 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards
May 19, 2025Large Language Models (LLMs) show great promise in complex reasoning, with Reinforcement Learning with Verifiable Rewards (RLVR) being a key enhancement strategy. However, a prevalent issue is ``superficial self-reflection'', where models fail to robustly verify their own outputs. We introduce RISE (Reinforcing Reasoning with Self-Verification), a novel online RL framework designed to tackle this. RISE explicitly and simultaneously trains an LLM to improve both its problem-solving and self-verification abilities within a single, integrated RL process. The core mechanism involves leveraging verifiable rewards from an outcome verifier to provide on-the-fly feedback for both solution generation and self-verification tasks. In each iteration, the model generates solutions, then critiques its own on-policy generated solutions, with both trajectories contributing to the policy update. Extensive experiments on diverse mathematical reasoning benchmarks show that RISE consistently improves model's problem-solving accuracy while concurrently fostering strong self-verification skills. Our analyses highlight the advantages of online verification and the benefits of increased verification compute. Additionally, RISE models exhibit more frequent and accurate self-verification behaviors during reasoning. These advantages reinforce RISE as a flexible and effective path towards developing more robust and self-aware reasoners.
Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
May 01, 2025



Assessing how well a large language model (LLM) understands human, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM's higher-order social cognition. SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations. At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts. Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity. We also build a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena). SAGE thus provides a principled, scalable and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
Apr 27, 2025Evaluating the step-by-step reliability of large language model (LLM) reasoning, such as Chain-of-Thought, remains challenging due to the difficulty and cost of obtaining high-quality step-level supervision. In this paper, we introduce Self-Play Critic (SPC), a novel approach where a critic model evolves its ability to assess reasoning steps through adversarial self-play games, eliminating the need for manual step-level annotation. SPC involves fine-tuning two copies of a base model to play two roles, namely a "sneaky generator" that deliberately produces erroneous steps designed to be difficult to detect, and a "critic" that analyzes the correctness of reasoning steps. These two models engage in an adversarial game in which the generator aims to fool the critic, while the critic model seeks to identify the generator's errors. Using reinforcement learning based on the game outcomes, the models iteratively improve; the winner of each confrontation receives a positive reward and the loser receives a negative reward, driving continuous self-evolution. Experiments on three reasoning process benchmarks (ProcessBench, PRM800K, DeltaBench) demonstrate that our SPC progressively enhances its error detection capabilities (e.g., accuracy increases from 70.8% to 77.7% on ProcessBench) and surpasses strong baselines, including distilled R1 model. Furthermore, applying SPC to guide the test-time search of diverse LLMs significantly improves their mathematical reasoning performance on MATH500 and AIME2024, outperforming state-of-the-art process reward models.
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
Apr 15, 2025



