 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
Surg-R1: A Hierarchical Reasoning Foundation Model for Scalable and Interpretable Surgical Decision Support with Multi-Center Clinical Validation
Mar 12, 2026Surgical scene understanding demands not only accurate predictions but also interpretable reasoning that surgeons can verify against clinical expertise. However, existing surgical vision-language models generate predictions without reasoning chains, and general-purpose reasoning models fail on compositional surgical tasks without domain-specific knowledge. We present Surg-R1, a surgical Vision-Language Model that addresses this gap through hierarchical reasoning trained via a four-stage pipeline. Our approach introduces three key contributions: (1) a three-level reasoning hierarchy decomposing surgical interpretation into perceptual grounding, relational understanding, and contextual reasoning; (2) the largest surgical chain-of-thought dataset with 320,000 reasoning pairs; and (3) a four-stage training pipeline progressing from supervised fine-tuning to group relative policy optimization and iterative self-improvement. Evaluation on SurgBench, comprising six public benchmarks and six multi-center external validation datasets from five institutions, demonstrates that Surg-R1 achieves the highest Arena Score (64.9%) on public benchmarks versus Gemini 3.0 Pro (46.1%) and GPT-5.1 (37.9%), outperforming both proprietary reasoning models and specialized surgical VLMs on the majority of tasks spanning instrument localization, triplet recognition, phase recognition, action recognition, and critical view of safety assessment, with a 15.2 percentage point improvement over the strongest surgical baseline on external validation.
SurgFed: Language-guided Multi-Task Federated Learning for Surgical Video Understanding
Mar 10, 2026Surgical scene Multi-Task Federated Learning (MTFL) is essential for robot-assisted minimally invasive surgery (RAS) but remains underexplored in surgical video understanding due to two key challenges: (1) Tissue Diversity: Local models struggle to adapt to site-specific tissue features, limiting their effectiveness in heterogeneous clinical environments and leading to poor local predictions. (2) Task Diversity: Server-side aggregation, relying solely on gradient-based clustering, often produces suboptimal or incorrect parameter updates due to inter-site task heterogeneity, resulting in inaccurate localization. In light of these two issues, we propose SurgFed, a multi-task federated learning framework, enabling federated learning for surgical scene segmentation and depth estimation across diverse surgical types. SurgFed is powered by two appealing designs, i.e., Language-guided Channel Selection (LCS) and Language-guided Hyper Aggregation (LHA), to address the challenge of fully exploration on corss-site and cross-task. Technically, the LCS is first designed a lightweight personalized channel selection network that enhances site-specific adaptation using pre-defined text inputs, which optimally the local model learn the specific embeddings. We further introduce the LHA that employs a layer-wise cross-attention mechanism with pre-defined text inputs to model task interactions across sites and guide a hypernetwork for personalized parameter updates. Extensive empirical evidence shows that SurgFed yields improvements over the state-of-the-art methods in five public datasets across four surgical types. The code is available at https://anonymous.4open.science/r/SurgFed-070E/.
