 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedOT: Ownership Verification and Leakage Tracing via Watermarks for Federated LDMs
Jun 22, 2026Training Latent Diffusion Models (LDMs) within Federated Learning (FL) has attracted increasing attention due to its ability to combine the powerful generative capacity of LDMs with the privacy-preserving properties of FL. However, FL requires sharing the global model with multiple participants, which risks unauthorized model distribution or resale by malicious clients. While an intuitive approach is to adopt existing VAE-based watermarking techniques for LDMs in FL, this strategy falls short in addressing such threats due to two fundamental challenges: (1) Existing methods support ownership verification but lack the ability to trace model leakage to a specific malicious client; (2) VAE-based watermarks are vulnerable, as they can be removed simply by replacing the decoder with a clean counterpart. In this paper, we propose FedOT, the first framework for ownership verification and leakage tracing in federated LDMs. Specifically, to address the first challenge, we design a chunked watermark, where the first part is for ownership verification, and the second part is used for client identification. Furthermore, to overcome the second challenge and secure the model against VAE replacement attack, we introduce Latent Vector Transformation (LVT), which strengthens the connection between the VAE and U-Net latent spaces by modifying the original latent distribution of the VAE. Consequently, any attempt to replace the VAE for watermark removal leads to significant image quality degradation, making the LDM model unusable. Extensive experiments demonstrate that FedOT achieves superior performance in both ownership verification and traceability. Project page: https://spyzixuan.github.io/FedOT/.
VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Jun 10, 2026Speculative decoding (SD) addresses the high inference costs of LLMs by having lightweight drafters generate candidates for large verifiers to validate in parallel. Existing draft-verify methods use binary decisions: accept or fully recompute. Yet we find that many rejected tokens can be verified correctly by a slim submodel derived from the full verifier via intra-model routing, instead of the full verifier. This motivates our slim-verifier to handle tokens requiring moderate verification resources, reducing expensive large-model calls. We propose Verification via Intra-Model Routing for Speculative Decoding (VIA-SD), a multi-tier framework using a routed slim-verifier. Draft tokens are processed hierarchically: direct acceptance for high-confidence cases, slim-verifier regeneration for medium-confidence cases, and full-model verification for uncertain cases. Across four representative tasks and multiple model families, VIA-SD reduces rejection rates by 0.10-0.22 and delivers 10-20% speedups over strong SD baselines, while achieving 2.5-3x acceleration over non-drafting decoding. Moreover, VIA-SD is compatible with existing SD frameworks without modifying their training procedures. Our results suggest multi-tier SD as a general paradigm for scalable and efficient LLM inference. Project page: https://zju-xyc.github.io/VIA-SD-Project-Page/
From 2D Grids to 1D Tokens: Reforming Shared Representations for Multimodal Image Fusion
Jun 10, 2026Multimodal image fusion aims to integrate complementary information from different modalities into a fused image that preserves rich local details while maintaining globally consistent appearance. Existing approaches build shared representations on 2D feature grids, which excel at modeling local structures but offer limited leverage over image-level global appearance factors. To balance these objectives, we introduce a compact 1D token interface based on a frozen pretrained image tokenizer for modeling non-local appearance/base factors. Rather than using the tokenizer as a reconstruction backbone, our design uses the 1D token space as a global carrier while retaining the 2D spatial pathway for local structure restoration. Specifically, we introduce Selective Token Editing (STE), which sparsely updates/replaces a small set of critical tokens, providing a lightweight mechanism to steer global appearance coherence while keeping the fusion backbone unchanged and avoiding extra losses. Experiments on four commonly used benchmarks show that our method achieves the best overall performance, with consistent, multi-metric improvements in both global coherence and local fidelity. Project page: https://zju-xyc.github.io/1D-Fusion-Project-Page/
UniSurgSAM: A Unified Promptable Model for Reliable Surgical Video Segmentation
Apr 04, 2026Surgical video segmentation is fundamental to computer-assisted surgery. In practice, surgeons need to dynamically specify targets throughout extended procedures, using heterogeneous cues such as visual selections, textual expressions, or audio instructions. However, existing Promptable Video Object Segmentation (PVOS) methods are typically restricted to a single prompt modality and rely on coupled frameworks that cause optimization interference between target initialization and tracking. Moreover, these methods produce hallucinated predictions when the target is absent and suffer from accumulated mask drift without failure recovery. To address these challenges, we present UniSurgSAM, a unified PVOS model enabling reliable surgical video segmentation through visual, textual, or audio prompts. Specifically, UniSurgSAM employs a decoupled two-stage framework that independently optimizes initialization and tracking to resolve the optimization interference. Within this framework, we introduce three key designs for reliability: presence-aware decoding that models target absence to suppress hallucinations; boundary-aware long-term tracking that prevents mask drift over extended sequences; and adaptive state transition that closes the loop between stages for failure recovery. Furthermore, we establish a multi-modal and multi-granular benchmark from four public surgical datasets with precise instance-level masklets. Extensive experiments demonstrate that UniSurgSAM achieves state-of-the-art performance in real time across all prompt modalities and granularities, providing a practical foundation for computer-assisted surgery. Code and datasets will be available at https://jinlab-imvr.github.io/UniSurgSAM.
