 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Evaluation Engineering: An Empirical Study of ML Evaluation Harnesses in the Wild
May 22, 2026Evaluation harnesses are software systems that orchestrate model evaluation by managing model invocation, data loading, metric computation, and result reporting. Despite their critical role in machine learning infrastructure, their operational challenges and engineering concerns have received limited attention so far. We present an empirical study of 57 evaluation harnesses, deriving a five-stage harness model and classifying 16,560 issues by workflow stage and root cause. Most harness operational challenges concentrate in the Specification stage (41.4% of issues), where harnesses integrate external models, datasets, and scoring judges. The three most frequent root causes of operational challenges are unimplemented features (24.3%), documentation gaps (20.3%), and missing input validation (17.2%), which together account for 61.7% of classified issues, spanning both defects in existing functionality and capability gaps that block intended workflows. Root causes also vary by workflow stage: environment incompatibility and external dependency breakage account for 36.2% of provisioning issues, whereas algorithmic error (25.9%) and validation gap (22.5%) dominate assessment issues. Together, these contributions establish an empirical foundation for treating evaluation engineering as a distinct software engineering concern.
AIDev: Studying AI Coding Agents on GitHub
Feb 09, 2026AI coding agents are rapidly transforming software engineering by performing tasks such as feature development, debugging, and testing. Despite their growing impact, the research community lacks a comprehensive dataset capturing how these agents are used in real-world projects. To address this gap, we introduce AIDev, a large-scale dataset focused on agent-authored pull requests (Agentic-PRs) in real-world GitHub repositories. AIDev aggregates 932,791 Agentic-PRs produced by five agents: OpenAI Codex, Devin, GitHub Copilot, Cursor, and Claude Code. These PRs span 116,211 repositories and involve 72,189 developers. In addition, AIDev includes a curated subset of 33,596 Agentic-PRs from 2,807 repositories with over 100 stars, providing further information such as comments, reviews, commits, and related issues. This dataset offers a foundation for future research on AI adoption, developer productivity, and human-AI collaboration in the new era of software engineering. > AI Agent, Agentic AI, Coding Agent, Agentic Coding, Agentic Software Engineering, Agentic Engineering
Permissive-Washing in the Open AI Supply Chain: A Large-Scale Audit of License Integrity
Feb 09, 2026Permissive licenses like MIT, Apache-2.0, and BSD-3-Clause dominate open-source AI, signaling that artifacts like models, datasets, and code can be freely used, modified, and redistributed. However, these licenses carry mandatory requirements: include the full license text, provide a copyright notice, and preserve upstream attribution, that remain unverified at scale. Failure to meet these conditions can place reuse outside the scope of the license, effectively leaving AI artifacts under default copyright for those uses and exposing downstream users to litigation. We call this phenomenon ``permissive washing'': labeling AI artifacts as free to use, while omitting the legal documentation required to make that label actionable. To assess how widespread permissive washing is in the AI supply chain, we empirically audit 124,278 dataset $\rightarrow$ model $\rightarrow$ application supply chains, spanning 3,338 datasets, 6,664 models, and 28,516 applications across Hugging Face and GitHub. We find that an astonishing 96.5\% of datasets and 95.8\% of models lack the required license text, only 2.3\% of datasets and 3.2\% of models satisfy both license text and copyright requirements, and even when upstream artifacts provide complete licensing evidence, attribution rarely propagates downstream: only 27.59\% of models preserve compliant dataset notices and only 5.75\% of applications preserve compliant model notices (with just 6.38\% preserving any linked upstream notice). Practitioners cannot assume permissive labels confer the rights they claim: license files and notices, not metadata, are the source of legal truth. To support future research, we release our full audit dataset and reproducible pipeline.
Beyond Tokens: Semantic-Aware Speculative Decoding for Efficient Inference by Probing Internal States
Feb 03, 2026Large Language Models (LLMs) achieve strong performance across many tasks but suffer from high inference latency due to autoregressive decoding. The issue is exacerbated in Large Reasoning Models (LRMs), which generate lengthy chains of thought. While speculative decoding accelerates inference by drafting and verifying multiple tokens in parallel, existing methods operate at the token level and ignore semantic equivalence (i.e., different token sequences expressing the same meaning), leading to inefficient rejections. We propose SemanticSpec, a semantic-aware speculative decoding framework that verifies entire semantic sequences instead of tokens. SemanticSpec introduces a semantic probability estimation mechanism that probes the model's internal hidden states to assess the likelihood of generating sequences with specific meanings.Experiments on four benchmarks show that SemanticSpec achieves up to 2.7x speedup on DeepSeekR1-32B and 2.1x on QwQ-32B, consistently outperforming token-level and sequence-level baselines in both efficiency and effectiveness.
Understanding Prompt Management in GitHub Repositories: A Call for Best Practices
Sep 15, 2025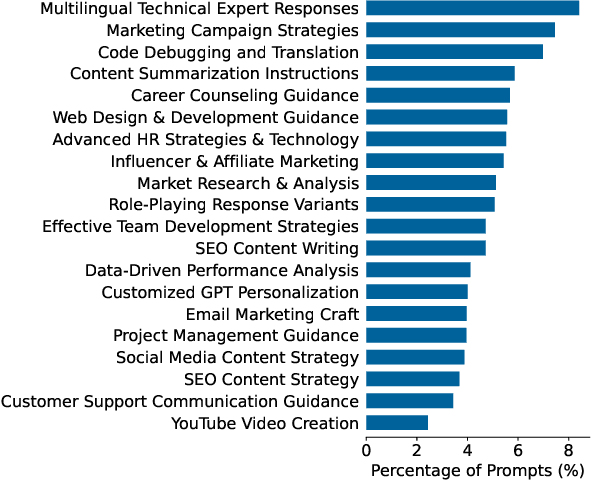
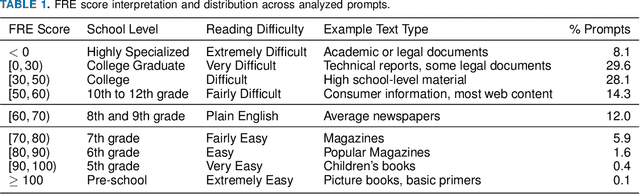
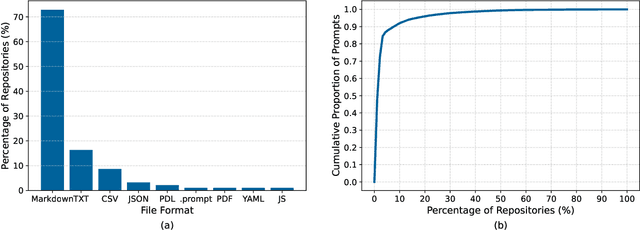

