 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACER: Training-Free Closed-Loop Structured Inference for Traffic Accident Reconstruction
Jun 23, 2026Traffic accident reconstruction is a forensic inverse problem that requires recovering physically consistent motion from sparse and heterogeneous evidence. Existing learning-based approaches predominantly optimize for semantic plausibility or visual realism, rather than quantitative agreement with measurable geometry and dynamics. Here, we present TRACER, a training-free framework that formulates reconstruction as a closed-loop structured inference process. Instead of directly generating dense trajectories, our framework constructs and iteratively refines event-anchored motion hypotheses under geometric, kinematic, and interaction constraints, guided by structured case memory and consistency-driven diagnosis. This design enables incremental, interpretable corrections when evidence is insufficient, making the accident reconstruction process more aligned with the workflow of human experts. Experiments on real-world accident data show that TRACER achieves improved geometric fidelity, velocity consistency, and collision accuracy over both data-driven and physics-based baselines.
ScenePilot: Controllable Boundary-Driven Critical Scenario Generation for Autonomous Driving
May 20, 2026Safety-critical scenarios are central to evaluating autonomous driving systems, yet their rarity in naturalistic logs makes simulation-based stress testing indispensable. Most scenario generation methods treat surrounding agents as adversaries, but they either (i) induce failures without explicitly modeling vehicle-road physical limits, yielding visually extreme yet physically unsolvable crashes, or (ii) enforce physical feasibility or policy feasibility in isolation, which can over-focus on aggressive maneuvers or remain tied to a controller-dependent capability boundary. We propose ScenePilot, a feasibility-guided, boundary-driven framework that targets the boundary band: scenarios that are physically solvable in principle yet still cause the deployed autonomy stack to fail. We formulate generation as constrained multi-objective reinforcement learning, combining an RSS-derived physical-feasibility score $σ$ with an online-learned AV-risk predictor $Φ$, and introduce step-level feasibility-aware shielding to keep exploration near the feasibility boundary while avoiding infeasible artifacts. Experiments on SafeBench with multiple planners show that ScenePilot yields substantially higher collision rates (+6.2 percentage points) while preserving physical validity, and that adversarial fine-tuning on these boundary-band scenarios consistently reduces downstream crash rates. The code is available at https://github.com/QiyuRuan/ScenePilot.
C$^2$T: Captioning-Structure and LLM-Aligned Common-Sense Reward Learning for Traffic--Vehicle Coordination
Apr 10, 2026State-of-the-art (SOTA) urban traffic control increasingly employs Multi-Agent Reinforcement Learning (MARL) to coordinate Traffic Light Controllers (TLCs) and Connected Autonomous Vehicles (CAVs). However, the performance of these systems is fundamentally capped by their hand-crafted, myopic rewards (e.g., intersection pressure), which fail to capture high-level, human-centric goals like safety, flow stability, and comfort. To overcome this limitation, we introduce C2T, a novel framework that learns a common-sense coordination model from traffic-vehicle dynamics. C2T distills "common-sense" knowledge from a Large Language Model (LLM) into a learned intrinsic reward function. This new reward is then used to guide the coordination policy of a cooperative multi-intersection TLC MARL system on CityFlow-based multi-intersection benchmarks. Our framework significantly outperforms strong MARL baselines in traffic efficiency, safety, and an energy-related proxy. We further highlight C2T's flexibility in principle, allowing distinct "efficiency-focused" versus "safety-focused" policies by modifying the LLM prompt.
SAIL: Scene-aware Adaptive Iterative Learning for Long-Tail Trajectory Prediction in Autonomous Vehicles
Apr 06, 2026Autonomous vehicles (AVs) rely on accurate trajectory prediction for safe navigation in diverse traffic environments, yet existing models struggle with long-tail scenarios-rare but safety-critical events characterized by abrupt maneuvers, high collision risks, and complex interactions. These challenges stem from data imbalance, inadequate definitions of long-tail trajectories, and suboptimal learning strategies that prioritize common behaviors over infrequent ones. To address this, we propose SAIL, a novel framework that systematically tackles the long-tail problem by first defining and modeling trajectories across three key attribute dimensions: prediction error, collision risk, and state complexity. Our approach then synergizes an attribute-guided augmentation and feature extraction process with a highly adaptive contrastive learning strategy. This strategy employs a continuous cosine momentum schedule, similarity-weighted hard-negative mining, and a dynamic pseudo-labeling mechanism based on evolving feature clustering. Furthermore, it incorporates a focusing mechanism to intensify learning on hard-positive samples within each identified class. This comprehensive design enables SAIL to excel at identifying and forecasting diverse and challenging long-tail events. Extensive evaluations on the nuScenes and ETH/UCY datasets demonstrate SAIL's superior performance, achieving up to 28.8% reduction in prediction error on the hardest 1% of long-tail samples compared to state-of-the-art baselines, while maintaining competitive accuracy across all scenarios. This framework advances reliable AV trajectory prediction in real-world, mixed-autonomy settings.
