 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Dermatoscopic Lesion Segmentation via Diffusion Models with Visual and Textual Prompts
Oct 04, 2023



Image synthesis approaches, e.g., generative adversarial networks, have been popular as a form of data augmentation in medical image analysis tasks. It is primarily beneficial to overcome the shortage of publicly accessible data and associated quality annotations. However, the current techniques often lack control over the detailed contents in generated images, e.g., the type of disease patterns, the location of lesions, and attributes of the diagnosis. In this work, we adapt the latest advance in the generative model, i.e., the diffusion model, with the added control flow using lesion-specific visual and textual prompts for generating dermatoscopic images. We further demonstrate the advantage of our diffusion model-based framework over the classical generation models in both the image quality and boosting the segmentation performance on skin lesions. It can achieve a 9% increase in the SSIM image quality measure and an over 5% increase in Dice coefficients over the prior arts.
Early Detection and Localization of Pancreatic Cancer by Label-Free Tumor Synthesis
Aug 06, 2023



Early detection and localization of pancreatic cancer can increase the 5-year survival rate for patients from 8.5% to 20%. Artificial intelligence (AI) can potentially assist radiologists in detecting pancreatic tumors at an early stage. Training AI models require a vast number of annotated examples, but the availability of CT scans obtaining early-stage tumors is constrained. This is because early-stage tumors may not cause any symptoms, which can delay detection, and the tumors are relatively small and may be almost invisible to human eyes on CT scans. To address this issue, we develop a tumor synthesis method that can synthesize enormous examples of small pancreatic tumors in the healthy pancreas without the need for manual annotation. Our experiments demonstrate that the overall detection rate of pancreatic tumors, measured by Sensitivity and Specificity, achieved by AI trained on synthetic tumors is comparable to that of real tumors. More importantly, our method shows a much higher detection rate for small tumors. We further investigate the per-voxel segmentation performance of pancreatic tumors if AI is trained on a combination of CT scans with synthetic tumors and CT scans with annotated large tumors at an advanced stage. Finally, we show that synthetic tumors improve AI generalizability in tumor detection and localization when processing CT scans from different hospitals. Overall, our proposed tumor synthesis method has immense potential to improve the early detection of pancreatic cancer, leading to better patient outcomes.
Continual Learning for Abdominal Multi-Organ and Tumor Segmentation
Jun 01, 2023The ability to dynamically extend a model to new data and classes is critical for multiple organ and tumor segmentation. However, due to privacy regulations, accessing previous data and annotations can be problematic in the medical domain. This poses a significant barrier to preserving the high segmentation accuracy of the old classes when learning from new classes because of the catastrophic forgetting problem. In this paper, we first empirically demonstrate that simply using high-quality pseudo labels can fairly mitigate this problem in the setting of organ segmentation. Furthermore, we put forward an innovative architecture designed specifically for continuous organ and tumor segmentation, which incurs minimal computational overhead. Our proposed design involves replacing the conventional output layer with a suite of lightweight, class-specific heads, thereby offering the flexibility to accommodate newly emerging classes. These heads enable independent predictions for newly introduced and previously learned classes, effectively minimizing the impact of new classes on old ones during the course of continual learning. We further propose incorporating Contrastive Language-Image Pretraining (CLIP) embeddings into the organ-specific heads. These embeddings encapsulate the semantic information of each class, informed by extensive image-text co-training. The proposed method is evaluated on both in-house and public abdominal CT datasets under organ and tumor segmentation tasks. Empirical results suggest that the proposed design improves the segmentation performance of a baseline neural network on newly-introduced and previously-learned classes along the learning trajectory.
Annotating 8,000 Abdominal CT Volumes for Multi-Organ Segmentation in Three Weeks
May 16, 2023Annotating medical images, particularly for organ segmentation, is laborious and time-consuming. For example, annotating an abdominal organ requires an estimated rate of 30-60 minutes per CT volume based on the expertise of an annotator and the size, visibility, and complexity of the organ. Therefore, publicly available datasets for multi-organ segmentation are often limited in data size and organ diversity. This paper proposes a systematic and efficient method to expedite the annotation process for organ segmentation. We have created the largest multi-organ dataset (by far) with the spleen, liver, kidneys, stomach, gallbladder, pancreas, aorta, and IVC annotated in 8,448 CT volumes, equating to 3.2 million slices. The conventional annotation methods would take an experienced annotator up to 1,600 weeks (or roughly 30.8 years) to complete this task. In contrast, our annotation method has accomplished this task in three weeks (based on an 8-hour workday, five days a week) while maintaining a similar or even better annotation quality. This achievement is attributed to three unique properties of our method: (1) label bias reduction using multiple pre-trained segmentation models, (2) effective error detection in the model predictions, and (3) attention guidance for annotators to make corrections on the most salient errors. Furthermore, we summarize the taxonomy of common errors made by AI algorithms and annotators. This allows for continuous refinement of both AI and annotations and significantly reduces the annotation costs required to create large-scale datasets for a wider variety of medical imaging tasks.
TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings
Apr 20, 2023In response to innovations in machine learning (ML) models, production workloads changed radically and rapidly. TPU v4 is the fifth Google domain specific architecture (DSA) and its third supercomputer for such ML models. Optical circuit switches (OCSes) dynamically reconfigure its interconnect topology to improve scale, availability, utilization, modularity, deployment, security, power, and performance; users can pick a twisted 3D torus topology if desired. Much cheaper, lower power, and faster than Infiniband, OCSes and underlying optical components are <5% of system cost and <3% of system power. Each TPU v4 includes SparseCores, dataflow processors that accelerate models that rely on embeddings by 5x-7x yet use only 5% of die area and power. Deployed since 2020, TPU v4 outperforms TPU v3 by 2.1x and improves performance/Watt by 2.7x. The TPU v4 supercomputer is 4x larger at 4096 chips and thus ~10x faster overall, which along with OCS flexibility helps large language models. For similar sized systems, it is ~4.3x-4.5x faster than the Graphcore IPU Bow and is 1.2x-1.7x faster and uses 1.3x-1.9x less power than the Nvidia A100. TPU v4s inside the energy-optimized warehouse scale computers of Google Cloud use ~3x less energy and produce ~20x less CO2e than contemporary DSAs in a typical on-premise data center.
Label-Free Liver Tumor Segmentation
Mar 27, 2023



