 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit, But Verify: An Empirical Audit of Instructed Code-Editing Benchmarks
Apr 06, 2026Instructed code editing, where an LLM modifies existing code based on a natural language instruction, accounts for roughly 19% of real-world coding assistant interactions. Yet very few benchmarks directly evaluate this capability. From a survey of over 150 code-related benchmarks, we find that only two, CanItEdit and EDIT-Bench, target instructed code editing with human-authored instructions and test-based evaluation. We audit both by comparing their programming languages, edit intents, and application domains against distributions observed in the wild (Copilot Arena, AIDev, GitHub Octoverse), and by measuring test counts, statement coverage, and test scope across all 213 problems. Both benchmarks concentrate over 90\% of evaluation on Python while TypeScript, GitHub's most-used language, is absent. Backend and frontend development, which together constitute 46% of real-world editing activity, are largely missing, and documentation, testing, and maintenance edits (31.4% of human PRs) have zero representation. Both benchmarks have modest test counts (CanItEdit median 13, EDIT-Bench median 4), though CanItEdit compensates with near-complete whole-file coverage and fail-before/pass-after validation. 59\% of EDIT-Bench's low-coverage suites would not detect modifications outside the edit region. EDIT-Bench has 15 problems that are not solved by any of 40 LLMs and 11 of these problems trace failures to poor benchmark artifacts rather than model limitations. Further, 29% of EDIT-Bench problems and 6% of CanItEdit problems share a codebase with at least one other problem within the benchmark. In summary, these benchmarks measure a narrower construct than deployment decisions require. We therefore propose six empirically grounded desiderata and release all audit artifacts so the community can build instructed code-editing benchmarks whose scores reliably reflect real-world editing capability.
Permissive-Washing in the Open AI Supply Chain: A Large-Scale Audit of License Integrity
Feb 09, 2026Permissive licenses like MIT, Apache-2.0, and BSD-3-Clause dominate open-source AI, signaling that artifacts like models, datasets, and code can be freely used, modified, and redistributed. However, these licenses carry mandatory requirements: include the full license text, provide a copyright notice, and preserve upstream attribution, that remain unverified at scale. Failure to meet these conditions can place reuse outside the scope of the license, effectively leaving AI artifacts under default copyright for those uses and exposing downstream users to litigation. We call this phenomenon ``permissive washing'': labeling AI artifacts as free to use, while omitting the legal documentation required to make that label actionable. To assess how widespread permissive washing is in the AI supply chain, we empirically audit 124,278 dataset $\rightarrow$ model $\rightarrow$ application supply chains, spanning 3,338 datasets, 6,664 models, and 28,516 applications across Hugging Face and GitHub. We find that an astonishing 96.5\% of datasets and 95.8\% of models lack the required license text, only 2.3\% of datasets and 3.2\% of models satisfy both license text and copyright requirements, and even when upstream artifacts provide complete licensing evidence, attribution rarely propagates downstream: only 27.59\% of models preserve compliant dataset notices and only 5.75\% of applications preserve compliant model notices (with just 6.38\% preserving any linked upstream notice). Practitioners cannot assume permissive labels confer the rights they claim: license files and notices, not metadata, are the source of legal truth. To support future research, we release our full audit dataset and reproducible pipeline.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
LicenseGPT: A Fine-tuned Foundation Model for Publicly Available Dataset License Compliance
Dec 30, 2024
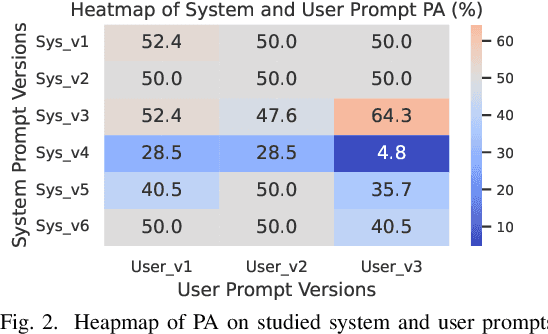

