 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Flow Policy: Simplifying diffusion$/$flow-matching policies by treating action trajectories as flow trajectories
May 28, 2025Recent advances in diffusion$/$flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories: a diffusion$/$flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion$/$flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. Project website: https://streaming-flow-policy.github.io/
DRRNet: Macro-Micro Feature Fusion and Dual Reverse Refinement for Camouflaged Object Detection
May 14, 2025



The core challenge in Camouflage Object Detection (COD) lies in the indistinguishable similarity between targets and backgrounds in terms of color, texture, and shape. This causes existing methods to either lose edge details (such as hair-like fine structures) due to over-reliance on global semantic information or be disturbed by similar backgrounds (such as vegetation patterns) when relying solely on local features. We propose DRRNet, a four-stage architecture characterized by a "context-detail-fusion-refinement" pipeline to address these issues. Specifically, we introduce an Omni-Context Feature Extraction Module to capture global camouflage patterns and a Local Detail Extraction Module to supplement microstructural information for the full-scene context module. We then design a module for forming dual representations of scene understanding and structural awareness, which fuses panoramic features and local features across various scales. In the decoder, we also introduce a reverse refinement module that leverages spatial edge priors and frequency-domain noise suppression to perform a two-stage inverse refinement of the output. By applying two successive rounds of inverse refinement, the model effectively suppresses background interference and enhances the continuity of object boundaries. Experimental results demonstrate that DRRNet significantly outperforms state-of-the-art methods on benchmark datasets. Our code is available at https://github.com/jerrySunning/DRRNet.
Enhancing Self-Supervised Fine-Grained Video Object Tracking with Dynamic Memory Prediction
Apr 30, 2025Successful video analysis relies on accurate recognition of pixels across frames, and frame reconstruction methods based on video correspondence learning are popular due to their efficiency. Existing frame reconstruction methods, while efficient, neglect the value of direct involvement of multiple reference frames for reconstruction and decision-making aspects, especially in complex situations such as occlusion or fast movement. In this paper, we introduce a Dynamic Memory Prediction (DMP) framework that innovatively utilizes multiple reference frames to concisely and directly enhance frame reconstruction. Its core component is a Reference Frame Memory Engine that dynamically selects frames based on object pixel features to improve tracking accuracy. In addition, a Bidirectional Target Prediction Network is built to utilize multiple reference frames to improve the robustness of the model. Through experiments, our algorithm outperforms the state-of-the-art self-supervised techniques on two fine-grained video object tracking tasks: object segmentation and keypoint tracking.
Knowledge Rectification for Camouflaged Object Detection: Unlocking Insights from Low-Quality Data
Mar 28, 2025Low-quality data often suffer from insufficient image details, introducing an extra implicit aspect of camouflage that complicates camouflaged object detection (COD). Existing COD methods focus primarily on high-quality data, overlooking the challenges posed by low-quality data, which leads to significant performance degradation. Therefore, we propose KRNet, the first framework explicitly designed for COD on low-quality data. KRNet presents a Leader-Follower framework where the Leader extracts dual gold-standard distributions: conditional and hybrid, from high-quality data to drive the Follower in rectifying knowledge learned from low-quality data. The framework further benefits from a cross-consistency strategy that improves the rectification of these distributions and a time-dependent conditional encoder that enriches the distribution diversity. Extensive experiments on benchmark datasets demonstrate that KRNet outperforms state-of-the-art COD methods and super-resolution-assisted COD approaches, proving its effectiveness in tackling the challenges of low-quality data in COD.
Leveraging Motion Information for Better Self-Supervised Video Correspondence Learning
Mar 15, 2025Self-supervised video correspondence learning depends on the ability to accurately associate pixels between video frames that correspond to the same visual object. However, achieving reliable pixel matching without supervision remains a major challenge. To address this issue, recent research has focused on feature learning techniques that aim to encode unique pixel representations for matching. Despite these advances, existing methods still struggle to achieve exact pixel correspondences and often suffer from false matches, limiting their effectiveness in self-supervised settings. To this end, we explore an efficient self-supervised Video Correspondence Learning framework (MER) that aims to accurately extract object details from unlabeled videos. First, we design a dedicated Motion Enhancement Engine that emphasizes capturing the dynamic motion of objects in videos. In addition, we introduce a flexible sampling strategy for inter-pixel correspondence information (Multi-Cluster Sampler) that enables the model to pay more attention to the pixel changes of important objects in motion. Through experiments, our algorithm outperforms the state-of-the-art competitors on video correspondence learning tasks such as video object segmentation and video object keypoint tracking.
Keypoint Abstraction using Large Models for Object-Relative Imitation Learning
Oct 30, 2024



