 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Temporal Perception: Post-Training Large Audio-Language Models with Audio-Side Time Prompt
Apr 15, 2026Large Audio-Language Models (LALMs) enable general audio understanding and demonstrate remarkable performance across various audio tasks. However, these models still face challenges in temporal perception (e.g., inferring event onset and offset), leading to limited utility in fine-grained scenarios. To address this issue, we propose Audio-Side Time Prompt and leverage Reinforcement Learning (RL) to develop the TimePro-RL framework for fine-grained temporal perception. Specifically, we encode timestamps as embeddings and interleave them within the audio feature sequence as temporal coordinates to prompt the model. Furthermore, we introduce RL following Supervised Fine-Tuning (SFT) to directly optimize temporal alignment performance. Experiments demonstrate that TimePro-RL achieves significant performance gains across a range of audio temporal tasks, such as audio grounding, sound event detection, and dense audio captioning, validating its robust effectiveness.
A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Mar 29, 2026In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Spectrogram features for audio and speech analysis
Mar 16, 2026Spectrogram-based representations have grown to dominate the feature space for deep learning audio analysis systems, and are often adopted for speech analysis also. Initially, the primary motivator for spectrogram-based representations was their ability to present sound as a two dimensional signal in the time-frequency plane, which not only provides an interpretable physical basis for analysing sound, but also unlocks the use of a wide range of machine learning techniques such as convolutional neural networks, that had been developed for image processing. A spectrogram is a matrix characterised by the resolution and span of its two dimensions, as well as by the representation and scaling of each element. Many possibilities for these three characteristics have been explored by researchers across numerous application areas, with different settings showing affinity for various tasks. This paper reviews the use of spectrogram-based representations and surveys the state-of-the-art to question how front-end feature representation choice allies with back-end classifier architecture for different tasks.
* 30 pages
CodecFlow: Efficient Bandwidth Extension via Conditional Flow Matching in Neural Codec Latent Space
Mar 03, 2026Speech Bandwidth Extension improves clarity and intelligibility by restoring/inferring appropriate high-frequency content for low-bandwidth speech. Existing methods often rely on spectrogram or waveform modeling, which can incur higher computational cost and have limited high-frequency fidelity. Neural audio codecs offer compact latent representations that better preserve acoustic detail, yet accurately recovering high-resolution latent information remains challenging due to representation mismatch. We present CodecFlow, a neural codec-based BWE framework that performs efficient speech reconstruction in a compact latent space. CodecFlow employs a voicing-aware conditional flow converter on continuous codec embeddings and a structure-constrained residual vector quantizer to improve latent alignment stability. Optimized end-to-end, CodecFlow achieves strong spectral fidelity and enhanced perceptual quality on 8 kHz to 16 kHz and 44.1 kHz speech BWE tasks.
In-Ear Electrode EEG for Practical SSVEP BCI
Sep 18, 2025



