 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
V-FAT: Benchmarking Visual Fidelity Against Text-bias
Jan 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive performance on standard visual reasoning benchmarks. However, there is growing concern that these models rely excessively on linguistic shortcuts rather than genuine visual grounding, a phenomenon we term Text Bias. In this paper, we investigate the fundamental tension between visual perception and linguistic priors. We decouple the sources of this bias into two dimensions: Internal Corpus Bias, stemming from statistical correlations in pretraining, and External Instruction Bias, arising from the alignment-induced tendency toward sycophancy. To quantify this effect, we introduce V-FAT (Visual Fidelity Against Text-bias), a diagnostic benchmark comprising 4,026 VQA instances across six semantic domains. V-FAT employs a Three-Level Evaluation Framework that systematically increases the conflict between visual evidence and textual information: (L1) internal bias from atypical images, (L2) external bias from misleading instructions, and (L3) synergistic bias where both coincide. We introduce the Visual Robustness Score (VRS), a metric designed to penalize "lucky" linguistic guesses and reward true visual fidelity. Our evaluation of 12 frontier MLLMs reveals that while models excel in existing benchmarks, they experience significant visual collapse under high linguistic dominance.
JoyVoice: Long-Context Conditioning for Anthropomorphic Multi-Speaker Conversational Synthesis
Dec 22, 2025Large speech generation models are evolving from single-speaker, short sentence synthesis to multi-speaker, long conversation geneartion. Current long-form speech generation models are predominately constrained to dyadic, turn-based interactions. To address this, we introduce JoyVoice, a novel anthropomorphic foundation model designed for flexible, boundary-free synthesis of up to eight speakers. Unlike conventional cascaded systems, JoyVoice employs a unified E2E-Transformer-DiT architecture that utilizes autoregressive hidden representations directly for diffusion inputs, enabling holistic end-to-end optimization. We further propose a MM-Tokenizer operating at a low bitrate of 12.5 Hz, which integrates multitask semantic and MMSE losses to effectively model both semantic and acoustic information. Additionally, the model incorporates robust text front-end processing via large-scale data perturbation. Experiments show that JoyVoice achieves state-of-the-art results in multilingual generation (Chinese, English, Japanese, Korean) and zero-shot voice cloning. JoyVoice achieves top-tier results on both the Seed-TTS-Eval Benchmark and multi-speaker long-form conversational voice cloning tasks, demonstrating superior audio quality and generalization. It achieves significant improvements in prosodic continuity for long-form speech, rhythm richness in multi-speaker conversations, paralinguistic naturalness, besides superior intelligibility. We encourage readers to listen to the demo at https://jea-speech.github.io/JoyVoice
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025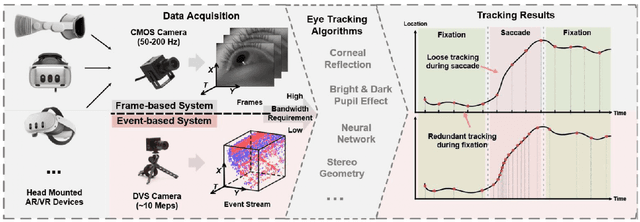
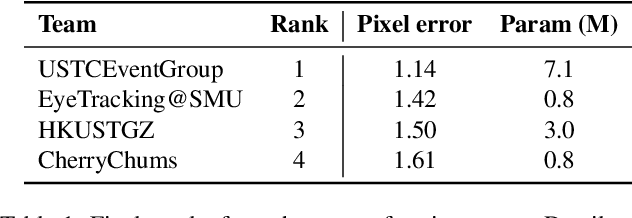
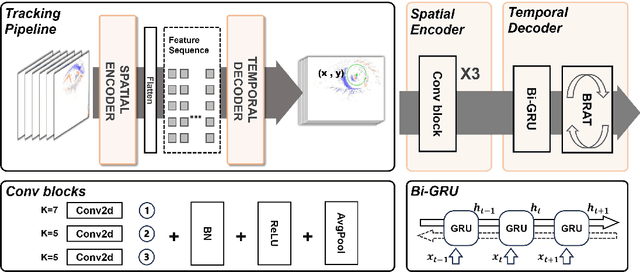

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
CRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
Dec 19, 2024



Sparsely activated Mixture-of-Experts (MoE) models are widely adopted to scale up model capacity without increasing the computation budget. However, vanilla TopK routers are trained in a discontinuous, non-differentiable way, limiting their performance and scalability. To address this issue, we propose ReMoE, a fully differentiable MoE architecture that offers a simple yet effective drop-in replacement for the conventional TopK+Softmax routing, utilizing ReLU as the router instead. We further propose methods to regulate the router's sparsity while balancing the load among experts. ReMoE's continuous nature enables efficient dynamic allocation of computation across tokens and layers, while also exhibiting domain specialization. Our experiments demonstrate that ReMoE consistently outperforms vanilla TopK-routed MoE across various model sizes, expert counts, and levels of granularity. Furthermore, ReMoE exhibits superior scalability with respect to the number of experts, surpassing traditional MoE architectures. The implementation based on Megatron-LM is available at https://github.com/thu-ml/ReMoE.
