 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-FAT: Benchmarking Visual Fidelity Against Text-bias
Jan 08, 2026Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive performance on standard visual reasoning benchmarks. However, there is growing concern that these models rely excessively on linguistic shortcuts rather than genuine visual grounding, a phenomenon we term Text Bias. In this paper, we investigate the fundamental tension between visual perception and linguistic priors. We decouple the sources of this bias into two dimensions: Internal Corpus Bias, stemming from statistical correlations in pretraining, and External Instruction Bias, arising from the alignment-induced tendency toward sycophancy. To quantify this effect, we introduce V-FAT (Visual Fidelity Against Text-bias), a diagnostic benchmark comprising 4,026 VQA instances across six semantic domains. V-FAT employs a Three-Level Evaluation Framework that systematically increases the conflict between visual evidence and textual information: (L1) internal bias from atypical images, (L2) external bias from misleading instructions, and (L3) synergistic bias where both coincide. We introduce the Visual Robustness Score (VRS), a metric designed to penalize "lucky" linguistic guesses and reward true visual fidelity. Our evaluation of 12 frontier MLLMs reveals that while models excel in existing benchmarks, they experience significant visual collapse under high linguistic dominance.
Break Stylistic Sophon: Are We Really Meant to Confine the Imagination in Style Transfer?
Jun 18, 2025In this pioneering study, we introduce StyleWallfacer, a groundbreaking unified training and inference framework, which not only addresses various issues encountered in the style transfer process of traditional methods but also unifies the framework for different tasks. This framework is designed to revolutionize the field by enabling artist level style transfer and text driven stylization. First, we propose a semantic-based style injection method that uses BLIP to generate text descriptions strictly aligned with the semantics of the style image in CLIP space. By leveraging a large language model to remove style-related descriptions from these descriptions, we create a semantic gap. This gap is then used to fine-tune the model, enabling efficient and drift-free injection of style knowledge. Second, we propose a data augmentation strategy based on human feedback, incorporating high-quality samples generated early in the fine-tuning process into the training set to facilitate progressive learning and significantly reduce its overfitting. Finally, we design a training-free triple diffusion process using the fine-tuned model, which manipulates the features of self-attention layers in a manner similar to the cross-attention mechanism. Specifically, in the generation process, the key and value of the content-related process are replaced with those of the style-related process to inject style while maintaining text control over the model. We also introduce query preservation to mitigate disruptions to the original content. Under such a design, we have achieved high-quality image-driven style transfer and text-driven stylization, delivering artist-level style transfer results while preserving the original image content. Moreover, we achieve image color editing during the style transfer process for the first time.
EmoAgent: Multi-Agent Collaboration of Plan, Edit, and Critic, for Affective Image Manipulation
Mar 14, 2025



Affective Image Manipulation (AIM) aims to alter an image's emotional impact by adjusting multiple visual elements to evoke specific feelings.Effective AIM is inherently complex, necessitating a collaborative approach that involves identifying semantic cues within source images, manipulating these elements to elicit desired emotional responses, and verifying that the combined adjustments successfully evoke the target emotion.To address these challenges, we introduce EmoAgent, the first multi-agent collaboration framework for AIM. By emulating the cognitive behaviors of a human painter, EmoAgent incorporates three specialized agents responsible for planning, editing, and critical evaluation. Furthermore, we develop an emotion-factor knowledge retriever, a decision-making tree space, and a tool library to enhance EmoAgent's effectiveness in handling AIM. Experiments demonstrate that the proposed multi-agent framework outperforms existing methods, offering more reasonable and effective emotional expression.
