 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Augmented Generation Evaluation in the Era of Large Language Models: A Comprehensive Survey
Apr 21, 2025



Recent advancements in Retrieval-Augmented Generation (RAG) have revolutionized natural language processing by integrating Large Language Models (LLMs) with external information retrieval, enabling accurate, up-to-date, and verifiable text generation across diverse applications. However, evaluating RAG systems presents unique challenges due to their hybrid architecture that combines retrieval and generation components, as well as their dependence on dynamic knowledge sources in the LLM era. In response, this paper provides a comprehensive survey of RAG evaluation methods and frameworks, systematically reviewing traditional and emerging evaluation approaches, for system performance, factual accuracy, safety, and computational efficiency in the LLM era. We also compile and categorize the RAG-specific datasets and evaluation frameworks, conducting a meta-analysis of evaluation practices in high-impact RAG research. To the best of our knowledge, this work represents the most comprehensive survey for RAG evaluation, bridging traditional and LLM-driven methods, and serves as a critical resource for advancing RAG development.
The Other Side of the Coin: Exploring Fairness in Retrieval-Augmented Generation
Apr 19, 2025Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by retrieving relevant document from external knowledge sources. By referencing this external knowledge, RAG effectively reduces the generation of factually incorrect content and addresses hallucination issues within LLMs. Recently, there has been growing attention to improving the performance and efficiency of RAG systems from various perspectives. While these advancements have yielded significant results, the application of RAG in domains with considerable societal implications raises a critical question about fairness: What impact does the introduction of the RAG paradigm have on the fairness of LLMs? To address this question, we conduct extensive experiments by varying the LLMs, retrievers, and retrieval sources. Our experimental analysis reveals that the scale of the LLMs plays a significant role in influencing fairness outcomes within the RAG framework. When the model scale is smaller than 8B, the integration of retrieval mechanisms often exacerbates unfairness in small-scale LLMs (e.g., LLaMA3.2-1B, Mistral-7B, and LLaMA3-8B). To mitigate the fairness issues introduced by RAG for small-scale LLMs, we propose two approaches, FairFT and FairFilter. Specifically, in FairFT, we align the retriever with the LLM in terms of fairness, enabling it to retrieve documents that facilitate fairer model outputs. In FairFilter, we propose a fairness filtering mechanism to filter out biased content after retrieval. Finally, we validate our proposed approaches on real-world datasets, demonstrating their effectiveness in improving fairness while maintaining performance.
Refining Sentence Embedding Model through Ranking Sentences Generation with Large Language Models
Feb 19, 2025Sentence embedding is essential for many NLP tasks, with contrastive learning methods achieving strong performance using annotated datasets like NLI. Yet, the reliance on manual labels limits scalability. Recent studies leverage large language models (LLMs) to generate sentence pairs, reducing annotation dependency. However, they overlook ranking information crucial for fine-grained semantic distinctions. To tackle this challenge, we propose a method for controlling the generation direction of LLMs in the latent space. Unlike unconstrained generation, the controlled approach ensures meaningful semantic divergence. Then, we refine exist sentence embedding model by integrating ranking information and semantic information. Experiments on multiple benchmarks demonstrate that our method achieves new SOTA performance with a modest cost in ranking sentence synthesis.
Unveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
Feb 17, 2025The reasoning abilities are one of the most enigmatic and captivating aspects of large language models (LLMs). Numerous studies are dedicated to exploring and expanding the boundaries of this reasoning capability. However, tasks that embody both reasoning and recall characteristics are often overlooked. In this paper, we introduce such a novel task, code reasoning, to provide a new perspective for the reasoning abilities of LLMs. We summarize three meta-benchmarks based on established forms of logical reasoning, and instantiate these into eight specific benchmark tasks. Our testing on these benchmarks reveals that LLMs continue to struggle with identifying satisfactory reasoning pathways. Additionally, we present a new pathway exploration pipeline inspired by human intricate problem-solving methods. This Reflective Hypothesis Decomposition and Amendment (RHDA) pipeline consists of the following iterative steps: (1) Proposing potential hypotheses based on observations and decomposing them; (2) Utilizing tools to validate hypotheses and reflection outcomes; (3) Revising hypothesis in light of observations. Our approach effectively mitigates logical chain collapses arising from forgetting or hallucination issues in multi-step reasoning, resulting in performance gains of up to $3\times$. Finally, we expanded this pipeline by applying it to simulate complex household tasks in real-world scenarios, specifically in VirtualHome, enhancing the handling of failure cases. We release our code and all of results at https://github.com/TnTWoW/code_reasoning.
Agent4Edu: Generating Learner Response Data by Generative Agents for Intelligent Education Systems
Jan 17, 2025