The capacity for complex mathematical reasoning is a key benchmark for artificial intelligence. While reinforcement learning (RL) applied to LLMs shows promise, progress is significantly hindered by the lack of large-scale training data that is sufficiently challenging, possesses verifiable answer formats suitable for RL, and is free from contamination with evaluation benchmarks. To address these limitations, we introduce DeepMath-103K, a new, large-scale dataset comprising approximately 103K mathematical problems, specifically designed to train advanced reasoning models via RL. DeepMath-103K is curated through a rigorous pipeline involving source analysis, stringent decontamination against numerous benchmarks, and filtering for high difficulty (primarily Levels 5-9), significantly exceeding existing open resources in challenge. Each problem includes a verifiable final answer, enabling rule-based RL, and three distinct R1-generated solutions suitable for diverse training paradigms like supervised fine-tuning or distillation. Spanning a wide range of mathematical topics, DeepMath-103K promotes the development of generalizable reasoning. We demonstrate that models trained on DeepMath-103K achieve significant improvements on challenging mathematical benchmarks, validating its effectiveness. We release DeepMath-103K publicly to facilitate community progress in building more capable AI reasoning systems: https://github.com/zwhe99/DeepMath.
Crossing the Reward Bridge: Expanding RL with Verifiable Rewards Across Diverse Domains
Apr 01, 2025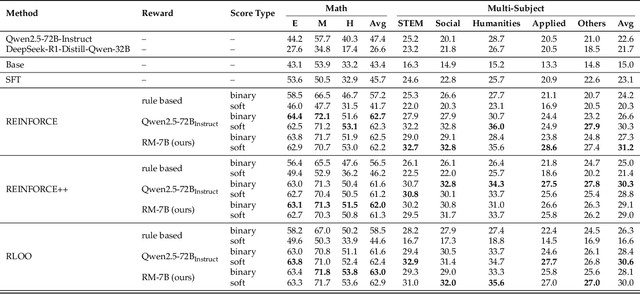
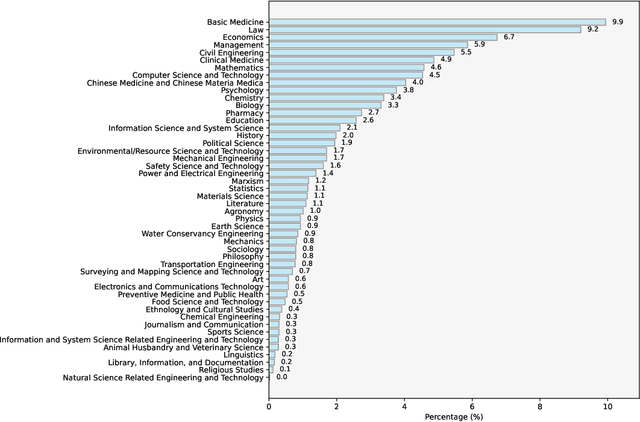
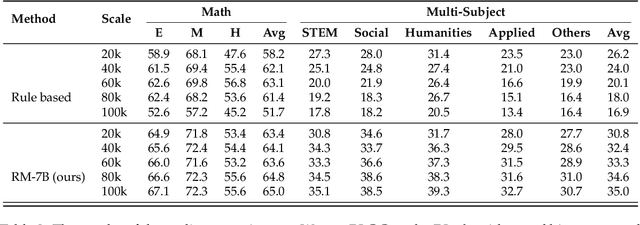

Reinforcement learning with verifiable rewards (RLVR) has demonstrated significant success in enhancing mathematical reasoning and coding performance of large language models (LLMs), especially when structured reference answers are accessible for verification. However, its extension to broader, less structured domains remains unexplored. In this work, we investigate the effectiveness and scalability of RLVR across diverse real-world domains including medicine, chemistry, psychology, economics, and education, where structured reference answers are typically unavailable. We reveal that binary verification judgments on broad-domain tasks exhibit high consistency across various LLMs provided expert-written reference answers exist. Motivated by this finding, we utilize a generative scoring technique that yields soft, model-based reward signals to overcome limitations posed by binary verifications, especially in free-form, unstructured answer scenarios. We further demonstrate the feasibility of training cross-domain generative reward models using relatively small (7B) LLMs without the need for extensive domain-specific annotation. Through comprehensive experiments, our RLVR framework establishes clear performance gains, significantly outperforming state-of-the-art open-source aligned models such as Qwen2.5-72B and DeepSeek-R1-Distill-Qwen-32B across domains in free-form settings. Our approach notably enhances the robustness, flexibility, and scalability of RLVR, representing a substantial step towards practical reinforcement learning applications in complex, noisy-label scenarios.
Dancing with Critiques: Enhancing LLM Reasoning with Stepwise Natural Language Self-Critique
Mar 21, 2025



