 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
May 16, 2025



Editing images using natural language instructions has become a natural and expressive way to modify visual content; yet, evaluating the performance of such models remains challenging. Existing evaluation approaches often rely on image-text similarity metrics like CLIP, which lack precision. In this work, we introduce a new benchmark designed to evaluate text-guided image editing models in a more grounded manner, along two critical dimensions: (i) functional correctness, assessed via automatically generated multiple-choice questions that verify whether the intended change was successfully applied; and (ii) image content preservation, which ensures that non-targeted regions of the image remain visually consistent using an object-aware masking technique and preservation scoring. The benchmark includes over 1000 high-quality editing examples across 20 diverse content categories, each annotated with detailed editing instructions, evaluation questions, and spatial object masks. We conduct a large-scale study comparing GPT-Image-1, the latest flagship in the text-guided image editing space, against several state-of-the-art editing models, and validate our automatic metrics against human ratings. Results show that GPT-Image-1 leads in instruction-following accuracy, but often over-modifies irrelevant image regions, highlighting a key trade-off in the current model behavior. GIE-Bench provides a scalable, reproducible framework for advancing more accurate evaluation of text-guided image editing.
CLIP-UP: A Simple and Efficient Mixture-of-Experts CLIP Training Recipe with Sparse Upcycling
Feb 03, 2025



Mixture-of-Experts (MoE) models are crucial for scaling model capacity while controlling inference costs. While integrating MoE into multimodal models like CLIP improves performance, training these models is notoriously challenging and expensive. We propose CLIP-Upcycling (CLIP-UP), an efficient alternative training strategy that converts a pre-trained dense CLIP model into a sparse MoE architecture. Through extensive experimentation with various settings and auxiliary losses, we demonstrate that CLIP-UP significantly reduces training complexity and cost. Remarkably, our sparse CLIP B/16 model, trained with CLIP-UP, outperforms its dense counterpart by 7.2% and 6.6% on COCO and Flickr30k text-to-image Recall@1 benchmarks respectively. It even surpasses the larger CLIP L/14 model on this task while using only 30% of the inference FLOPs. We further demonstrate the generalizability of our training recipe across different scales, establishing sparse upcycling as a practical and scalable approach for building efficient, high-performance CLIP models.
Contrastive Localized Language-Image Pre-Training
Oct 03, 2024



Contrastive Language-Image Pre-training (CLIP) has been a celebrated method for training vision encoders to generate image/text representations facilitating various applications. Recently, CLIP has been widely adopted as the vision backbone of multimodal large language models (MLLMs) to connect image inputs for language interactions. The success of CLIP as a vision-language foundation model relies on aligning web-crawled noisy text annotations at image levels. Nevertheless, such criteria may become insufficient for downstream tasks in need of fine-grained vision representations, especially when region-level understanding is demanding for MLLMs. In this paper, we improve the localization capability of CLIP with several advances. We propose a pre-training method called Contrastive Localized Language-Image Pre-training (CLOC) by complementing CLIP with region-text contrastive loss and modules. We formulate a new concept, promptable embeddings, of which the encoder produces image embeddings easy to transform into region representations given spatial hints. To support large-scale pre-training, we design a visually-enriched and spatially-localized captioning framework to effectively generate region-text pseudo-labels at scale. By scaling up to billions of annotated images, CLOC enables high-quality regional embeddings for image region recognition and retrieval tasks, and can be a drop-in replacement of CLIP to enhance MLLMs, especially on referring and grounding tasks.
Video Content Swapping Using GAN
Nov 21, 2021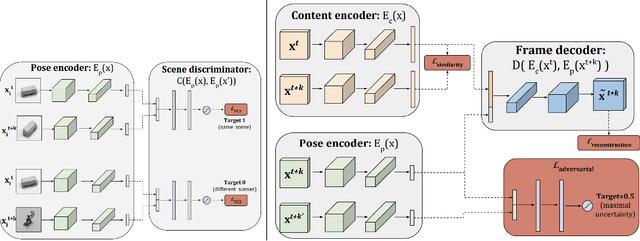
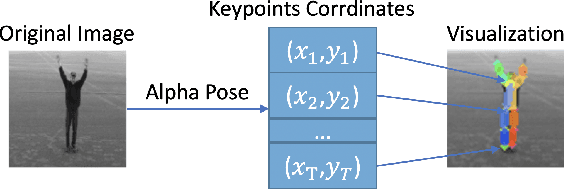
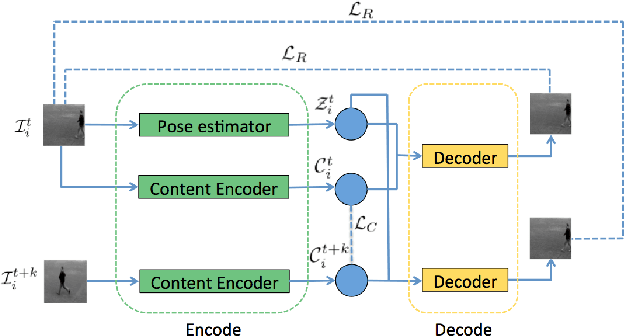
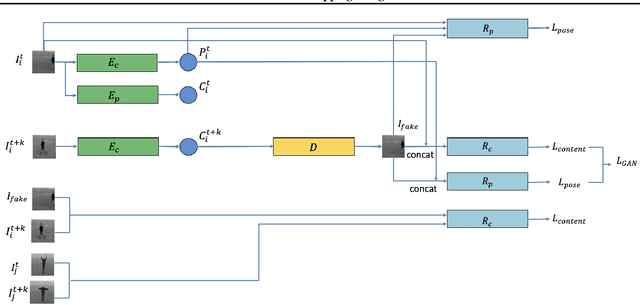
Video generation is an interesting problem in computer vision. It is quite popular for data augmentation, special effect in move, AR/VR and so on. With the advances of deep learning, many deep generative models have been proposed to solve this task. These deep generative models provide away to utilize all the unlabeled images and videos online, since it can learn deep feature representations with unsupervised manner. These models can also generate different kinds of images, which have great value for visual application. However generating a video would be much more challenging since we need to model not only the appearances of objects in the video but also their temporal motion. In this work, we will break down any frame in the video into content and pose. We first extract the pose information from a video using a pre-trained human pose detection and use a generative model to synthesize the video based on the content code and pose code.