Generalization to novel object configurations and instances across diverse tasks and environments is a critical challenge in robotics. Keypoint-based representations have been proven effective as a succinct representation for capturing essential object features, and for establishing a reference frame in action prediction, enabling data-efficient learning of robot skills. However, their manual design nature and reliance on additional human labels limit their scalability. In this paper, we propose KALM, a framework that leverages large pre-trained vision-language models (LMs) to automatically generate task-relevant and cross-instance consistent keypoints. KALM distills robust and consistent keypoints across views and objects by generating proposals using LMs and verifies them against a small set of robot demonstration data. Based on the generated keypoints, we can train keypoint-conditioned policy models that predict actions in keypoint-centric frames, enabling robots to generalize effectively across varying object poses, camera views, and object instances with similar functional shapes. Our method demonstrates strong performance in the real world, adapting to different tasks and environments from only a handful of demonstrations while requiring no additional labels. Website: https://kalm-il.github.io/
Embodied Uncertainty-Aware Object Segmentation
Aug 08, 2024We introduce uncertainty-aware object instance segmentation (UncOS) and demonstrate its usefulness for embodied interactive segmentation. To deal with uncertainty in robot perception, we propose a method for generating a hypothesis distribution of object segmentation. We obtain a set of region-factored segmentation hypotheses together with confidence estimates by making multiple queries of large pre-trained models. This process can produce segmentation results that achieve state-of-the-art performance on unseen object segmentation problems. The output can also serve as input to a belief-driven process for selecting robot actions to perturb the scene to reduce ambiguity. We demonstrate the effectiveness of this method in real-robot experiments. Website: https://sites.google.com/view/embodied-uncertain-seg
DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability
Jun 22, 2023



Task and Motion Planning (TAMP) approaches are effective at planning long-horizon autonomous robot manipulation. However, because they require a planning model, it can be difficult to apply them to domains where the environment and its dynamics are not fully known. We propose to overcome these limitations by leveraging deep generative modeling, specifically diffusion models, to learn constraints and samplers that capture these difficult-to-engineer aspects of the planning model. These learned samplers are composed and combined within a TAMP solver in order to find action parameter values jointly that satisfy the constraints along a plan. To tractably make predictions for unseen objects in the environment, we define these samplers on low-dimensional learned latent embeddings of changing object state. We evaluate our approach in an articulated object manipulation domain and show how the combination of classical TAMP, generative learning, and latent embeddings enables long-horizon constraint-based reasoning.
Long-Horizon Manipulation of Unknown Objects via Task and Motion Planning with Estimated Affordances
Aug 10, 2021
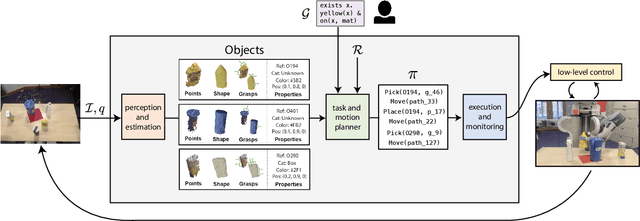


