 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Noise of Structural Perturbations on Graph Adversarial Attacks
Apr 30, 2025



Graph neural networks have been widely utilized to solve graph-related tasks because of their strong learning power in utilizing the local information of neighbors. However, recent studies on graph adversarial attacks have proven that current graph neural networks are not robust against malicious attacks. Yet much of the existing work has focused on the optimization objective based on attack performance to obtain (near) optimal perturbations, but paid less attention to the strength quantification of each perturbation such as the injection of a particular node/link, which makes the choice of perturbations a black-box model that lacks interpretability. In this work, we propose the concept of noise to quantify the attack strength of each adversarial link. Furthermore, we propose three attack strategies based on the defined noise and classification margins in terms of single and multiple steps optimization. Extensive experiments conducted on benchmark datasets against three representative graph neural networks demonstrate the effectiveness of the proposed attack strategies. Particularly, we also investigate the preferred patterns of effective adversarial perturbations by analyzing the corresponding properties of the selected perturbation nodes.
Mitigating the Structural Bias in Graph Adversarial Defenses
Apr 29, 2025In recent years, graph neural networks (GNNs) have shown great potential in addressing various graph structure-related downstream tasks. However, recent studies have found that current GNNs are susceptible to malicious adversarial attacks. Given the inevitable presence of adversarial attacks in the real world, a variety of defense methods have been proposed to counter these attacks and enhance the robustness of GNNs. Despite the commendable performance of these defense methods, we have observed that they tend to exhibit a structural bias in terms of their defense capability on nodes with low degree (i.e., tail nodes), which is similar to the structural bias of traditional GNNs on nodes with low degree in the clean graph. Therefore, in this work, we propose a defense strategy by including hetero-homo augmented graph construction, $k$NN augmented graph construction, and multi-view node-wise attention modules to mitigate the structural bias of GNNs against adversarial attacks. Notably, the hetero-homo augmented graph consists of removing heterophilic links (i.e., links connecting nodes with dissimilar features) globally and adding homophilic links (i.e., links connecting nodes with similar features) for nodes with low degree. To further enhance the defense capability, an attention mechanism is adopted to adaptively combine the representations from the above two kinds of graph views. We conduct extensive experiments to demonstrate the defense and debiasing effect of the proposed strategy on benchmark datasets.
NVSMask3D: Hard Visual Prompting with Camera Pose Interpolation for 3D Open Vocabulary Instance Segmentation
Apr 20, 2025Vision-language models (VLMs) have demonstrated impressive zero-shot transfer capabilities in image-level visual perception tasks. However, they fall short in 3D instance-level segmentation tasks that require accurate localization and recognition of individual objects. To bridge this gap, we introduce a novel 3D Gaussian Splatting based hard visual prompting approach that leverages camera interpolation to generate diverse viewpoints around target objects without any 2D-3D optimization or fine-tuning. Our method simulates realistic 3D perspectives, effectively augmenting existing hard visual prompts by enforcing geometric consistency across viewpoints. This training-free strategy seamlessly integrates with prior hard visual prompts, enriching object-descriptive features and enabling VLMs to achieve more robust and accurate 3D instance segmentation in diverse 3D scenes.
Gaussian Splatting in Mirrors: Reflection-Aware Rendering via Virtual Camera Optimization
Oct 02, 2024



Recent advancements in 3D Gaussian Splatting (3D-GS) have revolutionized novel view synthesis, facilitating real-time, high-quality image rendering. However, in scenarios involving reflective surfaces, particularly mirrors, 3D-GS often misinterprets reflections as virtual spaces, resulting in blurred and inconsistent multi-view rendering within mirrors. Our paper presents a novel method aimed at obtaining high-quality multi-view consistent reflection rendering by modelling reflections as physically-based virtual cameras. We estimate mirror planes with depth and normal estimates from 3D-GS and define virtual cameras that are placed symmetrically about the mirror plane. These virtual cameras are then used to explain mirror reflections in the scene. To address imperfections in mirror plane estimates, we propose a straightforward yet effective virtual camera optimization method to enhance reflection quality. We collect a new mirror dataset including three real-world scenarios for more diverse evaluation. Experimental validation on both Mirror-Nerf and our real-world dataset demonstrate the efficacy of our approach. We achieve comparable or superior results while significantly reducing training time compared to previous state-of-the-art.
GANI: Global Attacks on Graph Neural Networks via Imperceptible Node Injections
Oct 23, 2022



