 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Structural Bias in Graph Adversarial Defenses
Apr 29, 2025In recent years, graph neural networks (GNNs) have shown great potential in addressing various graph structure-related downstream tasks. However, recent studies have found that current GNNs are susceptible to malicious adversarial attacks. Given the inevitable presence of adversarial attacks in the real world, a variety of defense methods have been proposed to counter these attacks and enhance the robustness of GNNs. Despite the commendable performance of these defense methods, we have observed that they tend to exhibit a structural bias in terms of their defense capability on nodes with low degree (i.e., tail nodes), which is similar to the structural bias of traditional GNNs on nodes with low degree in the clean graph. Therefore, in this work, we propose a defense strategy by including hetero-homo augmented graph construction, $k$NN augmented graph construction, and multi-view node-wise attention modules to mitigate the structural bias of GNNs against adversarial attacks. Notably, the hetero-homo augmented graph consists of removing heterophilic links (i.e., links connecting nodes with dissimilar features) globally and adding homophilic links (i.e., links connecting nodes with similar features) for nodes with low degree. To further enhance the defense capability, an attention mechanism is adopted to adaptively combine the representations from the above two kinds of graph views. We conduct extensive experiments to demonstrate the defense and debiasing effect of the proposed strategy on benchmark datasets.
GT-SVQ: A Linear-Time Graph Transformer for Node Classification Using Spiking Vector Quantization
Apr 16, 2025Graph Transformers (GTs), which simultaneously integrate message-passing and self-attention mechanisms, have achieved promising empirical results in some graph prediction tasks. Although these approaches show the potential of Transformers in capturing long-range graph topology information, issues concerning the quadratic complexity and high computing energy consumption severely limit the scalability of GTs on large-scale graphs. Recently, as brain-inspired neural networks, Spiking Neural Networks (SNNs), facilitate the development of graph representation learning methods with lower computational and storage overhead through the unique event-driven spiking neurons. Inspired by these characteristics, we propose a linear-time Graph Transformer using Spiking Vector Quantization (GT-SVQ) for node classification. GT-SVQ reconstructs codebooks based on rate coding outputs from spiking neurons, and injects the codebooks into self-attention blocks to aggregate global information in linear complexity. Besides, spiking vector quantization effectively alleviates codebook collapse and the reliance on complex machinery (distance measure, auxiliary loss, etc.) present in previous vector quantization-based graph learning methods. In experiments, we compare GT-SVQ with other state-of-the-art baselines on node classification datasets ranging from small to large. Experimental results show that GT-SVQ has achieved competitive performances on most datasets while maintaining up to 130x faster inference speed compared to other GTs.
Towards an Understanding of Context Utilization in Code Intelligence
Apr 11, 2025Code intelligence is an emerging domain in software engineering, aiming to improve the effectiveness and efficiency of various code-related tasks. Recent research suggests that incorporating contextual information beyond the basic original task inputs (i.e., source code) can substantially enhance model performance. Such contextual signals may be obtained directly or indirectly from sources such as API documentation or intermediate representations like abstract syntax trees can significantly improve the effectiveness of code intelligence. Despite growing academic interest, there is a lack of systematic analysis of context in code intelligence. To address this gap, we conduct an extensive literature review of 146 relevant studies published between September 2007 and August 2024. Our investigation yields four main contributions. (1) A quantitative analysis of the research landscape, including publication trends, venues, and the explored domains; (2) A novel taxonomy of context types used in code intelligence; (3) A task-oriented analysis investigating context integration strategies across diverse code intelligence tasks; (4) A critical evaluation of evaluation methodologies for context-aware methods. Based on these findings, we identify fundamental challenges in context utilization in current code intelligence systems and propose a research roadmap that outlines key opportunities for future research.