Personalized learning represents a promising educational strategy within intelligent educational systems, aiming to enhance learners' practice efficiency. However, the discrepancy between offline metrics and online performance significantly impedes their progress. To address this challenge, we introduce Agent4Edu, a novel personalized learning simulator leveraging recent advancements in human intelligence through large language models (LLMs). Agent4Edu features LLM-powered generative agents equipped with learner profile, memory, and action modules tailored to personalized learning algorithms. The learner profiles are initialized using real-world response data, capturing practice styles and cognitive factors. Inspired by human psychology theory, the memory module records practice facts and high-level summaries, integrating reflection mechanisms. The action module supports various behaviors, including exercise understanding, analysis, and response generation. Each agent can interact with personalized learning algorithms, such as computerized adaptive testing, enabling a multifaceted evaluation and enhancement of customized services. Through a comprehensive assessment, we explore the strengths and weaknesses of Agent4Edu, emphasizing the consistency and discrepancies in responses between agents and human learners. The code, data, and appendix are publicly available at https://github.com/bigdata-ustc/Agent4Edu.
A Flexible Plug-and-Play Module for Generating Variable-Length
Dec 12, 2024Deep supervised hashing has become a pivotal technique in large-scale image retrieval, offering significant benefits in terms of storage and search efficiency. However, existing deep supervised hashing models predominantly focus on generating fixed-length hash codes. This approach fails to address the inherent trade-off between efficiency and effectiveness when using hash codes of varying lengths. To determine the optimal hash code length for a specific task, multiple models must be trained for different lengths, leading to increased training time and computational overhead. Furthermore, the current paradigm overlooks the potential relationships between hash codes of different lengths, limiting the overall effectiveness of the models. To address these challenges, we propose the Nested Hash Layer (NHL), a plug-and-play module designed for existing deep supervised hashing models. The NHL framework introduces a novel mechanism to simultaneously generate hash codes of varying lengths in a nested manner. To tackle the optimization conflicts arising from the multiple learning objectives associated with different code lengths, we further propose an adaptive weights strategy that dynamically monitors and adjusts gradients during training. Additionally, recognizing that the structural information in longer hash codes can provide valuable guidance for shorter hash codes, we develop a long-short cascade self-distillation method within the NHL to enhance the overall quality of the generated hash codes. Extensive experiments demonstrate that NHL not only accelerates the training process but also achieves superior retrieval performance across various deep hashing models. Our code is publicly available at https://github.com/hly1998/NHL.
What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
Dec 11, 2024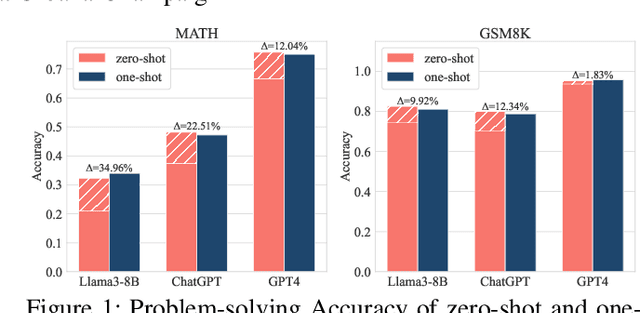



Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
RePair: Automated Program Repair with Process-based Feedback
Aug 21, 2024



The gap between the trepidation of program reliability and the expense of repairs underscores the indispensability of Automated Program Repair (APR). APR is instrumental in transforming vulnerable programs into more robust ones, bolstering program reliability while simultaneously diminishing the financial burden of manual repairs. Commercial-scale language models (LM) have taken APR to unprecedented levels. However, the emergence reveals that for models fewer than 100B parameters, making single-step modifications may be difficult to achieve the desired effect. Moreover, humans interact with the LM through explicit prompts, which hinders the LM from receiving feedback from compiler and test cases to automatically optimize its repair policies. In this literature, we explore how small-scale LM (less than 20B) achieve excellent performance through process supervision and feedback. We start by constructing a dataset named CodeNet4Repair, replete with multiple repair records, which supervises the fine-tuning of a foundational model. Building upon the encouraging outcomes of reinforcement learning, we develop a reward model that serves as a critic, providing feedback for the fine-tuned LM's action, progressively optimizing its policy. During inference, we require the LM to generate solutions iteratively until the repair effect no longer improves or hits the maximum step limit. The results show that process-based not only outperforms larger outcome-based generation methods, but also nearly matches the performance of closed-source commercial large-scale LMs.
* 15 pages, 13 figures
A Survey of Models for Cognitive Diagnosis: New Developments and Future Directions
Jul 07, 2024



Cognitive diagnosis has been developed for decades as an effective measurement tool to evaluate human cognitive status such as ability level and knowledge mastery. It has been applied to a wide range of fields including education, sport, psychological diagnosis, etc. By providing better awareness of cognitive status, it can serve as the basis for personalized services such as well-designed medical treatment, teaching strategy and vocational training. This paper aims to provide a survey of current models for cognitive diagnosis, with more attention on new developments using machine learning-based methods. By comparing the model structures, parameter estimation algorithms, model evaluation methods and applications, we provide a relatively comprehensive review of the recent trends in cognitive diagnosis models. Further, we discuss future directions that are worthy of exploration. In addition, we release two Python libraries: EduData for easy access to some relevant public datasets we have collected, and EduCDM that implements popular CDMs to facilitate both applications and research purposes.
EduNLP: Towards a Unified and Modularized Library for Educational Resources
Jun 04, 2024



Educational resource understanding is vital to online learning platforms, which have demonstrated growing applications recently. However, researchers and developers always struggle with using existing general natural language toolkits or domain-specific models. The issue raises a need to develop an effective and easy-to-use one that benefits AI education-related research and applications. To bridge this gap, we present a unified, modularized, and extensive library, EduNLP, focusing on educational resource understanding. In the library, we decouple the whole workflow to four key modules with consistent interfaces including data configuration, processing, model implementation, and model evaluation. We also provide a configurable pipeline to unify the data usage and model usage in standard ways, where users can customize their own needs. For the current version, we primarily provide 10 typical models from four categories, and 5 common downstream-evaluation tasks in the education domain on 8 subjects for users' usage. The project is released at: https://github.com/bigdata-ustc/EduNLP.