M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
Nov 07, 2024



Document visual question answering (DocVQA) pipelines that answer questions from documents have broad applications. Existing methods focus on handling single-page documents with multi-modal language models (MLMs), or rely on text-based retrieval-augmented generation (RAG) that uses text extraction tools such as optical character recognition (OCR). However, there are difficulties in applying these methods in real-world scenarios: (a) questions often require information across different pages or documents, where MLMs cannot handle many long documents; (b) documents often have important information in visual elements such as figures, but text extraction tools ignore them. We introduce M3DocRAG, a novel multi-modal RAG framework that flexibly accommodates various document contexts (closed-domain and open-domain), question hops (single-hop and multi-hop), and evidence modalities (text, chart, figure, etc.). M3DocRAG finds relevant documents and answers questions using a multi-modal retriever and an MLM, so that it can efficiently handle single or many documents while preserving visual information. Since previous DocVQA datasets ask questions in the context of a specific document, we also present M3DocVQA, a new benchmark for evaluating open-domain DocVQA over 3,000+ PDF documents with 40,000+ pages. In three benchmarks (M3DocVQA/MMLongBench-Doc/MP-DocVQA), empirical results show that M3DocRAG with ColPali and Qwen2-VL 7B achieves superior performance than many strong baselines, including state-of-the-art performance in MP-DocVQA. We provide comprehensive analyses of different indexing, MLMs, and retrieval models. Lastly, we qualitatively show that M3DocRAG can successfully handle various scenarios, such as when relevant information exists across multiple pages and when answer evidence only exists in images.
GraphMamba: An Efficient Graph Structure Learning Vision Mamba for Hyperspectral Image Classification
Jul 11, 2024



Efficient extraction of spectral sequences and geospatial information has always been a hot topic in hyperspectral image classification. In terms of spectral sequence feature capture, RNN and Transformer have become mainstream classification frameworks due to their long-range feature capture capabilities. In terms of spatial information aggregation, CNN enhances the receptive field to retain integrated spatial information as much as possible. However, the spectral feature-capturing architectures exhibit low computational efficiency, and CNNs lack the flexibility to perceive spatial contextual information. To address these issues, this paper proposes GraphMamba--an efficient graph structure learning vision Mamba classification framework that fully considers HSI characteristics to achieve deep spatial-spectral information mining. Specifically, we propose a novel hyperspectral visual GraphMamba processing paradigm (HVGM) that preserves spatial-spectral features by constructing spatial-spectral cubes and utilizes linear spectral encoding to enhance the operability of subsequent tasks. The core components of GraphMamba include the HyperMamba module for improving computational efficiency and the SpectralGCN module for adaptive spatial context awareness. The HyperMamba mitigates clutter interference by employing the global mask (GM) and introduces a parallel training inference architecture to alleviate computational bottlenecks. The SpatialGCN incorporates weighted multi-hop aggregation (WMA) spatial encoding to focus on highly correlated spatial structural features, thus flexibly aggregating contextual information while mitigating spatial noise interference. Extensive experiments were conducted on three different scales of real HSI datasets, and compared with the state-of-the-art classification frameworks, GraphMamba achieved optimal performance.
Enhancing Question Answering on Charts Through Effective Pre-training Tasks
Jun 14, 2024



To completely understand a document, the use of textual information is not enough. Understanding visual cues, such as layouts and charts, is also required. While the current state-of-the-art approaches for document understanding (both OCR-based and OCR-free) work well, a thorough analysis of their capabilities and limitations has not yet been performed. Therefore, in this work, we addresses the limitation of current VisualQA models when applied to charts and plots. To investigate shortcomings of the state-of-the-art models, we conduct a comprehensive behavioral analysis, using ChartQA as a case study. Our findings indicate that existing models particularly underperform in answering questions related to the chart's structural and visual context, as well as numerical information. To address these issues, we propose three simple pre-training tasks that enforce the existing model in terms of both structural-visual knowledge, as well as its understanding of numerical questions. We evaluate our pre-trained model (called MatCha-v2) on three chart datasets - both extractive and abstractive question datasets - and observe that it achieves an average improvement of 1.7% over the baseline model.
Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning
May 23, 2024



RGB-D tracking significantly improves the accuracy of object tracking. However, its dependency on real depth inputs and the complexity involved in multi-modal fusion limit its applicability across various scenarios. The utilization of depth information in RGB-D tracking inspired us to propose a new method, named MDETrack, which trains a tracking network with an additional capability to understand the depth of scenes, through supervised or self-supervised auxiliary Monocular Depth Estimation learning. The outputs of MDETrack's unified feature extractor are fed to the side-by-side tracking head and auxiliary depth estimation head, respectively. The auxiliary module will be discarded in inference, thus keeping the same inference speed. We evaluated our models with various training strategies on multiple datasets, and the results show an improved tracking accuracy even without real depth. Through these findings we highlight the potential of depth estimation in enhancing object tracking performance.
TempTabQA: Temporal Question Answering for Semi-Structured Tables
Nov 14, 2023



Semi-structured data, such as Infobox tables, often include temporal information about entities, either implicitly or explicitly. Can current NLP systems reason about such information in semi-structured tables? To tackle this question, we introduce the task of temporal question answering on semi-structured tables. We present a dataset, TempTabQA, which comprises 11,454 question-answer pairs extracted from 1,208 Wikipedia Infobox tables spanning more than 90 distinct domains. Using this dataset, we evaluate several state-of-the-art models for temporal reasoning. We observe that even the top-performing LLMs lag behind human performance by more than 13.5 F1 points. Given these results, our dataset has the potential to serve as a challenging benchmark to improve the temporal reasoning capabilities of NLP models.
Anchor-Intermediate Detector: Decoupling and Coupling Bounding Boxes for Accurate Object Detection
Oct 09, 2023Anchor-based detectors have been continuously developed for object detection. However, the individual anchor box makes it difficult to predict the boundary's offset accurately. Instead of taking each bounding box as a closed individual, we consider using multiple boxes together to get prediction boxes. To this end, this paper proposes the \textbf{Box Decouple-Couple(BDC) strategy} in the inference, which