Enhancing the reasoning capabilities of large language models (LLMs), particularly for complex tasks requiring multi-step logical deductions, remains a significant challenge. Traditional inference time scaling methods utilize scalar reward signals from process reward models to evaluate candidate reasoning steps, but these scalar rewards lack the nuanced qualitative information essential for understanding and justifying each step. In this paper, we propose a novel inference-time scaling approach -- stepwise natural language self-critique (PANEL), which employs self-generated natural language critiques as feedback to guide the step-level search process. By generating rich, human-readable critiques for each candidate reasoning step, PANEL retains essential qualitative information, facilitating better-informed decision-making during inference. This approach bypasses the need for task-specific verifiers and the associated training overhead, making it broadly applicable across diverse tasks. Experimental results on challenging reasoning benchmarks, including AIME and GPQA, demonstrate that PANEL significantly enhances reasoning performance, outperforming traditional scalar reward-based methods. Our code is available at https://github.com/puddingyeah/PANEL to support and encourage future research in this promising field.
The Lighthouse of Language: Enhancing LLM Agents via Critique-Guided Improvement
Mar 20, 2025Large language models (LLMs) have recently transformed from text-based assistants to autonomous agents capable of planning, reasoning, and iteratively improving their actions. While numerical reward signals and verifiers can effectively rank candidate actions, they often provide limited contextual guidance. In contrast, natural language feedback better aligns with the generative capabilities of LLMs, providing richer and more actionable suggestions. However, parsing and implementing this feedback effectively can be challenging for LLM-based agents. In this work, we introduce Critique-Guided Improvement (CGI), a novel two-player framework, comprising an actor model that explores an environment and a critic model that generates detailed nature language feedback. By training the critic to produce fine-grained assessments and actionable revisions, and the actor to utilize these critiques, our approach promotes more robust exploration of alternative strategies while avoiding local optima. Experiments in three interactive environments show that CGI outperforms existing baselines by a substantial margin. Notably, even a small critic model surpasses GPT-4 in feedback quality. The resulting actor achieves state-of-the-art performance, demonstrating the power of explicit iterative guidance to enhance decision-making in LLM-based agents.
RaSA: Rank-Sharing Low-Rank Adaptation
Mar 16, 2025Low-rank adaptation (LoRA) has been prominently employed for parameter-efficient fine-tuning of large language models (LLMs). However, the limited expressive capacity of LoRA, stemming from the low-rank constraint, has been recognized as a bottleneck, particularly in rigorous tasks like code generation and mathematical reasoning. To address this limitation, we introduce Rank-Sharing Low-Rank Adaptation (RaSA), an innovative extension that enhances the expressive capacity of LoRA by leveraging partial rank sharing across layers. By forming a shared rank pool and applying layer-specific weighting, RaSA effectively increases the number of ranks without augmenting parameter overhead. Our theoretically grounded and empirically validated approach demonstrates that RaSA not only maintains the core advantages of LoRA but also significantly boosts performance in challenging code and math tasks. Code, data and scripts are available at: https://github.com/zwhe99/RaSA.
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
Mar 04, 2025



Improving the reasoning capabilities of large language models (LLMs) typically requires supervised fine-tuning with labeled data or computationally expensive sampling. We introduce Unsupervised Prefix Fine-Tuning (UPFT), which leverages the observation of Prefix Self-Consistency -- the shared initial reasoning steps across diverse solution trajectories -- to enhance LLM reasoning efficiency. By training exclusively on the initial prefix substrings (as few as 8 tokens), UPFT removes the need for labeled data or exhaustive sampling. Experiments on reasoning benchmarks show that UPFT matches the performance of supervised methods such as Rejection Sampling Fine-Tuning, while reducing training time by 75% and sampling cost by 99%. Further analysis reveals that errors tend to appear in later stages of the reasoning process and that prefix-based training preserves the model's structural knowledge. This work demonstrates how minimal unsupervised fine-tuning can unlock substantial reasoning gains in LLMs, offering a scalable and resource-efficient alternative to conventional approaches.
VisFactor: Benchmarking Fundamental Visual Cognition in Multimodal Large Language Models
Feb 23, 2025



Multimodal Large Language Models (MLLMs) have demonstrated remarkable advancements in multimodal understanding; however, their fundamental visual cognitive abilities remain largely underexplored. To bridge this gap, we introduce VisFactor, a novel benchmark derived from the Factor-Referenced Cognitive Test (FRCT), a well-established psychometric assessment of human cognition. VisFactor digitalizes vision-related FRCT subtests to systematically evaluate MLLMs across essential visual cognitive tasks including spatial reasoning, perceptual speed, and pattern recognition. We present a comprehensive evaluation of state-of-the-art MLLMs, such as GPT-4o, Gemini-Pro, and Qwen-VL, using VisFactor under diverse prompting strategies like Chain-of-Thought and Multi-Agent Debate. Our findings reveal a concerning deficiency in current MLLMs' fundamental visual cognition, with performance frequently approaching random guessing and showing only marginal improvements even with advanced prompting techniques. These results underscore the critical need for focused research to enhance the core visual reasoning capabilities of MLLMs. To foster further investigation in this area, we release our VisFactor benchmark at https://github.com/CUHK-ARISE/VisFactor.