aiming to reduce the engineering burden of cross-family reproduction and evaluation in the ever-growing robot learning ecosystem.
Bimanual Robot Manipulation via Multi-Agent In-Context Learning
Apr 22, 2026Language Models (LLMs) have emerged as powerful reasoning engines for embodied control. In particular, In-Context Learning (ICL) enables off-the-shelf, text-only LLMs to predict robot actions without any task-specific training while preserving their generalization capabilities. Applying ICL to bimanual manipulation remains challenging, as the high-dimensional joint action space and tight inter-arm coordination constraints rapidly overwhelm standard context windows. To address this, we introduce BiCICLe (Bimanual Coordinated In-Context Learning), the first framework that enables standard LLMs to perform few-shot bimanual manipulation without fine-tuning. BiCICLe frames bimanual control as a multi-agent leader-follower problem, decoupling the action space into sequential, conditioned single-arm predictions. This naturally extends to Arms' Debate, an iterative refinement process, and to the introduction of a third LLM-as-Judge to evaluate and select the most plausible coordinated trajectories. Evaluated on 13 tasks from the TWIN benchmark, BiCICLe achieves up to 71.1% average success rate, outperforming the best training-free baseline by 6.7 percentage points and surpassing most supervised methods. We further demonstrate strong few-shot generalization on novel tasks.
Stein Variational Ergodic Surface Coverage with SE(3) Constraints
Mar 10, 2026Surface manipulation tasks require robots to generate trajectories that comprehensively cover complex 3D surfaces while maintaining precise end-effector poses. Existing ergodic trajectory optimization (TO) methods demonstrate success in coverage tasks, while struggling with point-cloud targets due to the nonconvex optimization landscapes and the inadequate handling of SE(3) constraints in sampling-as-optimization (SAO) techniques. In this work, we introduce a preconditioned SE(3) Stein Variational Gradient Descent (SVGD) approach for SAO ergodic trajectory generation. Our proposed approach comprises multiple innovations. First, we reformulate point-cloud ergodic coverage as a manifold-aware sampling problem. Second, we derive SE(3)-specific SVGD particle updates, and, third, we develop a preconditioner to accelerate TO convergence. Our sampling-based framework consistently identifies superior local optima compared to strong optimization-based and SAO baselines while preserving the SE(3) geometric structure. Experiments on a 3D point-cloud surface coverage benchmark and robotic surface drawing tasks demonstrate that our method achieves superior coverage quality with tractable computation in our setting relative to existing TO and SAO approaches, and is validated in real-world robot experiments.
Robot-DIFT: Distilling Diffusion Features for Geometrically Consistent Visuomotor Control
Feb 12, 2026We hypothesize that a key bottleneck in generalizable robot manipulation is not solely data scale or policy capacity, but a structural mismatch between current visual backbones and the physical requirements of closed-loop control. While state-of-the-art vision encoders (including those used in VLAs) optimize for semantic invariance to stabilize classification, manipulation typically demands geometric sensitivity the ability to map millimeter-level pose shifts to predictable feature changes. Their discriminative objective creates a "blind spot" for fine-grained control, whereas generative diffusion models inherently encode geometric dependencies within their latent manifolds, encouraging the preservation of dense multi-scale spatial structure. However, directly deploying stochastic diffusion features for control is hindered by stochastic instability, inference latency, and representation drift during fine-tuning. To bridge this gap, we propose Robot-DIFT, a framework that decouples the source of geometric information from the process of inference via Manifold Distillation. By distilling a frozen diffusion teacher into a deterministic Spatial-Semantic Feature Pyramid Network (S2-FPN), we retain the rich geometric priors of the generative model while ensuring temporal stability, real-time execution, and robustness against drift. Pretrained on the large-scale DROID dataset, Robot-DIFT demonstrates superior geometric consistency and control performance compared to leading discriminative baselines, supporting the view that how a model learns to see dictates how well it can learn to act.
Morphologically Symmetric Reinforcement Learning for Ambidextrous Bimanual Manipulation
May 08, 2025Humans naturally exhibit bilateral symmetry in their gross manipulation skills, effortlessly mirroring simple actions between left and right hands. Bimanual robots-which also feature bilateral symmetry-should similarly exploit this property to perform tasks with either hand. Unlike humans, who often favor a dominant hand for fine dexterous skills, robots should ideally execute ambidextrous manipulation with equal proficiency. To this end, we introduce SYMDEX (SYMmetric DEXterity), a reinforcement learning framework for ambidextrous bi-manipulation that leverages the robot's inherent bilateral symmetry as an inductive bias. SYMDEX decomposes complex bimanual manipulation tasks into per-hand subtasks and trains dedicated policies for each. By exploiting bilateral symmetry via equivariant neural networks, experience from one arm is inherently leveraged by the opposite arm. We then distill the subtask policies into a global ambidextrous policy that is independent of the hand-task assignment. We evaluate SYMDEX on six challenging simulated manipulation tasks and demonstrate successful real-world deployment on two of them. Our approach strongly outperforms baselines on complex task in which the left and right hands perform different roles. We further demonstrate SYMDEX's scalability by extending it to a four-arm manipulation setup, where our symmetry-aware policies enable effective multi-arm collaboration and coordination. Our results highlight how structural symmetry as inductive bias in policy learning enhances sample efficiency, robustness, and generalization across diverse dexterous manipulation tasks.