Graph neural networks (GNNs) have found successful applications in various graph-related tasks. However, recent studies have shown that many GNNs are vulnerable to adversarial attacks. In a vast majority of existing studies, adversarial attacks on GNNs are launched via direct modification of the original graph such as adding/removing links, which may not be applicable in practice. In this paper, we focus on a realistic attack operation via injecting fake nodes. The proposed Global Attack strategy via Node Injection (GANI) is designed under the comprehensive consideration of an unnoticeable perturbation setting from both structure and feature domains. Specifically, to make the node injections as imperceptible and effective as possible, we propose a sampling operation to determine the degree of the newly injected nodes, and then generate features and select neighbors for these injected nodes based on the statistical information of features and evolutionary perturbations obtained from a genetic algorithm, respectively. In particular, the proposed feature generation mechanism is suitable for both binary and continuous node features. Extensive experimental results on benchmark datasets against both general and defended GNNs show strong attack performance of GANI. Moreover, the imperceptibility analyses also demonstrate that GANI achieves a relatively unnoticeable injection on benchmark datasets.
MG-GCN: Fast and Effective Learning with Mix-grained Aggregators for Training Large Graph Convolutional Networks
Nov 17, 2020
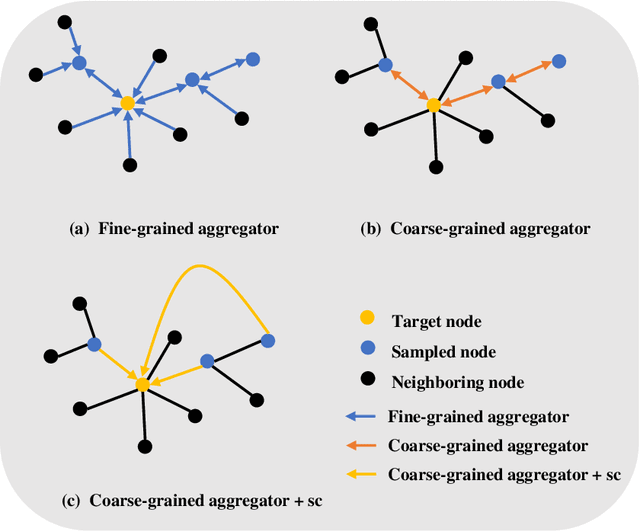
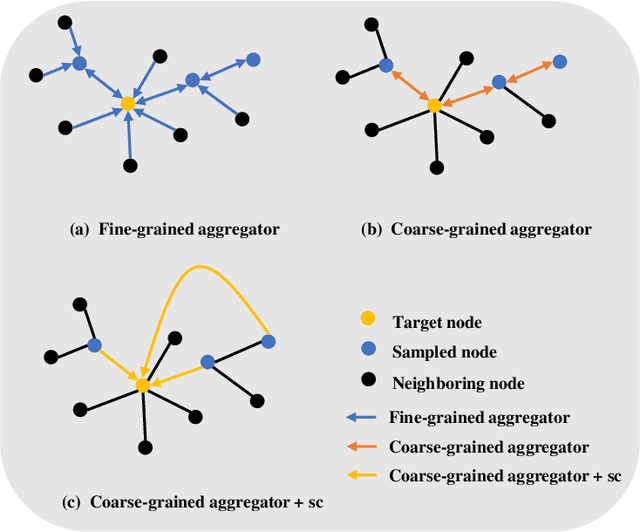
Graph convolutional networks (GCNs) have been employed as a kind of significant tool on many graph-based applications recently. Inspired by convolutional neural networks (CNNs), GCNs generate the embeddings of nodes by aggregating the information of their neighbors layer by layer. However, the high computational and memory cost of GCNs due to the recursive neighborhood expansion across GCN layers makes it infeasible for training on large graphs. To tackle this issue, several sampling methods during the process of information aggregation have been proposed to train GCNs in a mini-batch Stochastic Gradient Descent (SGD) manner. Nevertheless, these sampling strategies sometimes bring concerns about insufficient information collection, which may hinder the learning performance in terms of accuracy and convergence. To tackle the dilemma between accuracy and efficiency, we propose to use aggregators with different granularities to gather neighborhood information in different layers. Then, a degree-based sampling strategy, which avoids the exponential complexity, is constructed for sampling a fixed number of nodes. Combining the above two mechanisms, the proposed model, named Mix-grained GCN (MG-GCN) achieves state-of-the-art performance in terms of accuracy, training speed, convergence speed, and memory cost through a comprehensive set of experiments on four commonly used benchmark datasets and a new Ethereum dataset.