 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on AI-Generated Media Detection: From Non-MLLM to MLLM
Feb 07, 2025The proliferation of AI-generated media poses significant challenges to information authenticity and social trust, making reliable detection methods highly demanded. Methods for detecting AI-generated media have evolved rapidly, paralleling the advancement of Multimodal Large Language Models (MLLMs). Current detection approaches can be categorized into two main groups: Non-MLLM-based and MLLM-based methods. The former employs high-precision, domain-specific detectors powered by deep learning techniques, while the latter utilizes general-purpose detectors based on MLLMs that integrate authenticity verification, explainability, and localization capabilities. Despite significant progress in this field, there remains a gap in literature regarding a comprehensive survey that examines the transition from domain-specific to general-purpose detection methods. This paper addresses this gap by providing a systematic review of both approaches, analyzing them from single-modal and multi-modal perspectives. We present a detailed comparative analysis of these categories, examining their methodological similarities and differences. Through this analysis, we explore potential hybrid approaches and identify key challenges in forgery detection, providing direction for future research. Additionally, as MLLMs become increasingly prevalent in detection tasks, ethical and security considerations have emerged as critical global concerns. We examine the regulatory landscape surrounding Generative AI (GenAI) across various jurisdictions, offering valuable insights for researchers and practitioners in this field.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024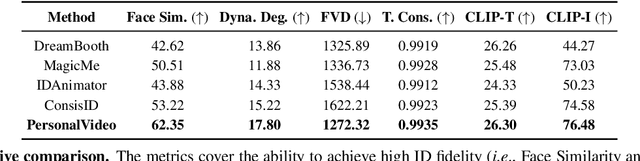
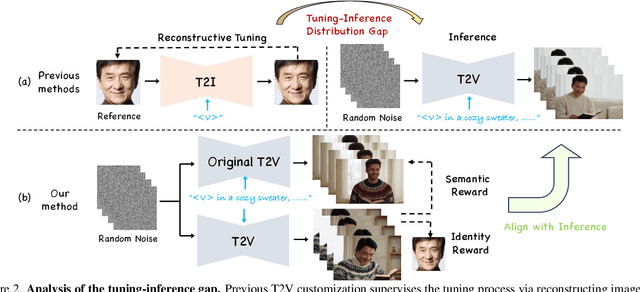
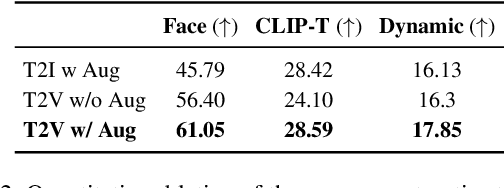
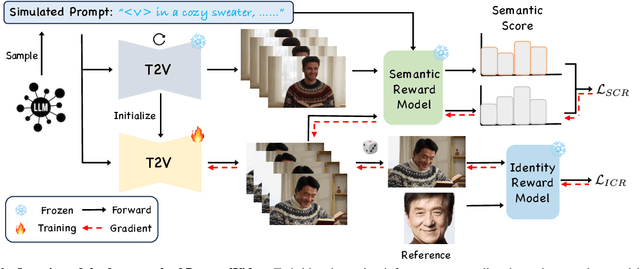
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.
Jailbreak Attacks and Defenses against Multimodal Generative Models: A Survey
Nov 14, 2024



The rapid evolution of multimodal foundation models has led to significant advancements in cross-modal understanding and generation across diverse modalities, including text, images, audio, and video. However, these models remain susceptible to jailbreak attacks, which can bypass built-in safety mechanisms and induce the production of potentially harmful content. Consequently, understanding the methods of jailbreak attacks and existing defense mechanisms is essential to ensure the safe deployment of multimodal generative models in real-world scenarios, particularly in security-sensitive applications. To provide comprehensive insight into this topic, this survey reviews jailbreak and defense in multimodal generative models. First, given the generalized lifecycle of multimodal jailbreak, we systematically explore attacks and corresponding defense strategies across four levels: input, encoder, generator, and output. Based on this analysis, we present a detailed taxonomy of attack methods, defense mechanisms, and evaluation frameworks specific to multimodal generative models. Additionally, we cover a wide range of input-output configurations, including modalities such as Any-to-Text, Any-to-Vision, and Any-to-Any within generative systems. Finally, we highlight current research challenges and propose potential directions for future research.The open-source repository corresponding to this work can be found at https://github.com/liuxuannan/Awesome-Multimodal-Jailbreak.
Correlation-Aware Select and Merge Attention for Efficient Fine-Tuning and Context Length Extension
Oct 05, 2024



