 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStagePilot: A Deep Reinforcement Learning Agent for Stage-Controlled Cybergrooming Simulation
Feb 04, 2026Cybergrooming is an evolving threat to youth, necessitating proactive educational interventions. We propose StagePilot, an offline RL-based dialogue agent that simulates the stage-wise progression of grooming behaviors for prevention training. StagePilot selects conversational stages using a composite reward that balances user sentiment and goal proximity, with transitions constrained to adjacent stages for realism and interpretability. We evaluate StagePilot through LLM-based simulations, measuring stage completion, dialogue efficiency, and emotional engagement. Results show that StagePilot generates realistic and coherent conversations aligned with grooming dynamics. Among tested methods, the IQL+AWAC agent achieves the best balance between strategic planning and emotional coherence, reaching the final stage up to 43% more frequently than baselines while maintaining over 70% sentiment alignment.
LLM Can be a Dangerous Persuader: Empirical Study of Persuasion Safety in Large Language Models
Apr 14, 2025



Recent advancements in Large Language Models (LLMs) have enabled them to approach human-level persuasion capabilities. However, such potential also raises concerns about the safety risks of LLM-driven persuasion, particularly their potential for unethical influence through manipulation, deception, exploitation of vulnerabilities, and many other harmful tactics. In this work, we present a systematic investigation of LLM persuasion safety through two critical aspects: (1) whether LLMs appropriately reject unethical persuasion tasks and avoid unethical strategies during execution, including cases where the initial persuasion goal appears ethically neutral, and (2) how influencing factors like personality traits and external pressures affect their behavior. To this end, we introduce PersuSafety, the first comprehensive framework for the assessment of persuasion safety which consists of three stages, i.e., persuasion scene creation, persuasive conversation simulation, and persuasion safety assessment. PersuSafety covers 6 diverse unethical persuasion topics and 15 common unethical strategies. Through extensive experiments across 8 widely used LLMs, we observe significant safety concerns in most LLMs, including failing to identify harmful persuasion tasks and leveraging various unethical persuasion strategies. Our study calls for more attention to improve safety alignment in progressive and goal-driven conversations such as persuasion.
Advancing Human-Machine Teaming: Concepts, Challenges, and Applications
Mar 16, 2025Human-Machine Teaming (HMT) is revolutionizing collaboration across domains such as defense, healthcare, and autonomous systems by integrating AI-driven decision-making, trust calibration, and adaptive teaming. This survey presents a comprehensive taxonomy of HMT, analyzing theoretical models, including reinforcement learning, instance-based learning, and interdependence theory, alongside interdisciplinary methodologies. Unlike prior reviews, we examine team cognition, ethical AI, multi-modal interactions, and real-world evaluation frameworks. Key challenges include explainability, role allocation, and scalable benchmarking. We propose future research in cross-domain adaptation, trust-aware AI, and standardized testbeds. By bridging computational and social sciences, this work lays a foundation for resilient, ethical, and scalable HMT systems.
CounterQuill: Investigating the Potential of Human-AI Collaboration in Online Counterspeech Writing
Oct 03, 2024



Online hate speech has become increasingly prevalent on social media platforms, causing harm to individuals and society. While efforts have been made to combat this issue through content moderation, the potential of user-driven counterspeech as an alternative solution remains underexplored. Existing counterspeech methods often face challenges such as fear of retaliation and skill-related barriers. To address these challenges, we introduce CounterQuill, an AI-mediated system that assists users in composing effective and empathetic counterspeech. CounterQuill provides a three-step process: (1) a learning session to help users understand hate speech and counterspeech; (2) a brainstorming session that guides users in identifying key elements of hate speech and exploring counterspeech strategies; and (3) a co-writing session that enables users to draft and refine their counterspeech with CounterQuill. We conducted a within-subjects user study with 20 participants to evaluate CounterQuill in comparison to ChatGPT. Results show that CounterQuill's guidance and collaborative writing process provided users a stronger sense of ownership over their co-authored counterspeech. Users perceived CounterQuill as a writing partner and thus were more willing to post the co-written counterspeech online compared to the one written with ChatGPT.
Investigating Characteristics of Media Recommendation Solicitation in r/ifyoulikeblank
Aug 12, 2024