no longer discards the overlapping boxes, but decouples the corner points of these boxes. Then, according to each corner's score, we couple the corner points to select the most accurate corner pairs. To meet the BDC strategy, a simple but novel model is designed named the \textbf{Anchor-Intermediate Detector(AID)}, which contains two head networks, i.e., an anchor-based head and an anchor-free \textbf{Corner-aware head}. The corner-aware head is able to score the corners of each bounding box to facilitate the coupling between corner points. Extensive experiments on MS COCO show that the proposed anchor-intermediate detector respectively outperforms their baseline RetinaNet and GFL method by $\sim$2.4 and $\sim$1.2 AP on the MS COCO test-dev dataset without any bells and whistles. Code is available at: https://github.com/YilongLv/AID.
Pedestrian-Robot Interactions on Autonomous Crowd Navigation: Reactive Control Methods and Evaluation Metrics
Aug 03, 2022
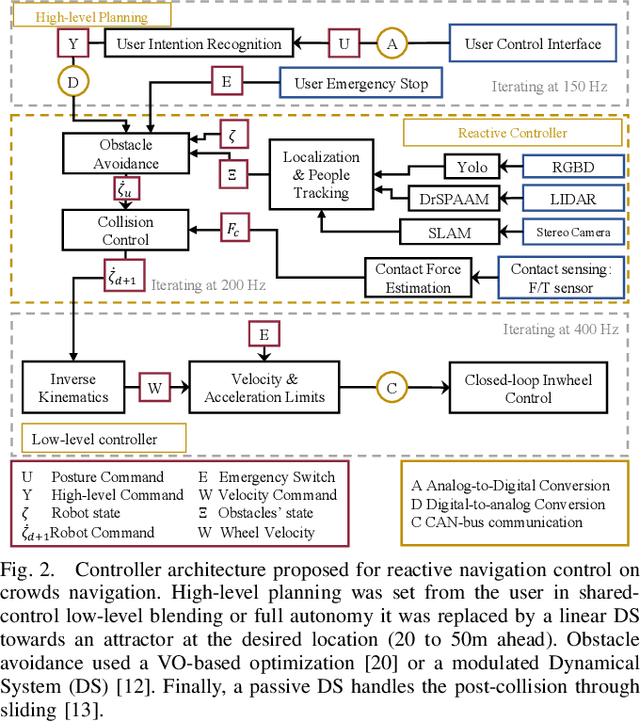
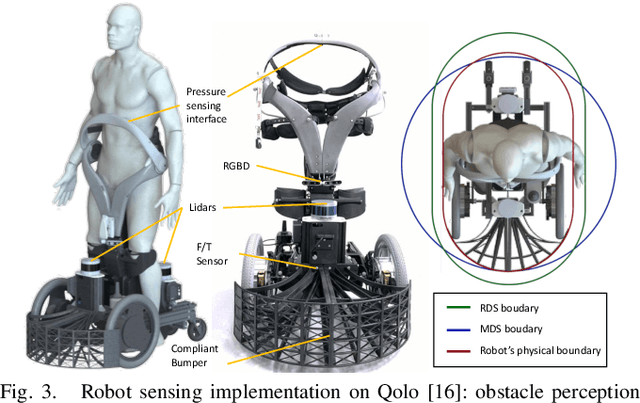
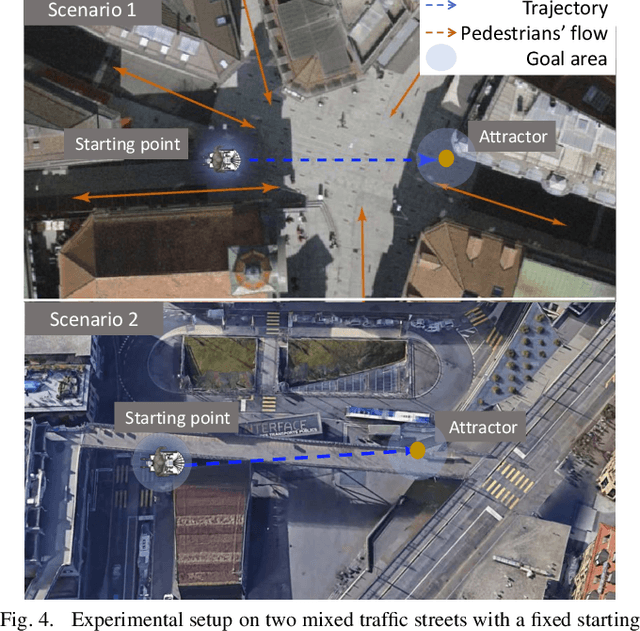
Autonomous navigation in highly populated areas remains a challenging task for robots because of the difficulty in guaranteeing safe interactions with pedestrians in unstructured situations. In this work, we present a crowd navigation control framework that delivers continuous obstacle avoidance and post-contact control evaluated on an autonomous personal mobility vehicle. We propose evaluation metrics for accounting efficiency, controller response and crowd interactions in natural crowds. We report the results of over 110 trials in different crowd types: sparse, flows, and mixed traffic, with low- (< 0.15 ppsm), mid- (< 0.65 ppsm), and high- (< 1 ppsm) pedestrian densities. We present comparative results between two low-level obstacle avoidance methods and a baseline of shared control. Results show a 10% drop in relative time to goal on the highest density tests, and no other efficiency metric decrease. Moreover, autonomous navigation showed to be comparable to shared-control navigation with a lower relative jerk and significantly higher fluency in commands indicating high compatibility with the crowd. We conclude that the reactive controller fulfils a necessary task of fast and continuous adaptation to crowd navigation, and it should be coupled with high-level planners for environmental and situational awareness.
* \c{opyright}IEEE All rights reserved. IEEE-IROS-2022, Oct.23-27. Kyoto, Japan