Efficient Backpropagation with Variance-Controlled Adaptive Sampling
Feb 27, 2024Sampling-based algorithms, which eliminate ''unimportant'' computations during forward and/or back propagation (BP), offer potential solutions to accelerate neural network training. However, since sampling introduces approximations to training, such algorithms may not consistently maintain accuracy across various tasks. In this work, we introduce a variance-controlled adaptive sampling (VCAS) method designed to accelerate BP. VCAS computes an unbiased stochastic gradient with fine-grained layerwise importance sampling in data dimension for activation gradient calculation and leverage score sampling in token dimension for weight gradient calculation. To preserve accuracy, we control the additional variance by learning the sample ratio jointly with model parameters during training. We assessed VCAS on multiple fine-tuning and pre-training tasks in both vision and natural language domains. On all the tasks, VCAS can preserve the original training loss trajectory and validation accuracy with an up to 73.87% FLOPs reduction of BP and 49.58% FLOPs reduction of the whole training process. The implementation is available at https://github.com/thu-ml/VCAS .
Joint Acoustic Echo Cancellation and Speech Dereverberation Using Kalman filters
Feb 09, 2023



This paper proposes a joint acoustic echo cancellation (AEC) and speech dereverberation (DR) algorithm in the short-time Fourier transform domain. The reverberant microphone signals are described using an auto-regressive (AR) model. The AR coefficients and the loudspeaker-to-microphone acoustic transfer functions (ATFs) are considered time-varying and are modeled simultaneously using a first-order Markov process. This leads to a solution where these parameters can be optimally estimated using Kalman filters. It is shown that the proposed algorithm outperforms vanilla solutions that solve AEC and DR sequentially and one state-of-the-art joint DRAEC algorithm based on semi-blind source separation, in terms of both speech quality and echo reduction performance.
Check and Link: Pairwise Lesion Correspondence Guides Mammogram Mass Detection
Sep 13, 2022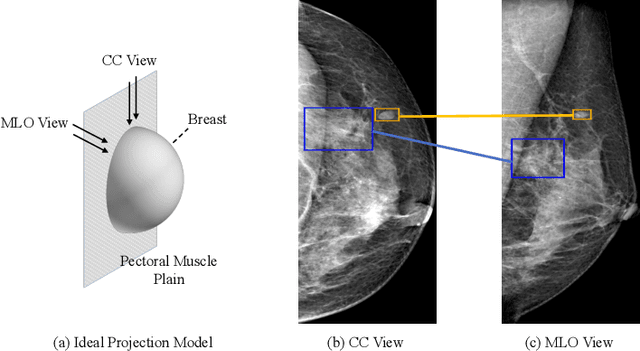
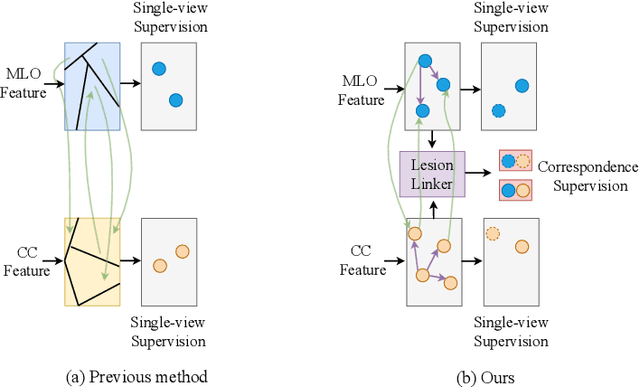
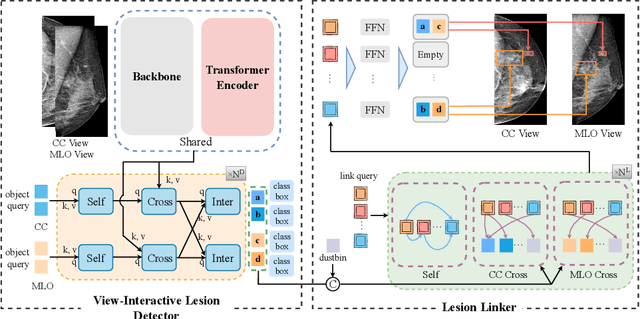
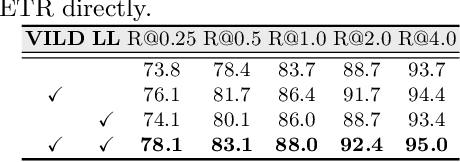
