 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposure-Aware Beamforming for mmWave Systems: From EM Theory to Thermal Compliance
Jan 27, 2026Electromagnetic (EM) exposure compliance has long been recognized as a crucial aspect of communications terminal designs. However, accurately assessing the impact of EM exposure for proper design strategies remains challenging. In this paper, we develop a long-term thermal EM exposure constraint model and propose a novel adaptive exposure-aware beamforming design for an mmWave uplink system. Specifically, we first establish an equivalent channel model based on Maxwell's radiation equations, which accurately captures the EM physical effects. Then, we derive a closed-form thermal impulse response model from the Pennes bioheat transfer equation (BHTE), characterizing the thermal inertia of tissue. Inspired by this model, we formulate a beamforming optimization problem that translates rigid instantaneous exposure limits into a flexible long-term thermal budget constraint. Furthermore, we develop a low-complexity online beamforming algorithm based on Lyapunov optimization theory, obtaining a closed-form near-optimal solution. Simulation results demonstrate that the proposed algorithm effectively stabilizes tissue temperature near a predefined safety threshold and significantly outperforms the conventional scheme with instantaneous exposure constraints.
ReinforceGen: Hybrid Skill Policies with Automated Data Generation and Reinforcement Learning
Dec 18, 2025Long-horizon manipulation has been a long-standing challenge in the robotics community. We propose ReinforceGen, a system that combines task decomposition, data generation, imitation learning, and motion planning to form an initial solution, and improves each component through reinforcement-learning-based fine-tuning. ReinforceGen first segments the task into multiple localized skills, which are connected through motion planning. The skills and motion planning targets are trained with imitation learning on a dataset generated from 10 human demonstrations, and then fine-tuned through online adaptation and reinforcement learning. When benchmarked on the Robosuite dataset, ReinforceGen reaches 80% success rate on all tasks with visuomotor controls in the highest reset range setting. Additional ablation studies show that our fine-tuning approaches contributes to an 89% average performance increase. More results and videos available in https://reinforcegen.github.io/
DragFlow: Unleashing DiT Priors with Region Based Supervision for Drag Editing
Oct 02, 2025



Drag-based image editing has long suffered from distortions in the target region, largely because the priors of earlier base models, Stable Diffusion, are insufficient to project optimized latents back onto the natural image manifold. With the shift from UNet-based DDPMs to more scalable DiT with flow matching (e.g., SD3.5, FLUX), generative priors have become significantly stronger, enabling advances across diverse editing tasks. However, drag-based editing has yet to benefit from these stronger priors. This work proposes the first framework to effectively harness FLUX's rich prior for drag-based editing, dubbed DragFlow, achieving substantial gains over baselines. We first show that directly applying point-based drag editing to DiTs performs poorly: unlike the highly compressed features of UNets, DiT features are insufficiently structured to provide reliable guidance for point-wise motion supervision. To overcome this limitation, DragFlow introduces a region-based editing paradigm, where affine transformations enable richer and more consistent feature supervision. Additionally, we integrate pretrained open-domain personalization adapters (e.g., IP-Adapter) to enhance subject consistency, while preserving background fidelity through gradient mask-based hard constraints. Multimodal large language models (MLLMs) are further employed to resolve task ambiguities. For evaluation, we curate a novel Region-based Dragging benchmark (ReD Bench) featuring region-level dragging instructions. Extensive experiments on DragBench-DR and ReD Bench show that DragFlow surpasses both point-based and region-based baselines, setting a new state-of-the-art in drag-based image editing. Code and datasets will be publicly available upon publication.
SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025
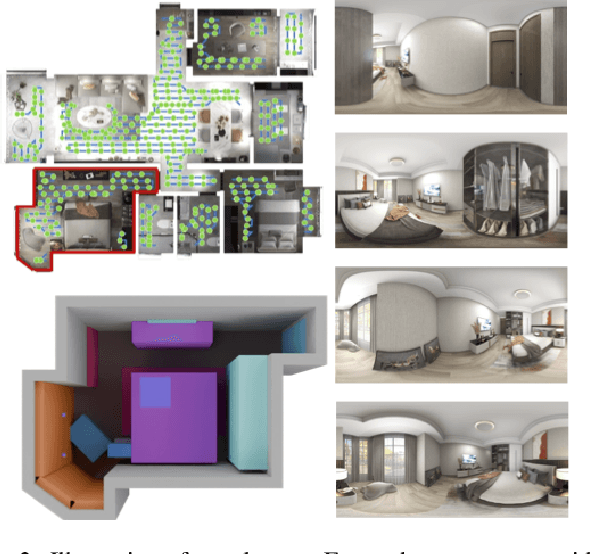
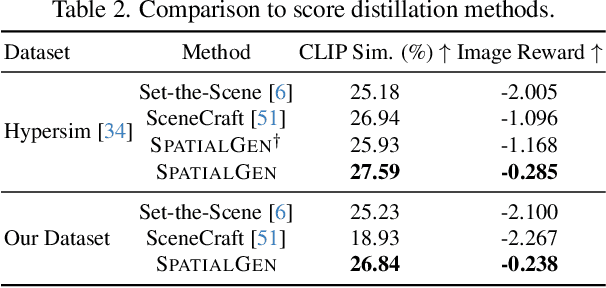
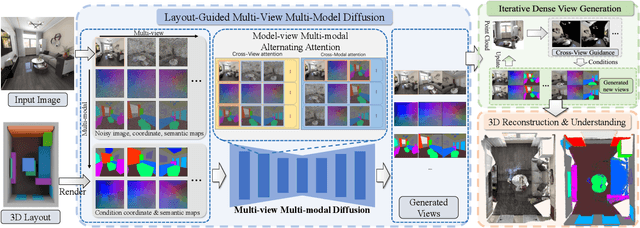
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.
SpatialLM: Training Large Language Models for Structured Indoor Modeling
Jun 09, 2025



SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Monocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
Enhancing Self-Supervised Fine-Grained Video Object Tracking with Dynamic Memory Prediction
Apr 30, 2025Successful video analysis relies on accurate recognition of pixels across frames, and frame reconstruction methods based on video correspondence learning are popular due to their efficiency. Existing frame reconstruction methods, while efficient, neglect the value of direct involvement of multiple reference frames for reconstruction and decision-making aspects, especially in complex situations such as occlusion or fast movement. In this paper, we introduce a Dynamic Memory Prediction (DMP) framework that innovatively utilizes multiple reference frames to concisely and directly enhance frame reconstruction. Its core component is a Reference Frame Memory Engine that dynamically selects frames based on object pixel features to improve tracking accuracy. In addition, a Bidirectional Target Prediction Network is built to utilize multiple reference frames to improve the robustness of the model. Through experiments, our algorithm outperforms the state-of-the-art self-supervised techniques on two fine-grained video object tracking tasks: object segmentation and keypoint tracking.
Computer-Aided Layout Generation for Building Design: A Review
Apr 13, 2025



Generating realistic building layouts for automatic building design has been studied in both the computer vision and architecture domains. Traditional approaches from the architecture domain, which are based on optimization techniques or heuristic design guidelines, can synthesize desirable layouts, but usually require post-processing and involve human interaction in the design pipeline, making them costly and timeconsuming. The advent of deep generative models has significantly improved the fidelity and diversity of the generated architecture layouts, reducing the workload by designers and making the process much more efficient. In this paper, we conduct a comprehensive review of three major research topics of architecture layout design and generation: floorplan layout generation, scene layout synthesis, and generation of some other formats of building layouts. For each topic, we present an overview of the leading paradigms, categorized either by research domains (architecture or machine learning) or by user input conditions or constraints. We then introduce the commonly-adopted benchmark datasets that are used to verify the effectiveness of the methods, as well as the corresponding evaluation metrics. Finally, we identify the well-solved problems and limitations of existing approaches, then propose new perspectives as promising directions for future research in this important research area. A project associated with this survey to maintain the resources is available at awesome-building-layout-generation.
Beyond Traditional Coherence Time: An Electromagnetic Perspective for Mobile Channels
Apr 03, 2025Channel coherence time has been widely regarded as a critical parameter in the design of mobile systems. However, a prominent challenge lies in integrating electromagnetic (EM) polarization effects into the derivation of the channel coherence time. In this paper, we develop a framework to analyze the impact of polarization mismatch on the channel coherence time. Specifically, we first establish an EM channel model to capture the essence of EM wave propagation. Based on this model, we then derive the EM temporal correlation function, incorporating the effects of polarization mismatch and beam misalignment. Further, considering the random orientation of the mobile user equipment (UE), we derive a closed-form solution for the EM coherence time in the turning scenario. When the trajectory degenerates into a straight line, we also provide a closed-form lower bound on the EM coherence time. The simulation results validate our theoretical analysis and reveal that neglecting the EM polarization effects leads to overly optimistic estimates of the EM coherence time.