 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
AlignSurvey: A Comprehensive Benchmark for Human Preferences Alignment in Social Surveys
Nov 13, 2025Understanding human attitudes, preferences, and behaviors through social surveys is essential for academic research and policymaking. Yet traditional surveys face persistent challenges, including fixed-question formats, high costs, limited adaptability, and difficulties ensuring cross-cultural equivalence. While recent studies explore large language models (LLMs) to simulate survey responses, most are limited to structured questions, overlook the entire survey process, and risks under-representing marginalized groups due to training data biases. We introduce AlignSurvey, the first benchmark that systematically replicates and evaluates the full social survey pipeline using LLMs. It defines four tasks aligned with key survey stages: social role modeling, semi-structured interview modeling, attitude stance modeling and survey response modeling. It also provides task-specific evaluation metrics to assess alignment fidelity, consistency, and fairness at both individual and group levels, with a focus on demographic diversity. To support AlignSurvey, we construct a multi-tiered dataset architecture: (i) the Social Foundation Corpus, a cross-national resource with 44K+ interview dialogues and 400K+ structured survey records; and (ii) a suite of Entire-Pipeline Survey Datasets, including the expert-annotated AlignSurvey-Expert (ASE) and two nationally representative surveys for cross-cultural evaluation. We release the SurveyLM family, obtained through two-stage fine-tuning of open-source LLMs, and offer reference models for evaluating domain-specific alignment. All datasets, models, and tools are available at github and huggingface to support transparent and socially responsible research.
RCMNet: A deep learning model assists CAR-T therapy for leukemia
May 06, 2022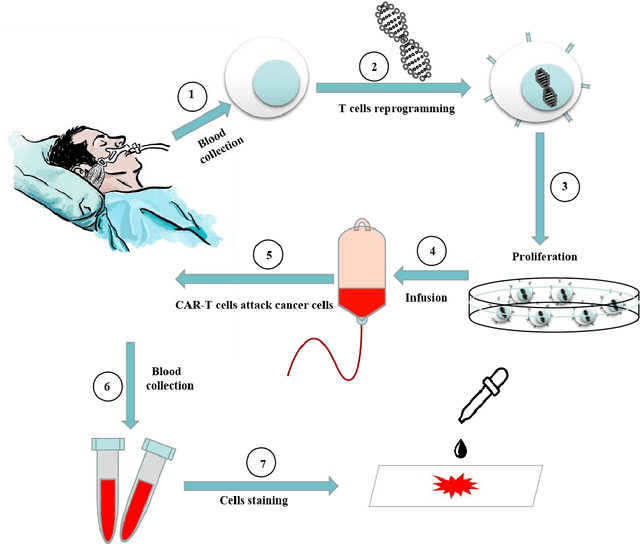
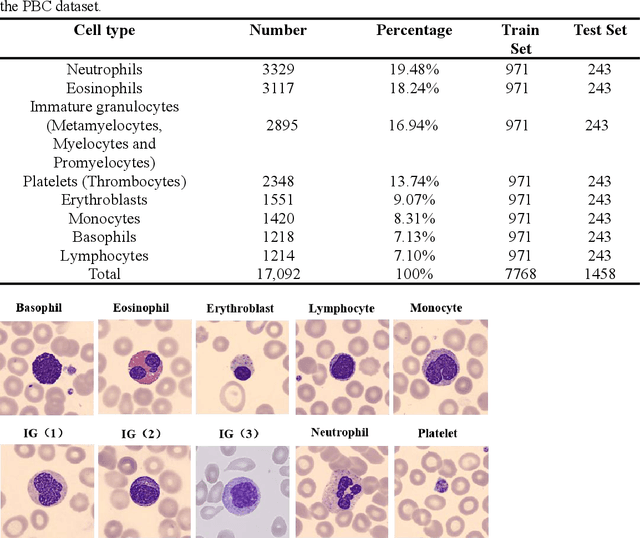
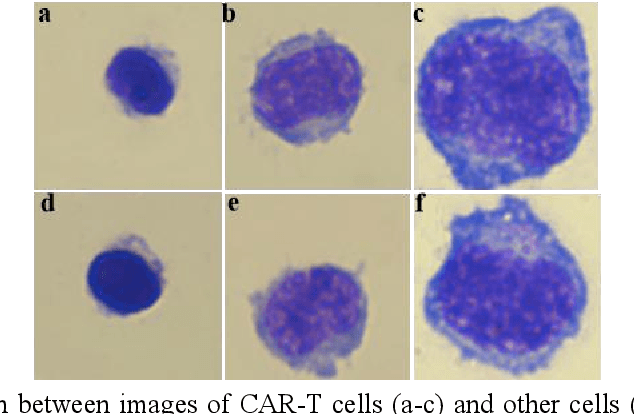

Acute leukemia is a type of blood cancer with a high mortality rate. Current therapeutic methods include bone marrow transplantation, supportive therapy, and chemotherapy. Although a satisfactory remission of the disease can be achieved, the risk of recurrence is still high. Therefore, novel treatments are demanding. Chimeric antigen receptor-T (CAR-T) therapy has emerged as a promising approach to treat and cure acute leukemia. To harness the therapeutic potential of CAR-T cell therapy for blood diseases, reliable cell morphological identification is crucial. Nevertheless, the identification of CAR-T cells is a big challenge posed by their phenotypic similarity with other blood cells. To address this substantial clinical challenge, herein we first construct a CAR-T dataset with 500 original microscopy images after staining. Following that, we create a novel integrated model called RCMNet (ResNet18 with CBAM and MHSA) that combines the convolutional neural network (CNN) and Transformer. The model shows 99.63% top-1 accuracy on the public dataset. Compared with previous reports, our model obtains satisfactory results for image classification. Although testing on the CAR-T cells dataset, a decent performance is observed, which is attributed to the limited size of the dataset. Transfer learning is adapted for RCMNet and a maximum of 83.36% accuracy has been achieved, which is higher than other SOTA models. The study evaluates the effectiveness of RCMNet on a big public dataset and translates it to a clinical dataset for diagnostic applications.