 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the power of longitudinal medical imaging for eye disease prognosis using Transformer-based sequence modeling
May 14, 2024



Deep learning has enabled breakthroughs in automated diagnosis from medical imaging, with many successful applications in ophthalmology. However, standard medical image classification approaches only assess disease presence at the time of acquisition, neglecting the common clinical setting of longitudinal imaging. For slow, progressive eye diseases like age-related macular degeneration (AMD) and primary open-angle glaucoma (POAG), patients undergo repeated imaging over time to track disease progression and forecasting the future risk of developing disease is critical to properly plan treatment. Our proposed Longitudinal Transformer for Survival Analysis (LTSA) enables dynamic disease prognosis from longitudinal medical imaging, modeling the time to disease from sequences of fundus photography images captured over long, irregular time periods. Using longitudinal imaging data from the Age-Related Eye Disease Study (AREDS) and Ocular Hypertension Treatment Study (OHTS), LTSA significantly outperformed a single-image baseline in 19/20 head-to-head comparisons on late AMD prognosis and 18/20 comparisons on POAG prognosis. A temporal attention analysis also suggested that, while the most recent image is typically the most influential, prior imaging still provides additional prognostic value.
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024



Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Apr 10, 2024

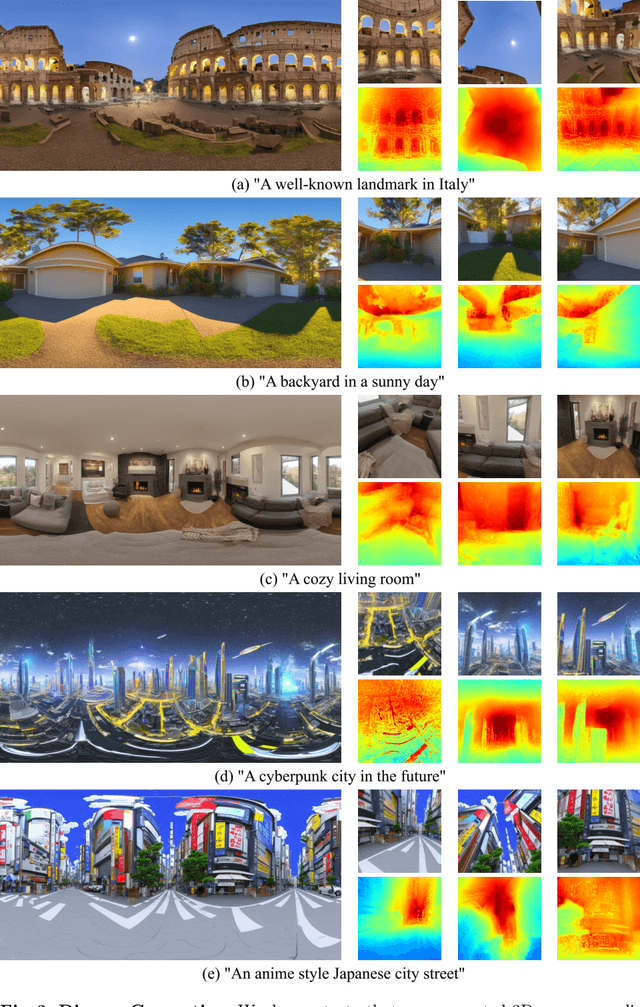

The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
MM3DGS SLAM: Multi-modal 3D Gaussian Splatting for SLAM Using Vision, Depth, and Inertial Measurements
Apr 01, 2024