Dataset license compliance is a critical yet complex aspect of developing commercial AI products, particularly with the increasing use of publicly available datasets. Ambiguities in dataset licenses pose significant legal risks, making it challenging even for software IP lawyers to accurately interpret rights and obligations. In this paper, we introduce LicenseGPT, a fine-tuned foundation model (FM) specifically designed for dataset license compliance analysis. We first evaluate existing legal FMs (i.e., FMs specialized in understanding and processing legal texts) and find that the best-performing model achieves a Prediction Agreement (PA) of only 43.75%. LicenseGPT, fine-tuned on a curated dataset of 500 licenses annotated by legal experts, significantly improves PA to 64.30%, outperforming both legal and general-purpose FMs. Through an A/B test and user study with software IP lawyers, we demonstrate that LicenseGPT reduces analysis time by 94.44%, from 108 seconds to 6 seconds per license, without compromising accuracy. Software IP lawyers perceive LicenseGPT as a valuable supplementary tool that enhances efficiency while acknowledging the need for human oversight in complex cases. Our work underscores the potential of specialized AI tools in legal practice and offers a publicly available resource for practitioners and researchers.
From Cool Demos to Production-Ready FMware: Core Challenges and a Technology Roadmap
Oct 28, 2024

The rapid expansion of foundation models (FMs), such as large language models (LLMs), has given rise to FMware--software systems that integrate FMs as core components. While building demonstration-level FMware is relatively straightforward, transitioning to production-ready systems presents numerous challenges, including reliability, high implementation costs, scalability, and compliance with privacy regulations. This paper provides a thematic analysis of the key obstacles in productionizing FMware, synthesized from industry experience and diverse data sources, including hands-on involvement in the Open Platform for Enterprise AI (OPEA) and FMware lifecycle engineering. We identify critical issues in FM selection, data and model alignment, prompt engineering, agent orchestration, system testing, and deployment, alongside cross-cutting concerns such as memory management, observability, and feedback integration. We discuss needed technologies and strategies to address these challenges and offer guidance on how to enable the transition from demonstration systems to scalable, production-ready FMware solutions. Our findings underscore the importance of continued research and multi-industry collaboration to advance the development of production-ready FMware.
PromptExp: Multi-granularity Prompt Explanation of Large Language Models
Oct 16, 2024



Large Language Models excel in tasks like natural language understanding and text generation. Prompt engineering plays a critical role in leveraging LLM effectively. However, LLMs black-box nature hinders its interpretability and effective prompting engineering. A wide range of model explanation approaches have been developed for deep learning models, However, these local explanations are designed for single-output tasks like classification and regression,and cannot be directly applied to LLMs, which generate sequences of tokens. Recent efforts in LLM explanation focus on natural language explanations, but they are prone to hallucinations and inaccuracies. To address this, we introduce OurTool, a framework for multi-granularity prompt explanations by aggregating token-level insights. OurTool introduces two token-level explanation approaches: 1.an aggregation-based approach combining local explanation techniques, and 2. a perturbation-based approach with novel techniques to evaluate token masking impact. OurTool supports both white-box and black-box explanations and extends explanations to higher granularity levels, enabling flexible analysis. We evaluate OurTool in case studies such as sentiment analysis, showing the perturbation-based approach performs best using semantic similarity to assess perturbation impact. Furthermore, we conducted a user study to confirm OurTool's accuracy and practical value, and demonstrate its potential to enhance LLM interpretability.
Data Quality Antipatterns for Software Analytics
Aug 22, 2024