Modeling long sequences is crucial for various large-scale models; however, extending existing architectures to handle longer sequences presents significant technical and resource challenges. In this paper, we propose an efficient and flexible attention architecture that enables the extension of context lengths in large language models with reduced computational resources and fine-tuning time compared to other excellent methods. Specifically, we introduce correlation-aware selection and merging mechanisms to facilitate efficient sparse attention. In addition, we also propose a novel data augmentation technique involving positional encodings to enhance generalization to unseen positions. The results are as follows: First, using a single A100, we achieve fine-tuning on Llama2-7B with a sequence length of 32K, which is more efficient than other methods that rely on subsets for regression. Second, we present a comprehensive method for extending context lengths across the pre-training, fine-tuning, and inference phases. During pre-training, our attention mechanism partially breaks translation invariance during token selection, so we apply positional encodings only to the selected tokens. This approach achieves relatively high performance and significant extrapolation capabilities. For fine-tuning, we introduce Cyclic, Randomly Truncated, and Dynamically Growing NTK Positional Embedding (CRD NTK). This design allows fine-tuning with a sequence length of only 16K, enabling models such as Llama2-7B and Mistral-7B to perform inference with context lengths of up to 1M or even arbitrary lengths. Our method achieves 100\% accuracy on the passkey task with a context length of 4M and maintains stable perplexity at a 1M context length. This represents at least a 64-fold reduction in resource requirements compared to traditional full-attention mechanisms, while still achieving competitive performance.
Can Editing LLMs Inject Harm?
Jul 29, 2024



Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
Jun 13, 2024



We introduce MuirBench, a comprehensive benchmark that focuses on robust multi-image understanding capabilities of multimodal LLMs. MuirBench consists of 12 diverse multi-image tasks (e.g., scene understanding, ordering) that involve 10 categories of multi-image relations (e.g., multiview, temporal relations). Comprising 11,264 images and 2,600 multiple-choice questions, MuirBench is created in a pairwise manner, where each standard instance is paired with an unanswerable variant that has minimal semantic differences, in order for a reliable assessment. Evaluated upon 20 recent multi-modal LLMs, our results reveal that even the best-performing models like GPT-4o and Gemini Pro find it challenging to solve MuirBench, achieving 68.0% and 49.3% in accuracy. Open-source multimodal LLMs trained on single images can hardly generalize to multi-image questions, hovering below 33.3% in accuracy. These results highlight the importance of MuirBench in encouraging the community to develop multimodal LLMs that can look beyond a single image, suggesting potential pathways for future improvements.
MMFakeBench: A Mixed-Source Multimodal Misinformation Detection Benchmark for LVLMs
Jun 13, 2024



Current multimodal misinformation detection (MMD) methods often assume a single source and type of forgery for each sample, which is insufficient for real-world scenarios where multiple forgery sources coexist. The lack of a benchmark for mixed-source misinformation has hindered progress in this field. To address this, we introduce MMFakeBench, the first comprehensive benchmark for mixed-source MMD. MMFakeBench includes 3 critical sources: textual veracity distortion, visual veracity distortion, and cross-modal consistency distortion, along with 12 sub-categories of misinformation forgery types. We further conduct an extensive evaluation of 6 prevalent detection methods and 15 large vision-language models (LVLMs) on MMFakeBench under a zero-shot setting. The results indicate that current methods struggle under this challenging and realistic mixed-source MMD setting. Additionally, we propose an innovative unified framework, which integrates rationales, actions, and tool-use capabilities of LVLM agents, significantly enhancing accuracy and generalization. We believe this study will catalyze future research into more realistic mixed-source multimodal misinformation and provide a fair evaluation of misinformation detection methods.
Localize, Understand, Collaborate: Semantic-Aware Dragging via Intention Reasoner
Jun 01, 2024Flexible and accurate drag-based editing is a challenging task that has recently garnered significant attention. Current methods typically model this problem as automatically learning ``how to drag'' through point dragging and often produce one deterministic estimation, which presents two key limitations: 1) Overlooking the inherently ill-posed nature of drag-based editing, where multiple results may correspond to a given input, as illustrated in Fig.1; 2) Ignoring the constraint of image quality, which may lead to unexpected distortion. To alleviate this, we propose LucidDrag, which shifts the focus from ``how to drag'' to a paradigm of ``what-then-how''. LucidDrag comprises an intention reasoner and a collaborative guidance sampling mechanism. The former infers several optimal editing strategies, identifying what content and what semantic direction to be edited. Based on the former, the latter addresses "how to drag" by collaboratively integrating existing editing guidance with the newly proposed semantic guidance and quality guidance. Specifically, semantic guidance is derived by establishing a semantic editing direction based on reasoned intentions, while quality guidance is achieved through classifier guidance using an image fidelity discriminator. Both qualitative and quantitative comparisons demonstrate the superiority of LucidDrag over previous methods. The code will be released.
FakeNewsGPT4: Advancing Multimodal Fake News Detection through Knowledge-Augmented LVLMs
Mar 04, 2024



The massive generation of multimodal fake news exhibits substantial distribution discrepancies, prompting the need for generalized detectors. However, the insulated nature of training within specific domains restricts the capability of classical detectors to obtain open-world facts. In this paper, we propose FakeNewsGPT4, a novel framework that augments Large Vision-Language Models (LVLMs) with forgery-specific knowledge for manipulation reasoning while inheriting extensive world knowledge as complementary. Knowledge augmentation in FakeNewsGPT4 involves acquiring two types of forgery-specific knowledge, i.e., semantic correlation and artifact trace, and merging them into LVLMs. Specifically, we design a multi-level cross-modal reasoning module that establishes interactions across modalities for extracting semantic correlations. Concurrently, a dual-branch fine-grained verification module is presented to comprehend localized details to encode artifact traces. The generated knowledge is translated into refined embeddings compatible with LVLMs. We also incorporate candidate answer heuristics and soft prompts to enhance input informativeness. Extensive experiments on the public benchmark demonstrate that FakeNewsGPT4 achieves superior cross-domain performance compared to previous methods. Code will be available.