6DOPE-GS: Online 6D Object Pose Estimation using Gaussian Splatting
Dec 02, 2024Efficient and accurate object pose estimation is an essential component for modern vision systems in many applications such as Augmented Reality, autonomous driving, and robotics. While research in model-based 6D object pose estimation has delivered promising results, model-free methods are hindered by the high computational load in rendering and inferring consistent poses of arbitrary objects in a live RGB-D video stream. To address this issue, we present 6DOPE-GS, a novel method for online 6D object pose estimation \& tracking with a single RGB-D camera by effectively leveraging advances in Gaussian Splatting. Thanks to the fast differentiable rendering capabilities of Gaussian Splatting, 6DOPE-GS can simultaneously optimize for 6D object poses and 3D object reconstruction. To achieve the necessary efficiency and accuracy for live tracking, our method uses incremental 2D Gaussian Splatting with an intelligent dynamic keyframe selection procedure to achieve high spatial object coverage and prevent erroneous pose updates. We also propose an opacity statistic-based pruning mechanism for adaptive Gaussian density control, to ensure training stability and efficiency. We evaluate our method on the HO3D and YCBInEOAT datasets and show that 6DOPE-GS matches the performance of state-of-the-art baselines for model-free simultaneous 6D pose tracking and reconstruction while providing a 5$\times$ speedup. We also demonstrate the method's suitability for live, dynamic object tracking and reconstruction in a real-world setting.
CelebA-Spoof Challenge 2020 on Face Anti-Spoofing: Methods and Results
Feb 26, 2021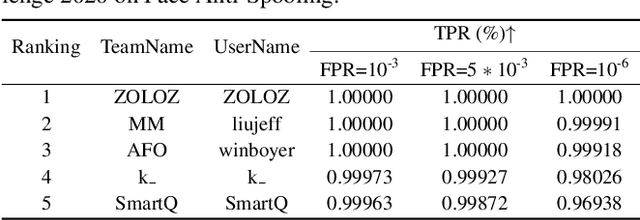
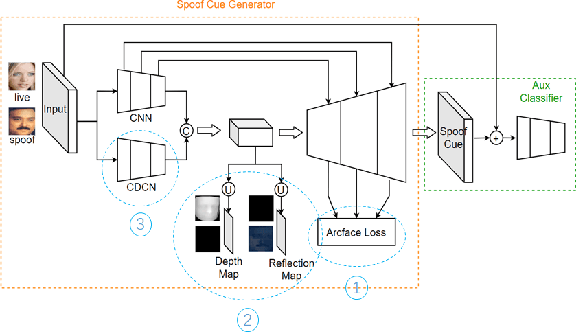
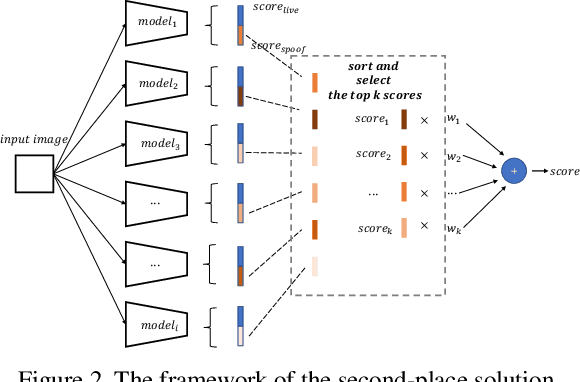
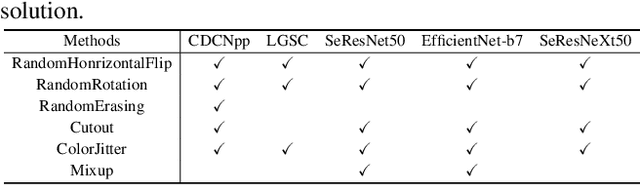
As facial interaction systems are prevalently deployed, security and reliability of these systems become a critical issue, with substantial research efforts devoted. Among them, face anti-spoofing emerges as an important area, whose objective is to identify whether a presented face is live or spoof. Recently, a large-scale face anti-spoofing dataset, CelebA-Spoof which comprised of 625,537 pictures of 10,177 subjects has been released. It is the largest face anti-spoofing dataset in terms of the numbers of the data and the subjects. This paper reports methods and results in the CelebA-Spoof Challenge 2020 on Face AntiSpoofing which employs the CelebA-Spoof dataset. The model evaluation is conducted online on the hidden test set. A total of 134 participants registered for the competition, and 19 teams made valid submissions. We will analyze the top ranked solutions and present some discussion on future work directions.