We present a strategy for designing and building very general robot manipulation systems involving the integration of a general-purpose task-and-motion planner with engineered and learned perception modules that estimate properties and affordances of unknown objects. Such systems are closed-loop policies that map from RGB images, depth images, and robot joint encoder measurements to robot joint position commands. We show that following this strategy a task-and-motion planner can be used to plan intelligent behaviors even in the absence of a priori knowledge regarding the set of manipulable objects, their geometries, and their affordances. We explore several different ways of implementing such perceptual modules for segmentation, property detection, shape estimation, and grasp generation. We show how these modules are integrated within the PDDLStream task and motion planning framework. Finally, we demonstrate that this strategy can enable a single system to perform a wide variety of real-world multi-step manipulation tasks, generalizing over a broad class of objects, object arrangements, and goals, without any prior knowledge of the environment and without re-training.
Learning Cycle-Consistent Cooperative Networks via Alternating MCMC Teaching for Unsupervised Cross-Domain Translation
Mar 07, 2021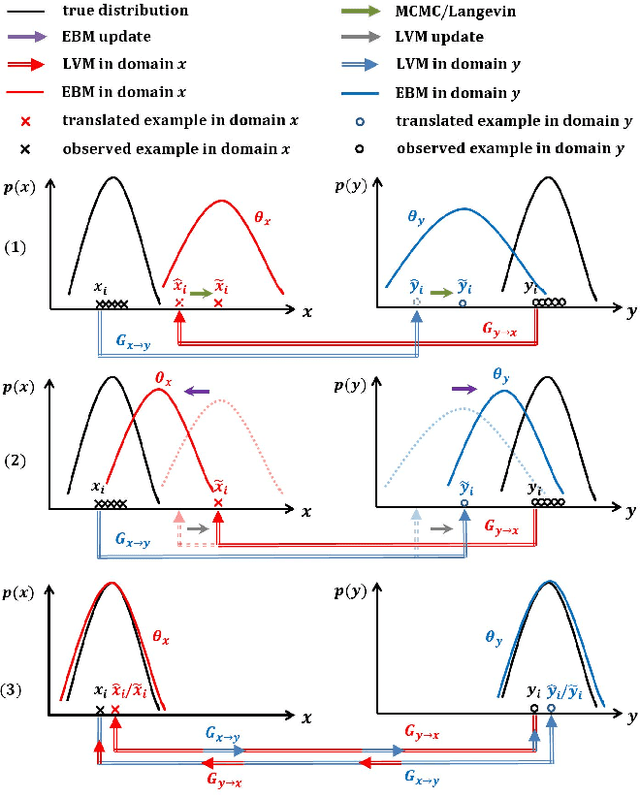
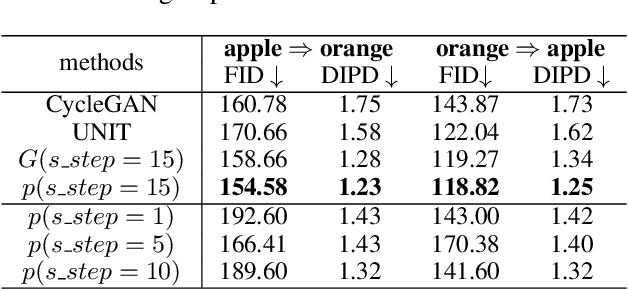

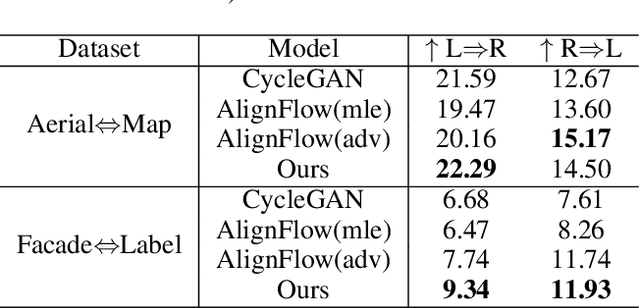
This paper studies the unsupervised cross-domain translation problem by proposing a generative framework, in which the probability distribution of each domain is represented by a generative cooperative network that consists of an energy-based model and a latent variable model. The use of generative cooperative network enables maximum likelihood learning of the domain model by MCMC teaching, where the energy-based model seeks to fit the data distribution of domain and distills its knowledge to the latent variable model via MCMC. Specifically, in the MCMC teaching process, the latent variable model parameterized by an encoder-decoder maps examples from the source domain to the target domain, while the energy-based model further refines the mapped results by Langevin revision such that the revised results match to the examples in the target domain in terms of the statistical properties, which are defined by the learned energy function. For the purpose of building up a correspondence between two unpaired domains, the proposed framework simultaneously learns a pair of cooperative networks with cycle consistency, accounting for a two-way translation between two domains, by alternating MCMC teaching. Experiments show that the proposed framework is useful for unsupervised image-to-image translation and unpaired image sequence translation.