Simultaneous localization and mapping is essential for position tracking and scene understanding. 3D Gaussian-based map representations enable photorealistic reconstruction and real-time rendering of scenes using multiple posed cameras. We show for the first time that using 3D Gaussians for map representation with unposed camera images and inertial measurements can enable accurate SLAM. Our method, MM3DGS, addresses the limitations of prior neural radiance field-based representations by enabling faster rendering, scale awareness, and improved trajectory tracking. Our framework enables keyframe-based mapping and tracking utilizing loss functions that incorporate relative pose transformations from pre-integrated inertial measurements, depth estimates, and measures of photometric rendering quality. We also release a multi-modal dataset, UT-MM, collected from a mobile robot equipped with a camera and an inertial measurement unit. Experimental evaluation on several scenes from the dataset shows that MM3DGS achieves 3x improvement in tracking and 5% improvement in photometric rendering quality compared to the current 3DGS SLAM state-of-the-art, while allowing real-time rendering of a high-resolution dense 3D map. Project Webpage: https://vita-group.github.io/MM3DGS-SLAM
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Mar 29, 2024While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
Mar 27, 2024In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP), but then generalizes to novel vision operators and tasks, such as style transfer, super-resolution, open vocabulary segmentation and image colorization; for some of these tasks, there is no comparable previous 3D method. In many cases, we even outperform state-of-the-art methods specialized for the task in question. Moreover, Lift3D is a zero-shot method, in the sense that it requires no task-specific training, nor scene-specific optimization.
Generalization Error Analysis for Sparse Mixture-of-Experts: A Preliminary Study
Mar 26, 2024Mixture-of-Experts (MoE) represents an ensemble methodology that amalgamates predictions from several specialized sub-models (referred to as experts). This fusion is accomplished through a router mechanism, dynamically assigning weights to each expert's contribution based on the input data. Conventional MoE mechanisms select all available experts, incurring substantial computational costs. In contrast, Sparse Mixture-of-Experts (Sparse MoE) selectively engages only a limited number, or even just one expert, significantly reducing computation overhead while empirically preserving, and sometimes even enhancing, performance. Despite its wide-ranging applications and these advantageous characteristics, MoE's theoretical underpinnings have remained elusive. In this paper, we embark on an exploration of Sparse MoE's generalization error concerning various critical factors. Specifically, we investigate the impact of the number of data samples, the total number of experts, the sparsity in expert selection, the complexity of the routing mechanism, and the complexity of individual experts. Our analysis sheds light on \textit{how \textbf{sparsity} contributes to the MoE's generalization}, offering insights from the perspective of classical learning theory.
Comp4D: LLM-Guided Compositional 4D Scene Generation
Mar 25, 2024



Recent advancements in diffusion models for 2D and 3D content creation have sparked a surge of interest in generating 4D content. However, the scarcity of 3D scene datasets constrains current methodologies to primarily object-centric generation. To overcome this limitation, we present Comp4D, a novel framework for Compositional 4D Generation. Unlike conventional methods that generate a singular 4D representation of the entire scene, Comp4D innovatively constructs each 4D object within the scene separately. Utilizing Large Language Models (LLMs), the framework begins by decomposing an input text prompt into distinct entities and maps out their trajectories. It then constructs the compositional 4D scene by accurately positioning these objects along their designated paths. To refine the scene, our method employs a compositional score distillation technique guided by the pre-defined trajectories, utilizing pre-trained diffusion models across text-to-image, text-to-video, and text-to-3D domains. Extensive experiments demonstrate our outstanding 4D content creation capability compared to prior arts, showcasing superior visual quality, motion fidelity, and enhanced object interactions.
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
Mar 21, 2024



Text-to-video diffusion models enable the generation of high-quality videos that follow text instructions, making it easy to create diverse and individual content. However, existing approaches mostly focus on high-quality short video generation (typically 16 or 24 frames), ending up with hard-cuts when naively extended to the case of long video synthesis. To overcome these limitations, we introduce StreamingT2V, an autoregressive approach for long video generation of 80, 240, 600, 1200 or more frames with smooth transitions. The key components are:(i) a short-term memory block called conditional attention module (CAM), which conditions the current generation on the features extracted from the previous chunk via an attentional mechanism, leading to consistent chunk transitions, (ii) a long-term memory block called appearance preservation module, which extracts high-level scene and object features from the first video chunk to prevent the model from forgetting the initial scene, and (iii) a randomized blending approach that enables to apply a video enhancer autoregressively for infinitely long videos without inconsistencies between chunks. Experiments show that StreamingT2V generates high motion amount. In contrast, all competing image-to-video methods are prone to video stagnation when applied naively in an autoregressive manner. Thus, we propose with StreamingT2V a high-quality seamless text-to-long video generator that outperforms competitors with consistency and motion. Our code will be available at: https://github.com/Picsart-AI-Research/StreamingT2V
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024



Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.