The rapid adoption of foundation models (e.g., large language models) has given rise to promptware, i.e., software built using natural language prompts. Effective management of prompts, such as organization and quality assurance, is essential yet challenging. In this study, we perform an empirical analysis of 24,800 open-source prompts from 92 GitHub repositories to investigate prompt management practices and quality attributes. Our findings reveal critical challenges such as considerable inconsistencies in prompt formatting, substantial internal and external prompt duplication, and frequent readability and spelling issues. Based on these findings, we provide actionable recommendations for developers to enhance the usability and maintainability of open-source prompts within the rapidly evolving promptware ecosystem.
OmniLLP: Enhancing LLM-based Log Level Prediction with Context-Aware Retrieval
Aug 12, 2025



Developers insert logging statements in source code to capture relevant runtime information essential for maintenance and debugging activities. Log level choice is an integral, yet tricky part of the logging activity as it controls log verbosity and therefore influences systems' observability and performance. Recent advances in ML-based log level prediction have leveraged large language models (LLMs) to propose log level predictors (LLPs) that demonstrated promising performance improvements (AUC between 0.64 and 0.8). Nevertheless, current LLM-based LLPs rely on randomly selected in-context examples, overlooking the structure and the diverse logging practices within modern software projects. In this paper, we propose OmniLLP, a novel LLP enhancement framework that clusters source files based on (1) semantic similarity reflecting the code's functional purpose, and (2) developer ownership cohesion. By retrieving in-context learning examples exclusively from these semantic and ownership aware clusters, we aim to provide more coherent prompts to LLPs leveraging LLMs, thereby improving their predictive accuracy. Our results show that both semantic and ownership-aware clusterings statistically significantly improve the accuracy (by up to 8\% AUC) of the evaluated LLM-based LLPs compared to random predictors (i.e., leveraging randomly selected in-context examples from the whole project). Additionally, our approach that combines the semantic and ownership signal for in-context prediction achieves an impressive 0.88 to 0.96 AUC across our evaluated projects. Our findings highlight the value of integrating software engineering-specific context, such as code semantic and developer ownership signals into LLM-LLPs, offering developers a more accurate, contextually-aware approach to logging and therefore, enhancing system maintainability and observability.
Towards Conversational Development Environments: Using Theory-of-Mind and Multi-Agent Architectures for Requirements Refinement
May 28, 2025