SurGo-R1: Benchmarking and Modeling Contextual Reasoning for Operative Zone in Surgical Video
Feb 25, 2026Minimally invasive surgery has dramatically improved patient operative outcomes, yet identifying safe operative zones remains challenging in critical phases, requiring surgeons to integrate visual cues, procedural phase, and anatomical context under high cognitive load. Existing AI systems offer binary safety verification or static detection, ignoring the phase-dependent nature of intraoperative reasoning. We introduce ResGo, a benchmark of laparoscopic frames annotated with Go Zone bounding boxes and clinician-authored rationales covering phase, exposure quality reasoning, next action and risk reminder. We introduce evaluation metrics that treat correct grounding under incorrect phase as failures, revealing that most vision-language models cannot handle such tasks and perform poorly. We then present SurGo-R1, a model optimized via RLHF with a multi-turn phase-then-go architecture where the model first identifies the surgical phase, then generates reasoning and Go Zone coordinates conditioned on that context. On unseen procedures, SurGo-R1 achieves 76.6% phase accuracy, 32.7 mIoU, and 54.8% hardcore accuracy, a 6.6$\times$ improvement over the mainstream generalist VLMs. Code, model and benchmark will be available at https://github.com/jinlab-imvr/SurGo-R1
SurgRAW: Multi-Agent Workflow with Chain-of-Thought Reasoning for Surgical Intelligence
Mar 13, 2025



Integration of Vision-Language Models (VLMs) in surgical intelligence is hindered by hallucinations, domain knowledge gaps, and limited understanding of task interdependencies within surgical scenes, undermining clinical reliability. While recent VLMs demonstrate strong general reasoning and thinking capabilities, they still lack the domain expertise and task-awareness required for precise surgical scene interpretation. Although Chain-of-Thought (CoT) can structure reasoning more effectively, current approaches rely on self-generated CoT steps, which often exacerbate inherent domain gaps and hallucinations. To overcome this, we present SurgRAW, a CoT-driven multi-agent framework that delivers transparent, interpretable insights for most tasks in robotic-assisted surgery. By employing specialized CoT prompts across five tasks: instrument recognition, action recognition, action prediction, patient data extraction, and outcome assessment, SurgRAW mitigates hallucinations through structured, domain-aware reasoning. Retrieval-Augmented Generation (RAG) is also integrated to external medical knowledge to bridge domain gaps and improve response reliability. Most importantly, a hierarchical agentic system ensures that CoT-embedded VLM agents collaborate effectively while understanding task interdependencies, with a panel discussion mechanism promotes logical consistency. To evaluate our method, we introduce SurgCoTBench, the first reasoning-based dataset with structured frame-level annotations. With comprehensive experiments, we demonstrate the effectiveness of proposed SurgRAW with 29.32% accuracy improvement over baseline VLMs on 12 robotic procedures, achieving the state-of-the-art performance and advancing explainable, trustworthy, and autonomous surgical assistance.
Joint Generative-Contrastive Representation Learning for Anomalous Sound Detection
May 20, 2023


In this paper, we propose a joint generative and contrastive representation learning method (GeCo) for anomalous sound detection (ASD). GeCo exploits a Predictive AutoEncoder (PAE) equipped with self-attention as a generative model to perform frame-level prediction. The output of the PAE together with original normal samples, are used for supervised contrastive representative learning in a multi-task framework. Besides cross-entropy loss between classes, contrastive loss is used to separate PAE output and original samples within each class. GeCo aims to better capture context information among frames, thanks to the self-attention mechanism for PAE model. Furthermore, GeCo combines generative and contrastive learning from which we aim to yield more effective and informative representations, compared to existing methods. Extensive experiments have been conducted on the DCASE2020 Task2 development dataset, showing that GeCo outperforms state-of-the-art generative and discriminative methods.
Transfer Learning for Context-Aware Spoken Language Understanding
Mar 03, 2020
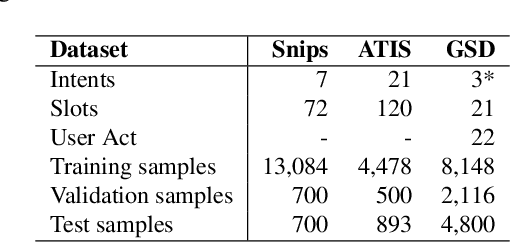
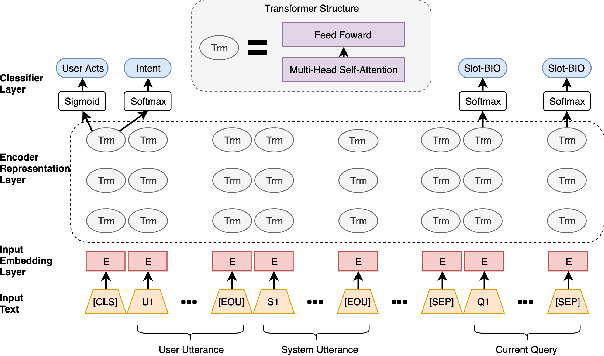
Spoken language understanding (SLU) is a key component of task-oriented dialogue systems. SLU parses natural language user utterances into semantic frames. Previous work has shown that incorporating context information significantly improves SLU performance for multi-turn dialogues. However, collecting a large-scale human-labeled multi-turn dialogue corpus for the target domains is complex and costly. To reduce dependency on the collection and annotation effort, we propose a Context Encoding Language Transformer (CELT) model facilitating exploiting various context information for SLU. We explore different transfer learning approaches to reduce dependency on data collection and annotation. In addition to unsupervised pre-training using large-scale general purpose unlabeled corpora, such as Wikipedia, we explore unsupervised and supervised adaptive training approaches for transfer learning to benefit from other in-domain and out-of-domain dialogue corpora. Experimental results demonstrate that the proposed model with the proposed transfer learning approaches achieves significant improvement on the SLU performance over state-of-the-art models on two large-scale single-turn dialogue benchmarks and one large-scale multi-turn dialogue benchmark.