We demonstrate that AI models can accurately segment liver tumors without the need for manual annotation by using synthetic tumors in CT scans. Our synthetic tumors have two intriguing advantages: (I) realistic in shape and texture, which even medical professionals can confuse with real tumors; (II) effective for training AI models, which can perform liver tumor segmentation similarly to the model trained on real tumors -- this result is exciting because no existing work, using synthetic tumors only, has thus far reached a similar or even close performance to real tumors. This result also implies that manual efforts for annotating tumors voxel by voxel (which took years to create) can be significantly reduced in the future. Moreover, our synthetic tumors can automatically generate many examples of small (or even tiny) synthetic tumors and have the potential to improve the success rate of detecting small liver tumors, which is critical for detecting the early stages of cancer. In addition to enriching the training data, our synthesizing strategy also enables us to rigorously assess the AI robustness.
CLIP-Driven Universal Model for Organ Segmentation and Tumor Detection
Jan 06, 2023



An increasing number of public datasets have shown a marked clinical impact on assessing anatomical structures. However, each of the datasets is small, partially labeled, and rarely investigates severe tumor subjects. Moreover, current models are limited to segmenting specific organs/tumors, which can not be extended to novel domains and classes. To tackle these limitations, we introduce embedding learned from Contrastive Language-Image Pre-training (CLIP) to segmentation models, dubbed the CLIP-Driven Universal Model. The Universal Model can better segment 25 organs and 6 types of tumors by exploiting the semantic relationship between abdominal structures. The model is developed from an assembly of 14 datasets with 3,410 CT scans and evaluated on 6,162 external CT scans from 3 datasets. We achieve the state-of-the-art results on Beyond The Cranial Vault (BTCV). Compared with dataset-specific models, the Universal Model is computationally more efficient (6x faster), generalizes better to CT scans from varying sites, and shows stronger transfer learning performance on novel tasks. The design of CLIP embedding enables the Universal Model to be easily extended to new classes without catastrophically forgetting the previously learned classes.
Synthetic Tumors Make AI Segment Tumors Better
Oct 26, 2022

