 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
May 19, 2026LLM agents organize behavior through skills - structured natural-language specifications governing how an agent reasons, retrieves, and responds. Unlike monolithic prompts, skills are multi-field artifacts subject to hard platform constraints: description fields are truncated for routing, instruction bodies are compacted via progressive disclosure, and co-resident skills compete for limited context windows. These constraints make skill optimization inherently multi-objective: a skill must simultaneously maximize task performance and satisfy platform limits. Yet existing prompt optimizers either ignore these trade-offs or collapse them into a weighted sum, missing Pareto-optimal variants in non-convex objective regions. We introduce MOCHA (Multi-Objective Chebyshev Annealing), which replaces single-objective selection with Chebyshev scalarization - covering the full Pareto front, including non-convex regions - combined with exponential annealing that transitions from exploration to exploitation. In our experiments across six diverse agent skills - where all methods share the same multi-objective mutation operator and baselines receive identical per-objective textual feedback - existing optimizers fail to improve the seed skill on 4 of 6 tasks: 1000 rollouts yield zero progress. MOCHA breaks through on every task, achieving 7.5% relative improvement in mean correctness over the strongest baseline (up to 14.9% on FEVER and 10.4% on TheoremQA) while discovering twice as many more Pareto-optimal skill variants.
CAPO: Counterfactual Credit Assignment in Sequential Cooperative Teams
Apr 20, 2026In cooperative teams where agents act in a fixed order and share a single team reward, it is hard to know how much each agent contributed, and harder still when agents are updated one at a time because data collected earlier no longer reflects the new policies. We introduce the Sequential Aristocrat Utility (SeqAU), the unique per-agent learning signal that maximizes the individual learnability of each agent's action, extending the classical framework of Wolpert and Tumer (2002) to this sequential setting. From SeqAU we derive CAPO (Counterfactual Advantage Policy Optimization), a critic-free policy-gradient algorithm. CAPO fits a per-agent reward decomposition from group rewards and computes the per-agent advantage in closed form plus a handful of forward passes through the current policy, requiring no extra environment calls beyond the initial batch. We give analytic bias and variance bounds and validate them on a controlled sequential bandit, where CAPO's advantage over standard baselines grows with the team size. The framework is general; multi-LLM pipelines are a natural deployment target.
Rethinking Failure Attribution in Multi-Agent Systems: A Multi-Perspective Benchmark and Evaluation
Mar 26, 2026Failure attribution is essential for diagnosing and improving multi-agent systems (MAS), yet existing benchmarks and methods largely assume a single deterministic root cause for each failure. In practice, MAS failures often admit multiple plausible attributions due to complex inter-agent dependencies and ambiguous execution trajectories. We revisit MAS failure attribution from a multi-perspective standpoint and propose multi-perspective failure attribution, a practical paradigm that explicitly accounts for attribution ambiguity. To support this setting, we introduce MP-Bench, the first benchmark designed for multi-perspective failure attribution in MAS, along with a new evaluation protocol tailored to this paradigm. Through extensive experiments, we find that prior conclusions suggesting LLMs struggle with failure attribution are largely driven by limitations in existing benchmark designs. Our results highlight the necessity of multi-perspective benchmarks and evaluation protocols for realistic and reliable MAS debugging.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025



Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
Behavior Optimized Image Generation
Nov 18, 2023



The last few years have witnessed great success on image generation, which has crossed the acceptance thresholds of aesthetics, making it directly applicable to personal and commercial applications. However, images, especially in marketing and advertising applications, are often created as a means to an end as opposed to just aesthetic concerns. The goal can be increasing sales, getting more clicks, likes, or image sales (in the case of stock businesses). Therefore, the generated images need to perform well on these key performance indicators (KPIs), in addition to being aesthetically good. In this paper, we make the first endeavor to answer the question of "How can one infuse the knowledge of the end-goal within the image generation process itself to create not just better-looking images but also "better-performing'' images?''. We propose BoigLLM, an LLM that understands both image content and user behavior. BoigLLM knows how an image should look to get a certain required KPI. We show that BoigLLM outperforms 13x larger models such as GPT-3.5 and GPT-4 in this task, demonstrating that while these state-of-the-art models can understand images, they lack information on how these images perform in the real world. To generate actual pixels of behavior-conditioned images, we train a diffusion-based model (BoigSD) to align with a proposed BoigLLM-defined reward. We show the performance of the overall pipeline on two datasets covering two different behaviors: a stock dataset with the number of forward actions as the KPI and a dataset containing tweets with the total likes as the KPI, denoted as BoigBench. To advance research in the direction of utility-driven image generation and understanding, we release BoigBench, a benchmark dataset containing 168 million enterprise tweets with their media, brand account names, time of post, and total likes.
Counterfactual Explanation Policies in RL
Jul 25, 2023