Foundation Models (FMs) have shown remarkable capabilities in various natural language tasks. However, their ability to accurately capture stakeholder requirements remains a significant challenge for using FMs for software development. This paper introduces a novel approach that leverages an FM-powered multi-agent system called AlignMind to address this issue. By having a cognitive architecture that enhances FMs with Theory-of-Mind capabilities, our approach considers the mental states and perspectives of software makers. This allows our solution to iteratively clarify the beliefs, desires, and intentions of stakeholders, translating these into a set of refined requirements and a corresponding actionable natural language workflow in the often-overlooked requirements refinement phase of software engineering, which is crucial after initial elicitation. Through a multifaceted evaluation covering 150 diverse use cases, we demonstrate that our approach can accurately capture the intents and requirements of stakeholders, articulating them as both specifications and a step-by-step plan of action. Our findings suggest that the potential for significant improvements in the software development process justifies these investments. Our work lays the groundwork for future innovation in building intent-first development environments, where software makers can seamlessly collaborate with AIs to create software that truly meets their needs.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
Model Performance-Guided Evaluation Data Selection for Effective Prompt Optimization
May 15, 2025



Optimizing Large Language Model (LLM) performance requires well-crafted prompts, but manual prompt engineering is labor-intensive and often ineffective. Automated prompt optimization techniques address this challenge but the majority of them rely on randomly selected evaluation subsets, which fail to represent the full dataset, leading to unreliable evaluations and suboptimal prompts. Existing coreset selection methods, designed for LLM benchmarking, are unsuitable for prompt optimization due to challenges in clustering similar samples, high data collection costs, and the unavailability of performance data for new or private datasets. To overcome these issues, we propose IPOMP, an Iterative evaluation data selection for effective Prompt Optimization using real-time Model Performance. IPOMP is a two-stage approach that selects representative and diverse samples using semantic clustering and boundary analysis, followed by iterative refinement with real-time model performance data to replace redundant samples. Evaluations on the BIG-bench dataset show that IPOMP improves effectiveness by 1.6% to 5.3% and stability by at least 57% compared with SOTA baselines, with minimal computational overhead below 1%. Furthermore, the results demonstrate that our real-time performance-guided refinement approach can be universally applied to enhance existing coreset selection methods.
LicenseGPT: A Fine-tuned Foundation Model for Publicly Available Dataset License Compliance
Dec 30, 2024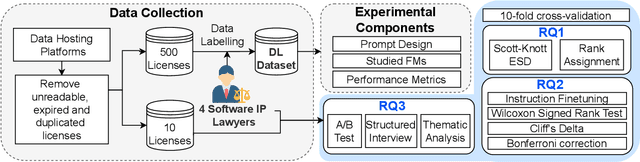
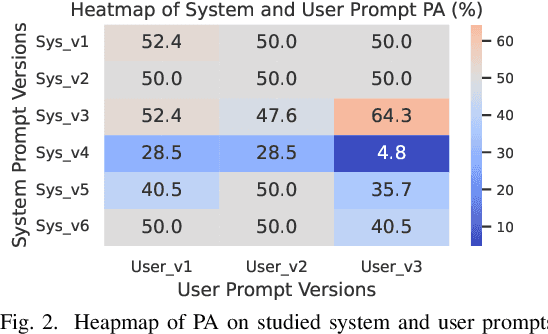

Dataset license compliance is a critical yet complex aspect of developing commercial AI products, particularly with the increasing use of publicly available datasets. Ambiguities in dataset licenses pose significant legal risks, making it challenging even for software IP lawyers to accurately interpret rights and obligations. In this paper, we introduce LicenseGPT, a fine-tuned foundation model (FM) specifically designed for dataset license compliance analysis. We first evaluate existing legal FMs (i.e., FMs specialized in understanding and processing legal texts) and find that the best-performing model achieves a Prediction Agreement (PA) of only 43.75%. LicenseGPT, fine-tuned on a curated dataset of 500 licenses annotated by legal experts, significantly improves PA to 64.30%, outperforming both legal and general-purpose FMs. Through an A/B test and user study with software IP lawyers, we demonstrate that LicenseGPT reduces analysis time by 94.44%, from 108 seconds to 6 seconds per license, without compromising accuracy. Software IP lawyers perceive LicenseGPT as a valuable supplementary tool that enhances efficiency while acknowledging the need for human oversight in complex cases. Our work underscores the potential of specialized AI tools in legal practice and offers a publicly available resource for practitioners and researchers.