Coordinated Pandemic Control with Large Language Model Agents as Policymaking Assistants
Jan 14, 2026Effective pandemic control requires timely and coordinated policymaking across administrative regions that are intrinsically interdependent. However, human-driven responses are often fragmented and reactive, with policies formulated in isolation and adjusted only after outbreaks escalate, undermining proactive intervention and global pandemic mitigation. To address this challenge, here we propose a large language model (LLM) multi-agent policymaking framework that supports coordinated and proactive pandemic control across regions. Within our framework, each administrative region is assigned an LLM agent as an AI policymaking assistant. The agent reasons over region-specific epidemiological dynamics while communicating with other agents to account for cross-regional interdependencies. By integrating real-world data, a pandemic evolution simulator, and structured inter-agent communication, our framework enables agents to jointly explore counterfactual intervention scenarios and synthesize coordinated policy decisions through a closed-loop simulation process. We validate the proposed framework using state-level COVID-19 data from the United States between April and December 2020, together with real-world mobility records and observed policy interventions. Compared with real-world pandemic outcomes, our approach reduces cumulative infections and deaths by up to 63.7% and 40.1%, respectively, at the individual state level, and by 39.0% and 27.0%, respectively, when aggregated across states. These results demonstrate that LLM multi-agent systems can enable more effective pandemic control with coordinated policymaking...
Predict and Resist: Long-Term Accident Anticipation under Sensor Noise
Nov 10, 2025Accident anticipation is essential for proactive and safe autonomous driving, where even a brief advance warning can enable critical evasive actions. However, two key challenges hinder real-world deployment: (1) noisy or degraded sensory inputs from weather, motion blur, or hardware limitations, and (2) the need to issue timely yet reliable predictions that balance early alerts with false-alarm suppression. We propose a unified framework that integrates diffusion-based denoising with a time-aware actor-critic model to address these challenges. The diffusion module reconstructs noise-resilient image and object features through iterative refinement, preserving critical motion and interaction cues under sensor degradation. In parallel, the actor-critic architecture leverages long-horizon temporal reasoning and time-weighted rewards to determine the optimal moment to raise an alert, aligning early detection with reliability. Experiments on three benchmark datasets (DAD, CCD, A3D) demonstrate state-of-the-art accuracy and significant gains in mean time-to-accident, while maintaining robust performance under Gaussian and impulse noise. Qualitative analyses further show that our model produces earlier, more stable, and human-aligned predictions in both routine and highly complex traffic scenarios, highlighting its potential for real-world, safety-critical deployment.