As Reinforcement Learning (RL) agents are increasingly employed in diverse decision-making problems using reward preferences, it becomes important to ensure that policies learned by these frameworks in mapping observations to a probability distribution of the possible actions are explainable. However, there is little to no work in the systematic understanding of these complex policies in a contrastive manner, i.e., what minimal changes to the policy would improve/worsen its performance to a desired level. In this work, we present COUNTERPOL, the first framework to analyze RL policies using counterfactual explanations in the form of minimal changes to the policy that lead to the desired outcome. We do so by incorporating counterfactuals in supervised learning in RL with the target outcome regulated using desired return. We establish a theoretical connection between Counterpol and widely used trust region-based policy optimization methods in RL. Extensive empirical analysis shows the efficacy of COUNTERPOL in generating explanations for (un)learning skills while keeping close to the original policy. Our results on five different RL environments with diverse state and action spaces demonstrate the utility of counterfactual explanations, paving the way for new frontiers in designing and developing counterfactual policies.
SARC: Soft Actor Retrospective Critic
Jun 28, 2023



The two-time scale nature of SAC, which is an actor-critic algorithm, is characterised by the fact that the critic estimate has not converged for the actor at any given time, but since the critic learns faster than the actor, it ensures eventual consistency between the two. Various strategies have been introduced in literature to learn better gradient estimates to help achieve better convergence. Since gradient estimates depend upon the critic, we posit that improving the critic can provide a better gradient estimate for the actor at each time. Utilizing this, we propose Soft Actor Retrospective Critic (SARC), where we augment the SAC critic loss with another loss term - retrospective loss - leading to faster critic convergence and consequently, better policy gradient estimates for the actor. An existing implementation of SAC can be easily adapted to SARC with minimal modifications. Through extensive experimentation and analysis, we show that SARC provides consistent improvement over SAC on benchmark environments. We plan to open-source the code and all experiment data at: https://github.com/sukritiverma1996/SARC.
Explaining RL Decisions with Trajectories
May 06, 2023



Explanation is a key component for the adoption of reinforcement learning (RL) in many real-world decision-making problems. In the literature, the explanation is often provided by saliency attribution to the features of the RL agent's state. In this work, we propose a complementary approach to these explanations, particularly for offline RL, where we attribute the policy decisions of a trained RL agent to the trajectories encountered by it during training. To do so, we encode trajectories in offline training data individually as well as collectively (encoding a set of trajectories). We then attribute policy decisions to a set of trajectories in this encoded space by estimating the sensitivity of the decision with respect to that set. Further, we demonstrate the effectiveness of the proposed approach in terms of quality of attributions as well as practical scalability in diverse environments that involve both discrete and continuous state and action spaces such as grid-worlds, video games (Atari) and continuous control (MuJoCo). We also conduct a human study on a simple navigation task to observe how their understanding of the task compares with data attributed for a trained RL policy. Keywords -- Explainable AI, Verifiability of AI Decisions, Explainable RL.
Differentiable Agent-based Epidemiology
Jul 20, 2022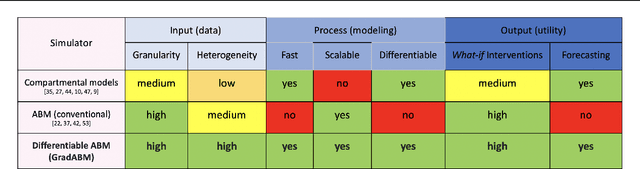
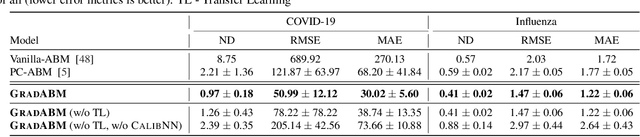
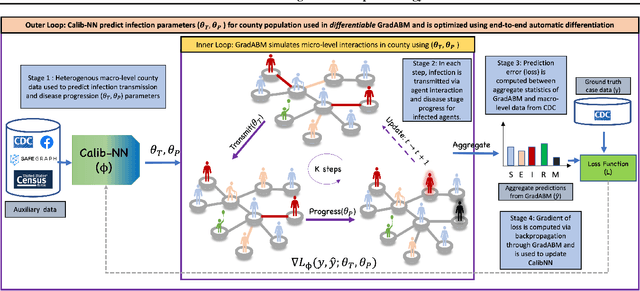

Mechanistic simulators are an indispensable tool for epidemiology to explore the behavior of complex, dynamic infections under varying conditions and navigate uncertain environments. ODE-based models are the dominant paradigm that enable fast simulations and are tractable to gradient-based optimization, but make simplifying assumptions about population homogeneity. Agent-based models (ABMs) are an increasingly popular alternative paradigm that can represent the heterogeneity of contact interactions with granular detail and agency of individual behavior. However, conventional ABM frameworks are not differentiable and present challenges in scalability; due to which it is non-trivial to connect them to auxiliary data sources easily. In this paper we introduce GradABM which is a new scalable, fast and differentiable design for ABMs. GradABM runs simulations in few seconds on commodity hardware and enables fast forward and differentiable inverse simulations. This makes it amenable to be merged with deep neural networks and seamlessly integrate heterogeneous data sources to help with calibration, forecasting and policy evaluation. We demonstrate the efficacy of GradABM via extensive experiments with real COVID-19 and influenza datasets. We are optimistic this work will bring ABM and AI communities closer together.