Detecting mass in mammogram is significant due to the high occurrence and mortality of breast cancer. In mammogram mass detection, modeling pairwise lesion correspondence explicitly is particularly important. However, most of the existing methods build relatively coarse correspondence and have not utilized correspondence supervision. In this paper, we propose a new transformer-based framework CL-Net to learn lesion detection and pairwise correspondence in an end-to-end manner. In CL-Net, View-Interactive Lesion Detector is proposed to achieve dynamic interaction across candidates of cross views, while Lesion Linker employs the correspondence supervision to guide the interaction process more accurately. The combination of these two designs accomplishes precise understanding of pairwise lesion correspondence for mammograms. Experiments show that CL-Net yields state-of-the-art performance on the public DDSM dataset and our in-house dataset. Moreover, it outperforms previous methods by a large margin in low FPI regime.
Personalized Acoustic Echo Cancellation for Full-duplex Communications
May 30, 2022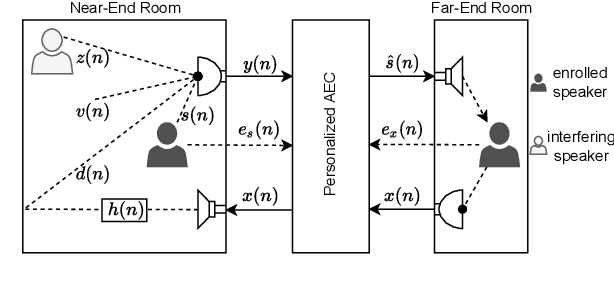

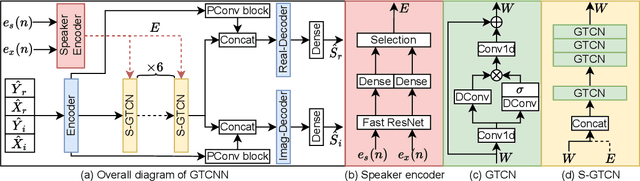
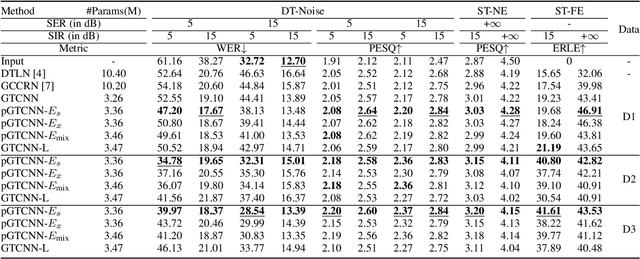
Deep neural networks (DNNs) have shown promising results for acoustic echo cancellation (AEC). But the DNN-based AEC models let through all near-end speakers including the interfering speech. In light of recent studies on personalized speech enhancement, we investigate the feasibility of personalized acoustic echo cancellation (PAEC) in this paper for full-duplex communications, where background noise and interfering speakers may coexist with acoustic echoes. Specifically, we first propose a novel backbone neural network termed as gated temporal convolutional neural network (GTCNN) that outperforms state-of-the-art AEC models in performance. Speaker embeddings like d-vectors are further adopted as auxiliary information to guide the GTCNN to focus on the target speaker. A special case in PAEC is that speech snippets of both parties on the call are enrolled. Experimental results show that auxiliary information from either the near-end speaker or the far-end speaker can improve the DNN-based AEC performance. Nevertheless, there is still much room for improvement in the utilization of the finite-dimensional speaker embeddings.