Steady State Visual Evoked Potential (SSVEP) methods for brain computer interfaces (BCI) are popular due to higher information transfer rate and easier setup with minimal training, compared to alternative methods. With precisely generated visual stimulus frequency, it is possible to translate brain signals into external actions or signals. Traditionally, SSVEP data is collected from the occipital region using electrodes with or without gel, normally mounted on a head cap. In this experimental study, we develop an in ear electrode to collect SSVEP data for four different flicker frequencies and compare against occipital scalp electrode data. Data from five participants demonstrates the feasibility of in-ear electrode based SSVEP, significantly enhancing the practicability of wearable BCI applications.
Automated evaluation of children's speech fluency for low-resource languages
May 26, 2025Assessment of children's speaking fluency in education is well researched for majority languages, but remains highly challenging for low resource languages. This paper proposes a system to automatically assess fluency by combining a fine-tuned multilingual ASR model, an objective metrics extraction stage, and a generative pre-trained transformer (GPT) network. The objective metrics include phonetic and word error rates, speech rate, and speech-pause duration ratio. These are interpreted by a GPT-based classifier guided by a small set of human-evaluated ground truth examples, to score fluency. We evaluate the proposed system on a dataset of children's speech in two low-resource languages, Tamil and Malay and compare the classification performance against Random Forest and XGBoost, as well as using ChatGPT-4o to predict fluency directly from speech input. Results demonstrate that the proposed approach achieves significantly higher accuracy than multimodal GPT or other methods.
On-Device LLMs for SMEs: Challenges and Opportunities
Oct 21, 2024This paper presents a systematic review of the infrastructure requirements for deploying Large Language Models (LLMs) on-device within the context of small and medium-sized enterprises (SMEs), focusing on both hardware and software perspectives. From the hardware viewpoint, we discuss the utilization of processing units like GPUs and TPUs, efficient memory and storage solutions, and strategies for effective deployment, addressing the challenges of limited computational resources typical in SME settings. From the software perspective, we explore framework compatibility, operating system optimization, and the use of specialized libraries tailored for resource-constrained environments. The review is structured to first identify the unique challenges faced by SMEs in deploying LLMs on-device, followed by an exploration of the opportunities that both hardware innovations and software adaptations offer to overcome these obstacles. Such a structured review provides practical insights, contributing significantly to the community by enhancing the technological resilience of SMEs in integrating LLMs.
Prototype based Masked Audio Model for Self-Supervised Learning of Sound Event Detection
Sep 26, 2024



A significant challenge in sound event detection (SED) is the effective utilization of unlabeled data, given the limited availability of labeled data due to high annotation costs. Semi-supervised algorithms rely on labeled data to learn from unlabeled data, and the performance is constrained by the quality and size of the former. In this paper, we introduce the Prototype based Masked Audio Model~(PMAM) algorithm for self-supervised representation learning in SED, to better exploit unlabeled data. Specifically, semantically rich frame-level pseudo labels are constructed from a Gaussian mixture model (GMM) based prototypical distribution modeling. These pseudo labels supervise the learning of a Transformer-based masked audio model, in which binary cross-entropy loss is employed instead of the widely used InfoNCE loss, to provide independent loss contributions from different prototypes, which is important in real scenarios in which multiple labels may apply to unsupervised data frames. A final stage of fine-tuning with just a small amount of labeled data yields a very high performing SED model. On like-for-like tests using the DESED task, our method achieves a PSDS1 score of 62.5\%, surpassing current state-of-the-art models and demonstrating the superiority of the proposed technique.
MAT-SED: A Masked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 19, 2024

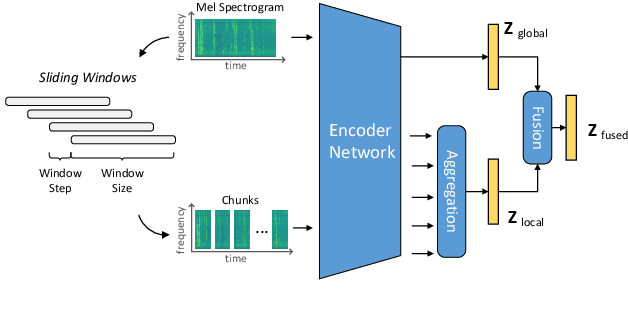

Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.
MAT-SED: AMasked Audio Transformer with Masked-Reconstruction Based Pre-training for Sound Event Detection
Aug 16, 2024Sound event detection (SED) methods that leverage a large pre-trained Transformer encoder network have shown promising performance in recent DCASE challenges. However, they still rely on an RNN-based context network to model temporal dependencies, largely due to the scarcity of labeled data. In this work, we propose a pure Transformer-based SED model with masked-reconstruction based pre-training, termed MAT-SED. Specifically, a Transformer with relative positional encoding is first designed as the context network, pre-trained by the masked-reconstruction task on all available target data in a self-supervised way. Both the encoder and the context network are jointly fine-tuned in a semi-supervised manner. Furthermore, a global-local feature fusion strategy is proposed to enhance the localization capability. Evaluation of MAT-SED on DCASE2023 task4 surpasses state-of-the-art performance, achieving 0.587/0.896 PSDS1/PSDS2 respectively.