Despite the existence of search-based recommender systems like Google, Netflix, and Spotify, online users sometimes may turn to crowdsourced recommendations in places like the r/ifyoulikeblank subreddit. In this exploratory study, we probe why users go to r/ifyoulikeblank, how they look for recommendation, and how the subreddit users respond to recommendation requests. To answer, we collected sample posts from r/ifyoulikeblank and analyzed them using a qualitative approach. Our analysis reveals that users come to this subreddit for various reasons, such as exhausting popular search systems, not knowing what or how to search for an item, and thinking crowd have better knowledge than search systems. Examining users query and their description, we found novel information users provide during recommendation seeking using r/ifyoulikeblank. For example, sometimes they ask for artifacts recommendation based on the tools used to create them. Or, sometimes indicating a recommendation seeker's time constraints can help better suit recommendations to their needs. Finally, recommendation responses and interactions revealed patterns of how requesters and responders refine queries and recommendations. Our work informs future intelligent recommender systems design.
Darwin's Neural Network: AI-based Strategies for Rapid and Scalable Cell and Coronavirus Screening
Jul 22, 2020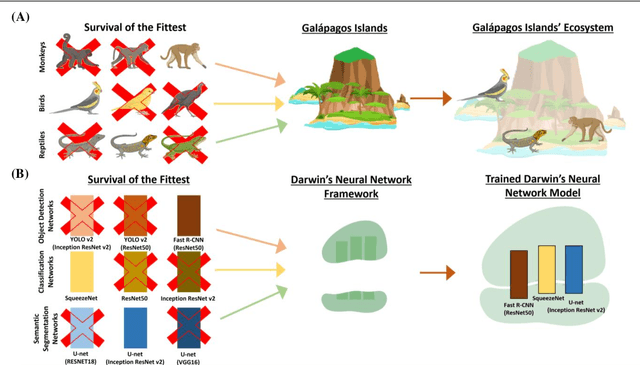
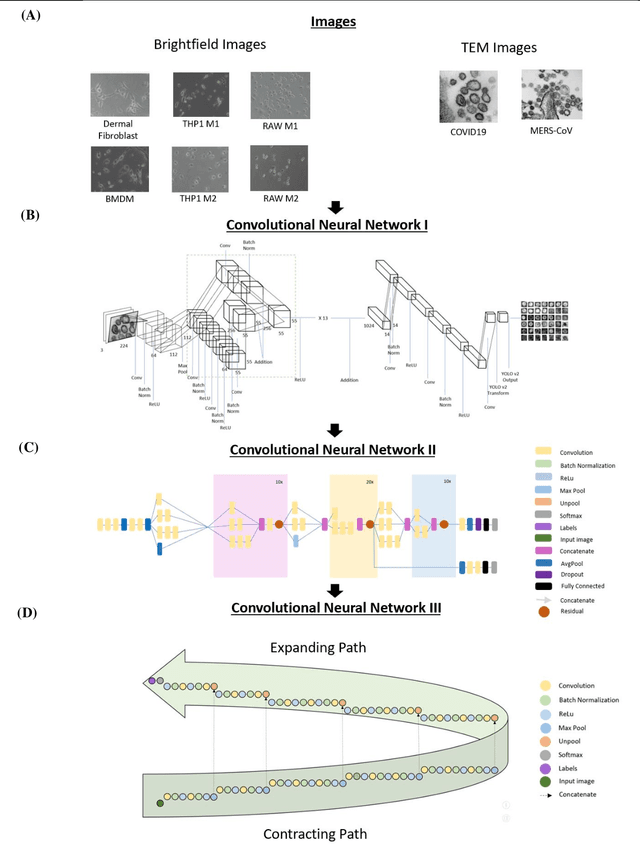
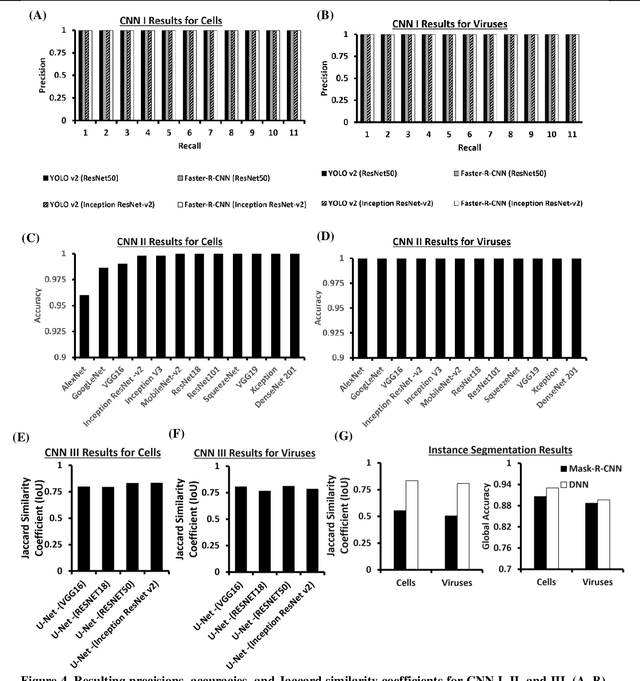
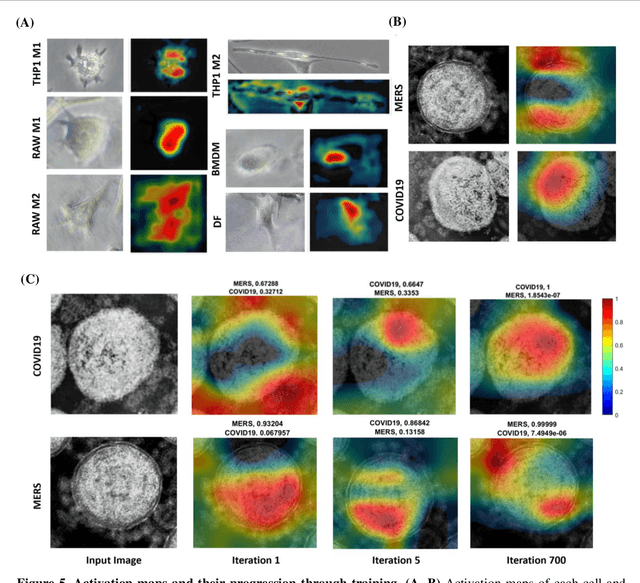
Recent advances in the interdisciplinary scientific field of machine perception, computer vision, and biomedical engineering underpin a collection of machine learning algorithms with a remarkable ability to decipher the contents of microscope and nanoscope images. Machine learning algorithms are transforming the interpretation and analysis of microscope and nanoscope imaging data through use in conjunction with biological imaging modalities. These advances are enabling researchers to carry out real-time experiments that were previously thought to be computationally impossible. Here we adapt the theory of survival of the fittest in the field of computer vision and machine perception to introduce a new framework of multi-class instance segmentation deep learning, Darwin's Neural Network (DNN), to carry out morphometric analysis and classification of COVID19 and MERS-CoV collected in vivo and of multiple mammalian cell types in vitro.