Surg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
UniStitch: Unifying Semantic and Geometric Features for Image Stitching
Mar 11, 2026Traditional image stitching methods estimate warps from hand-crafted geometric features, whereas recent learning-based solutions leverage semantic features from neural networks instead. These two lines of research have largely diverged along separate evolution, with virtually no meaningful convergence to date. In this paper, we take a pioneering step to bridge this gap by unifying semantic and geometric features with UniStitch, a unified image stitching framework from multimodal features. To align discrete geometric features (i.e., keypoint) with continuous semantic feature maps, we present a Neural Point Transformer (NPT) module, which transforms unordered, sparse 1D geometric keypoints into ordered, dense 2D semantic maps. Then, to integrate the advantages of both representations, an Adaptive Mixture of Experts (AMoE) module is designed to fuse geometric and semantic representations. It dynamically shifts focus toward more reliable features during the fusion process, allowing the model to handle complex scenes, especially when either modality might be compromised. The fused representation can be adopted into common deep stitching pipelines, delivering significant performance gains over any single feature. Experiments show that UniStitch outperforms existing state-of-the-art methods with a large margin, paving the way for a unified paradigm between traditional and learning-based image stitching.
CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
Jan 05, 2026Despite significant progress, multimodal large language models continue to struggle with visual mathematical problem solving. Some recent works recognize that visual perception is a bottleneck in visual mathematical reasoning, but their solutions are limited to improving the extraction and interpretation of visual inputs. Notably, they all ignore the key issue of whether the extracted visual cues are faithfully integrated and properly utilized in subsequent reasoning. Motivated by this, we present CogFlow, a novel cognitive-inspired three-stage framework that incorporates a knowledge internalization stage, explicitly simulating the hierarchical flow of human reasoning: perception$\Rightarrow$internalization$\Rightarrow$reasoning. Inline with this hierarchical flow, we holistically enhance all its stages. We devise Synergistic Visual Rewards to boost perception capabilities in parametric and semantic spaces, jointly improving visual information extraction from symbols and diagrams. To guarantee faithful integration of extracted visual cues into subsequent reasoning, we introduce a Knowledge Internalization Reward model in the internalization stage, bridging perception and reasoning. Moreover, we design a Visual-Gated Policy Optimization algorithm to further enforce the reasoning is grounded with the visual knowledge, preventing models seeking shortcuts that appear coherent but are visually ungrounded reasoning chains. Moreover, we contribute a new dataset MathCog for model training, which contains samples with over 120K high-quality perception-reasoning aligned annotations. Comprehensive experiments and analysis on commonly used visual mathematical reasoning benchmarks validate the superiority of the proposed CogFlow.