BACE-RUL: A Bi-directional Adversarial Network with Covariate Encoding for Machine Remaining Useful Life Prediction
Mar 14, 2025Prognostic and Health Management (PHM) are crucial ways to avoid unnecessary maintenance for Cyber-Physical Systems (CPS) and improve system reliability. Predicting the Remaining Useful Life (RUL) is one of the most challenging tasks for PHM. Existing methods require prior knowledge about the system, contrived assumptions, or temporal mining to model the life cycles of machine equipment/devices, resulting in diminished accuracy and limited applicability in real-world scenarios. This paper proposes a Bi-directional Adversarial network with Covariate Encoding for machine Remaining Useful Life (BACE-RUL) prediction, which only adopts sensor measurements from the current life cycle to predict RUL rather than relying on previous consecutive cycle recordings. The current sensor measurements of mechanical devices are encoded to a conditional space to better understand the implicit inner mechanical status. The predictor is trained as a conditional generative network with the encoded sensor measurements as its conditions. Various experiments on several real-world datasets, including the turbofan aircraft engine dataset and the dataset collected from degradation experiments of Li-Ion battery cells, show that the proposed model is a general framework and outperforms state-of-the-art methods.
Are Large Language Models In-Context Graph Learners?
Feb 19, 2025



Large language models (LLMs) have demonstrated remarkable in-context reasoning capabilities across a wide range of tasks, particularly with unstructured inputs such as language or images. However, LLMs struggle to handle structured data, such as graphs, due to their lack of understanding of non-Euclidean structures. As a result, without additional fine-tuning, their performance significantly lags behind that of graph neural networks (GNNs) in graph learning tasks. In this paper, we show that learning on graph data can be conceptualized as a retrieval-augmented generation (RAG) process, where specific instances (e.g., nodes or edges) act as queries, and the graph itself serves as the retrieved context. Building on this insight, we propose a series of RAG frameworks to enhance the in-context learning capabilities of LLMs for graph learning tasks. Comprehensive evaluations demonstrate that our proposed RAG frameworks significantly improve LLM performance on graph-based tasks, particularly in scenarios where a pretrained LLM must be used without modification or accessed via an API.
Accurate Expert Predictions in MoE Inference via Cross-Layer Gate
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive performance across various tasks, and their application in edge scenarios has attracted significant attention. However, sparse-activated Mixture-of-Experts (MoE) models, which are well suited for edge scenarios, have received relatively little attention due to their high memory demands. Offload-based methods have been proposed to address this challenge, but they face difficulties with expert prediction. Inaccurate expert predictions can result in prolonged inference delays. To promote the application of MoE models in edge scenarios, we propose Fate, an offloading system designed for MoE models to enable efficient inference in resource-constrained environments. The key insight behind Fate is that gate inputs from adjacent layers can be effectively used for expert prefetching, achieving high prediction accuracy without additional GPU overhead. Furthermore, Fate employs a shallow-favoring expert caching strategy that increases the expert hit rate to 99\%. Additionally, Fate integrates tailored quantization strategies for cache optimization and IO efficiency. Experimental results show that, compared to Load on Demand and Expert Activation Path-based method, Fate achieves up to 4.5x and 1.9x speedups in prefill speed and up to 4.1x and 2.2x speedups in decoding speed, respectively, while maintaining inference quality. Moreover, Fate's performance improvements are scalable across different memory budgets.
Measuring Diversity in Synthetic Datasets
Feb 12, 2025Large language models (LLMs) are widely adopted to generate synthetic datasets for various natural language processing (NLP) tasks, such as text classification and summarization. However, accurately measuring the diversity of these synthetic datasets-an aspect crucial for robust model performance-remains a significant challenge. In this paper, we introduce DCScore, a novel method for measuring synthetic dataset diversity from a classification perspective. Specifically, DCScore formulates diversity evaluation as a sample classification task, leveraging mutual relationships among samples. We further provide theoretical verification of the diversity-related axioms satisfied by DCScore, highlighting its role as a principled diversity evaluation method. Experimental results on synthetic datasets reveal that DCScore enjoys a stronger correlation with multiple diversity pseudo-truths of evaluated datasets, underscoring its effectiveness. Moreover, both empirical and theoretical evidence demonstrate that DCScore substantially reduces computational costs compared to existing approaches. Code is available at: https://github.com/BlueWhaleLab/DCScore.