Background: Data quality is vital in software analytics, particularly for machine learning (ML) applications like software defect prediction (SDP). Despite the widespread use of ML in software engineering, the effect of data quality antipatterns on these models remains underexplored. Objective: This study develops a taxonomy of ML-specific data quality antipatterns and assesses their impact on software analytics models' performance and interpretation. Methods: We identified eight types and 14 sub-types of ML-specific data quality antipatterns through a literature review. We conducted experiments to determine the prevalence of these antipatterns in SDP data (RQ1), assess how cleaning order affects model performance (RQ2), evaluate the impact of antipattern removal on performance (RQ3), and examine the consistency of interpretation from models built with different antipatterns (RQ4). Results: In our SDP case study, we identified nine antipatterns. Over 90% of these overlapped at both row and column levels, complicating cleaning prioritization and risking excessive data removal. The order of cleaning significantly impacts ML model performance, with neural networks being more resilient to cleaning order changes than simpler models like logistic regression. Antipatterns such as Tailed Distributions and Class Overlap show a statistically significant correlation with performance metrics when other antipatterns are cleaned. Models built with different antipatterns showed moderate consistency in interpretation results. Conclusion: The cleaning order of different antipatterns impacts ML model performance. Five antipatterns have a statistically significant correlation with model performance when others are cleaned. Additionally, model interpretation is moderately affected by different data quality antipatterns.
Studying the Impact of TensorFlow and PyTorch Bindings on Machine Learning Software Quality
Jul 07, 2024



Bindings for machine learning frameworks (such as TensorFlow and PyTorch) allow developers to integrate a framework's functionality using a programming language different from the framework's default language (usually Python). In this paper, we study the impact of using TensorFlow and PyTorch bindings in C#, Rust, Python and JavaScript on the software quality in terms of correctness (training and test accuracy) and time cost (training and inference time) when training and performing inference on five widely used deep learning models. Our experiments show that a model can be trained in one binding and used for inference in another binding for the same framework without losing accuracy. Our study is the first to show that using a non-default binding can help improve machine learning software quality from the time cost perspective compared to the default Python binding while still achieving the same level of correctness.
Rethinking Software Engineering in the Foundation Model Era: A Curated Catalogue of Challenges in the Development of Trustworthy FMware
Mar 04, 2024



Foundation models (FMs), such as Large Language Models (LLMs), have revolutionized software development by enabling new use cases and business models. We refer to software built using FMs as FMware. The unique properties of FMware (e.g., prompts, agents, and the need for orchestration), coupled with the intrinsic limitations of FMs (e.g., hallucination) lead to a completely new set of software engineering challenges. Based on our industrial experience, we identified 10 key SE4FMware challenges that have caused enterprise FMware development to be unproductive, costly, and risky. In this paper, we discuss these challenges in detail and state the path for innovation that we envision. Next, we present FMArts, which is our long-term effort towards creating a cradle-to-grave platform for the engineering of trustworthy FMware. Finally, we (i) show how the unique properties of FMArts enabled us to design and develop a complex FMware for a large customer in a timely manner and (ii) discuss the lessons that we learned in doing so. We hope that the disclosure of the aforementioned challenges and our associated efforts to tackle them will not only raise awareness but also promote deeper and further discussions, knowledge sharing, and innovative solutions across the software engineering discipline.
Keeping Deep Learning Models in Check: A History-Based Approach to Mitigate Overfitting
Jan 18, 2024In software engineering, deep learning models are increasingly deployed for critical tasks such as bug detection and code review. However, overfitting remains a challenge that affects the quality, reliability, and trustworthiness of software systems that utilize deep learning models. Overfitting can be (1) prevented (e.g., using dropout or early stopping) or (2) detected in a trained model (e.g., using correlation-based approaches). Both overfitting detection and prevention approaches that are currently used have constraints (e.g., requiring modification of the model structure, and high computing resources). In this paper, we propose a simple, yet powerful approach that can both detect and prevent overfitting based on the training history (i.e., validation losses). Our approach first trains a time series classifier on training histories of overfit models. This classifier is then used to detect if a trained model is overfit. In addition, our trained classifier can be used to prevent overfitting by identifying the optimal point to stop a model's training. We evaluate our approach on its ability to identify and prevent overfitting in real-world samples. We compare our approach against correlation-based detection approaches and the most commonly used prevention approach (i.e., early stopping). Our approach achieves an F1 score of 0.91 which is at least 5% higher than the current best-performing non-intrusive overfitting detection approach. Furthermore, our approach can stop training to avoid overfitting at least 32% of the times earlier than early stopping and has the same or a better rate of returning the best model.