Clear Nights Ahead: Towards Multi-Weather Nighttime Image Restoration
May 22, 2025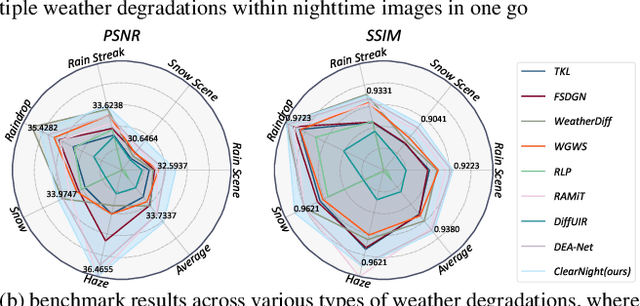



Restoring nighttime images affected by multiple adverse weather conditions is a practical yet under-explored research problem, as multiple weather conditions often coexist in the real world alongside various lighting effects at night. This paper first explores the challenging multi-weather nighttime image restoration task, where various types of weather degradations are intertwined with flare effects. To support the research, we contribute the AllWeatherNight dataset, featuring large-scale high-quality nighttime images with diverse compositional degradations, synthesized using our introduced illumination-aware degradation generation. Moreover, we present ClearNight, a unified nighttime image restoration framework, which effectively removes complex degradations in one go. Specifically, ClearNight extracts Retinex-based dual priors and explicitly guides the network to focus on uneven illumination regions and intrinsic texture contents respectively, thereby enhancing restoration effectiveness in nighttime scenarios. In order to better represent the common and unique characters of multiple weather degradations, we introduce a weather-aware dynamic specific-commonality collaboration method, which identifies weather degradations and adaptively selects optimal candidate units associated with specific weather types. Our ClearNight achieves state-of-the-art performance on both synthetic and real-world images. Comprehensive ablation experiments validate the necessity of AllWeatherNight dataset as well as the effectiveness of ClearNight. Project page: https://henlyta.github.io/ClearNight/mainpage.html
MathFlow: Enhancing the Perceptual Flow of MLLMs for Visual Mathematical Problems
Mar 19, 2025



Despite impressive performance across diverse tasks, Multimodal Large Language Models (MLLMs) have yet to fully demonstrate their potential in visual mathematical problem-solving, particularly in accurately perceiving and interpreting diagrams. Inspired by typical processes of humans, we hypothesize that the perception capabilities to extract meaningful information from diagrams is crucial, as it directly impacts subsequent inference processes. To validate this hypothesis, we developed FlowVerse, a comprehensive benchmark that categorizes all information used during problem-solving into four components, which are then combined into six problem versions for evaluation. Our preliminary results on FlowVerse reveal that existing MLLMs exhibit substantial limitations when extracting essential information and reasoned property from diagrams and performing complex reasoning based on these visual inputs. In response, we introduce MathFlow, a modular problem-solving pipeline that decouples perception and inference into distinct stages, thereby optimizing each independently. Given the perceptual limitations observed in current MLLMs, we trained MathFlow-P-7B as a dedicated perception model. Experimental results indicate that MathFlow-P-7B yields substantial performance gains when integrated with various closed-source and open-source inference models. This demonstrates the effectiveness of the MathFlow pipeline and its compatibility to diverse inference frameworks. The FlowVerse benchmark and code are available at https://github.com/MathFlow-zju/MathFlow.
MC-Bench: A Benchmark for Multi-Context Visual Grounding in the Era of MLLMs
Oct 16, 2024



While multimodal large language models (MLLMs) have demonstrated extraordinary vision-language understanding capabilities and shown potential to serve as general-purpose assistants, their abilities to solve instance-level visual-language problems beyond a single image warrant further exploration. In order to assess these unproven abilities of MLLMs, this paper proposes a new visual grounding task called multi-context visual grounding, which aims to localize instances of interest across multiple images based on open-ended text prompts. To facilitate this research, we meticulously construct a new dataset MC-Bench for benchmarking the visual grounding capabilities of MLLMs. MC-Bench features 2K high-quality and manually annotated samples, consisting of instance-level labeled image pairs and corresponding text prompts that indicate the target instances in the images. In total, there are three distinct styles of text prompts, covering 20 practical skills. We benchmark over 20 state-of-the-art MLLMs and foundation models with potential multi-context visual grounding capabilities. Our evaluation reveals a non-trivial performance gap between existing MLLMs and humans across all metrics. We also observe that existing MLLMs typically outperform foundation models without LLMs only on image-level metrics, and the specialist MLLMs trained on single images often struggle to generalize to multi-image scenarios. Moreover, a simple stepwise baseline integrating advanced MLLM and a detector can significantly surpass prior end-to-end MLLMs. We hope our MC-Bench and empirical findings can encourage the research community to further explore and enhance the untapped potentials of MLLMs in instance-level tasks, particularly in multi-image contexts. Project page: https://xuyunqiu.github.io/MC-Bench/.