* 6 pages, 3 figures, ASRU2019
BERT for Joint Intent Classification and Slot Filling
Feb 28, 2019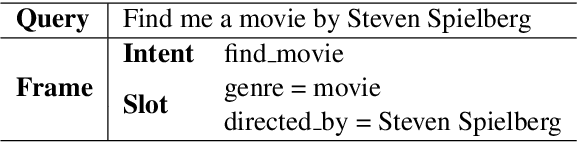
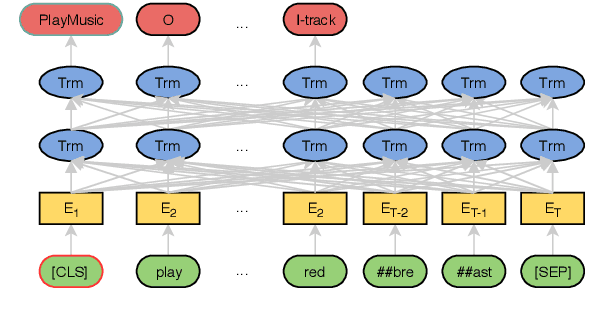
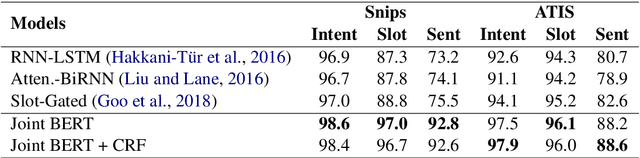
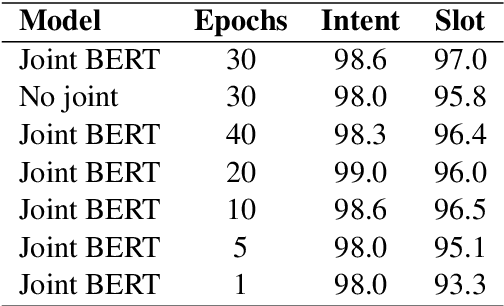
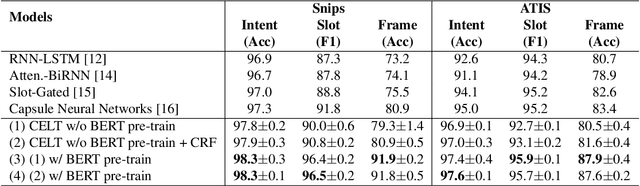
Intent classification and slot filling are two essential tasks for natural language understanding. They often suffer from small-scale human-labeled training data, resulting in poor generalization capability, especially for rare words. Recently a new language representation model, BERT (Bidirectional Encoder Representations from Transformers), facilitates pre-training deep bidirectional representations on large-scale unlabeled corpora, and has created state-of-the-art models for a wide variety of natural language processing tasks after simple fine-tuning. However, there has not been much effort on exploring BERT for natural language understanding. In this work, we propose a joint intent classification and slot filling model based on BERT. Experimental results demonstrate that our proposed model achieves significant improvement on intent classification accuracy, slot filling F1, and sentence-level semantic frame accuracy on several public benchmark datasets, compared to the attention-based recurrent neural network models and slot-gated models.