We develop a novel strategy to generate synthetic tumors. Unlike existing works, the tumors generated by our strategy have two intriguing advantages: (1) realistic in shape and texture, which even medical professionals can confuse with real tumors; (2) effective for AI model training, which can perform liver tumor segmentation similarly to a model trained on real tumors - this result is unprecedented because no existing work, using synthetic tumors only, has thus far reached a similar or even close performance to the model trained on real tumors. This result also implies that manual efforts for developing per-voxel annotation of tumors (which took years to create) can be considerably reduced for training AI models in the future. Moreover, our synthetic tumors have the potential to improve the success rate of small tumor detection by automatically generating enormous examples of small (or tiny) synthetic tumors.
Delving into Masked Autoencoders for Multi-Label Thorax Disease Classification
Oct 23, 2022Vision Transformer (ViT) has become one of the most popular neural architectures due to its great scalability, computational efficiency, and compelling performance in many vision tasks. However, ViT has shown inferior performance to Convolutional Neural Network (CNN) on medical tasks due to its data-hungry nature and the lack of annotated medical data. In this paper, we pre-train ViTs on 266,340 chest X-rays using Masked Autoencoders (MAE) which reconstruct missing pixels from a small part of each image. For comparison, CNNs are also pre-trained on the same 266,340 X-rays using advanced self-supervised methods (e.g., MoCo v2). The results show that our pre-trained ViT performs comparably (sometimes better) to the state-of-the-art CNN (DenseNet-121) for multi-label thorax disease classification. This performance is attributed to the strong recipes extracted from our empirical studies for pre-training and fine-tuning ViT. The pre-training recipe signifies that medical reconstruction requires a much smaller proportion of an image (10% vs. 25%) and a more moderate random resized crop range (0.5~1.0 vs. 0.2~1.0) compared with natural imaging. Furthermore, we remark that in-domain transfer learning is preferred whenever possible. The fine-tuning recipe discloses that layer-wise LR decay, RandAug magnitude, and DropPath rate are significant factors to consider. We hope that this study can direct future research on the application of Transformers to a larger variety of medical imaging tasks.
Making Your First Choice: To Address Cold Start Problem in Vision Active Learning
Oct 05, 2022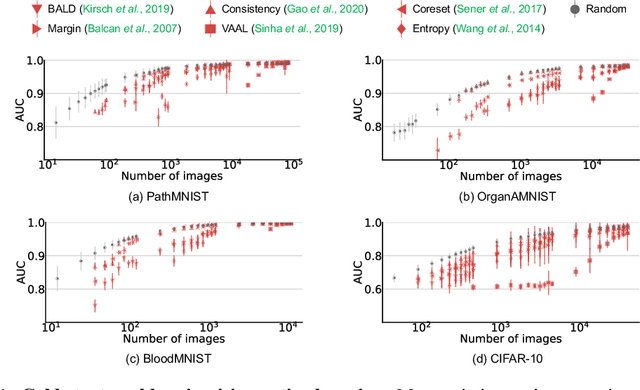
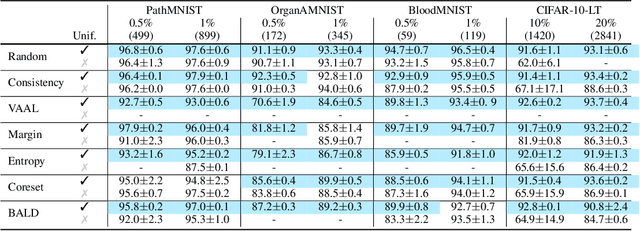
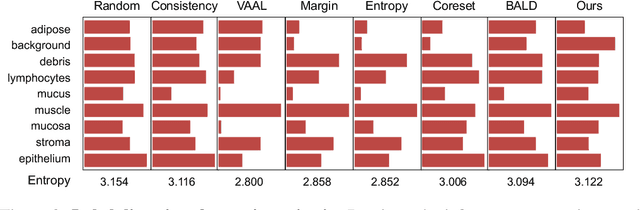
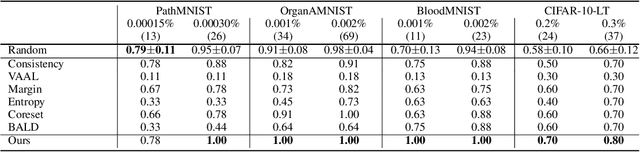
Active learning promises to improve annotation efficiency by iteratively selecting the most important data to be annotated first. However, we uncover a striking contradiction to this promise: active learning fails to select data as efficiently as random selection at the first few choices. We identify this as the cold start problem in vision active learning, caused by a biased and outlier initial query. This paper seeks to address the cold start problem by exploiting the three advantages of contrastive learning: (1) no annotation is required; (2) label diversity is ensured by pseudo-labels to mitigate bias; (3) typical data is determined by contrastive features to reduce outliers. Experiments are conducted on CIFAR-10-LT and three medical imaging datasets (i.e. Colon Pathology, Abdominal CT, and Blood Cell Microscope). Our initial query not only significantly outperforms existing active querying strategies but also surpasses random selection by a large margin. We foresee our solution to the cold start problem as a simple yet strong baseline to choose the initial query for vision active learning. Code is available: https://github.com/c-liangyu/CSVAL