Klotski: Efficient Mixture-of-Expert Inference via Expert-Aware Multi-Batch Pipeline
Feb 09, 2025



Mixture of Experts (MoE), with its distinctive sparse structure, enables the scaling of language models up to trillions of parameters without significantly increasing computational costs. However, the substantial parameter size presents a challenge for inference, as the expansion in GPU memory cannot keep pace with the growth in parameters. Although offloading techniques utilise memory from the CPU and disk and parallelise the I/O and computation for efficiency, the computation for each expert in MoE models is often less than the I/O, resulting in numerous bubbles in the pipeline. Therefore, we propose Klotski, an efficient MoE inference engine that significantly reduces pipeline bubbles through a novel expert-aware multi-batch pipeline paradigm. The proposed paradigm uses batch processing to extend the computation time of the current layer to overlap with the loading time of the next layer. Although this idea has been effectively applied to dense models, more batches may activate more experts in the MoE, leading to longer loading times and more bubbles. Thus, unlike traditional approaches, we balance computation and I/O time and minimise bubbles by orchestrating their inference orders based on their heterogeneous computation and I/O requirements and activation patterns under different batch numbers. Moreover, to adapt to different hardware environments and models, we design a constraint-sensitive I/O-compute planner and a correlation-aware expert prefetcher for a schedule that minimises pipeline bubbles. Experimental results demonstrate that Klotski achieves a superior throughput-latency trade-off compared to state-of-the-art techniques, with throughput improvements of up to 85.12x.
How Should I Build A Benchmark?
Jan 18, 2025Various benchmarks have been proposed to assess the performance of large language models (LLMs) in different coding scenarios. We refer to them as code-related benchmarks. However, there are no systematic guidelines by which such a benchmark should be developed to ensure its quality, reliability, and reproducibility. We propose How2Bench, which is comprised of a 55- 55-criteria checklist as a set of guidelines to govern the development of code-related benchmarks comprehensively. Using HOW2BENCH, we profiled 274 benchmarks released within the past decade and found concerning issues. Nearly 70% of the benchmarks did not take measures for data quality assurance; over 10% did not even open source or only partially open source. Many highly cited benchmarks have loopholes, including duplicated samples, incorrect reference codes/tests/prompts, and unremoved sensitive/confidential information. Finally, we conducted a human study involving 49 participants, which revealed significant gaps in awareness of the importance of data quality, reproducibility, and transparency.
LicenseGPT: A Fine-tuned Foundation Model for Publicly Available Dataset License Compliance
Dec 30, 2024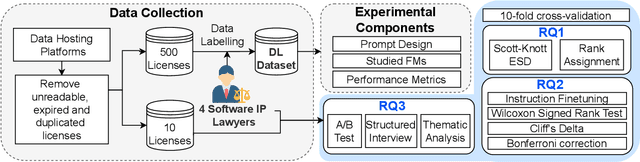
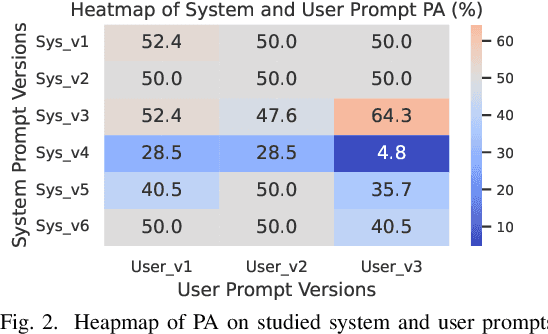

Dataset license compliance is a critical yet complex aspect of developing commercial AI products, particularly with the increasing use of publicly available datasets. Ambiguities in dataset licenses pose significant legal risks, making it challenging even for software IP lawyers to accurately interpret rights and obligations. In this paper, we introduce LicenseGPT, a fine-tuned foundation model (FM) specifically designed for dataset license compliance analysis. We first evaluate existing legal FMs (i.e., FMs specialized in understanding and processing legal texts) and find that the best-performing model achieves a Prediction Agreement (PA) of only 43.75%. LicenseGPT, fine-tuned on a curated dataset of 500 licenses annotated by legal experts, significantly improves PA to 64.30%, outperforming both legal and general-purpose FMs. Through an A/B test and user study with software IP lawyers, we demonstrate that LicenseGPT reduces analysis time by 94.44%, from 108 seconds to 6 seconds per license, without compromising accuracy. Software IP lawyers perceive LicenseGPT as a valuable supplementary tool that enhances efficiency while acknowledging the need for human oversight in complex cases. Our work underscores the potential of specialized AI tools in legal practice and offers a publicly available resource for practitioners and researchers.