ROAR: Robust Accident Recognition and Anticipation for Autonomous Driving
Nov 09, 2025
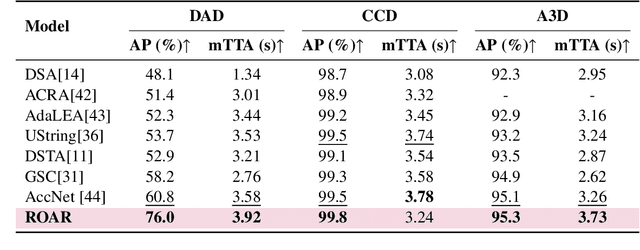
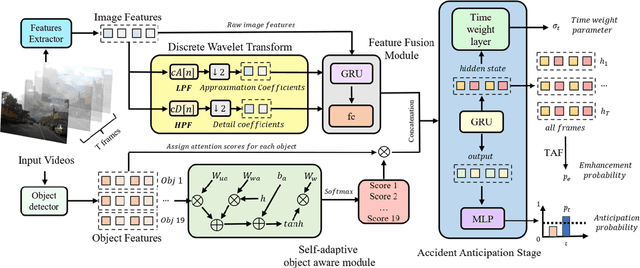
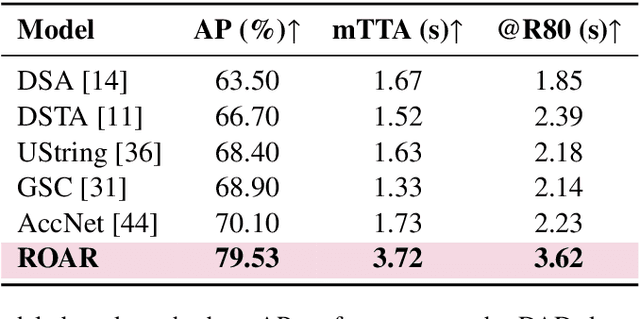
Accurate accident anticipation is essential for enhancing the safety of autonomous vehicles (AVs). However, existing methods often assume ideal conditions, overlooking challenges such as sensor failures, environmental disturbances, and data imperfections, which can significantly degrade prediction accuracy. Additionally, previous models have not adequately addressed the considerable variability in driver behavior and accident rates across different vehicle types. To overcome these limitations, this study introduces ROAR, a novel approach for accident detection and prediction. ROAR combines Discrete Wavelet Transform (DWT), a self adaptive object aware module, and dynamic focal loss to tackle these challenges. The DWT effectively extracts features from noisy and incomplete data, while the object aware module improves accident prediction by focusing on high-risk vehicles and modeling the spatial temporal relationships among traffic agents. Moreover, dynamic focal loss mitigates the impact of class imbalance between positive and negative samples. Evaluated on three widely used datasets, Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), our model consistently outperforms existing baselines in key metrics such as Average Precision (AP) and mean Time to Accident (mTTA). These results demonstrate the model's robustness in real-world conditions, particularly in handling sensor degradation, environmental noise, and imbalanced data distributions. This work offers a promising solution for reliable and accurate accident anticipation in complex traffic environments.
AMD: Adaptive Momentum and Decoupled Contrastive Learning Framework for Robust Long-Tail Trajectory Prediction
Jul 02, 2025Accurately predicting the future trajectories of traffic agents is essential in autonomous driving. However, due to the inherent imbalance in trajectory distributions, tail data in natural datasets often represents more complex and hazardous scenarios. Existing studies typically rely solely on a base model's prediction error, without considering the diversity and uncertainty of long-tail trajectory patterns. We propose an adaptive momentum and decoupled contrastive learning framework (AMD), which integrates unsupervised and supervised contrastive learning strategies. By leveraging an improved momentum contrast learning (MoCo-DT) and decoupled contrastive learning (DCL) module, our framework enhances the model's ability to recognize rare and complex trajectories. Additionally, we design four types of trajectory random augmentation methods and introduce an online iterative clustering strategy, allowing the model to dynamically update pseudo-labels and better adapt to the distributional shifts in long-tail data. We propose three different criteria to define long-tail trajectories and conduct extensive comparative experiments on the nuScenes and ETH$/$UCY datasets. The results show that AMD not only achieves optimal performance in long-tail trajectory prediction but also demonstrates outstanding overall prediction accuracy.
SAH-Drive: A Scenario-Aware Hybrid Planner for Closed-Loop Vehicle Trajectory Generation
May 30, 2025Reliable planning is crucial for achieving autonomous driving. Rule-based planners are efficient but lack generalization, while learning-based planners excel in generalization yet have limitations in real-time performance and interpretability. In long-tail scenarios, these challenges make planning particularly difficult. To leverage the strengths of both rule-based and learning-based planners, we proposed the Scenario-Aware Hybrid Planner (SAH-Drive) for closed-loop vehicle trajectory planning. Inspired by human driving behavior, SAH-Drive combines a lightweight rule-based planner and a comprehensive learning-based planner, utilizing a dual-timescale decision neuron to determine the final trajectory. To enhance the computational efficiency and robustness of the hybrid planner, we also employed a diffusion proposal number regulator and a trajectory fusion module. The experimental results show that the proposed method significantly improves the generalization capability of the planning system, achieving state-of-the-art performance in interPlan, while maintaining computational efficiency without incurring substantial additional runtime.
Towards Human-Like Trajectory Prediction for Autonomous Driving: A Behavior-Centric Approach
May 27, 2025



Predicting the trajectories of vehicles is crucial for the development of autonomous driving (AD) systems, particularly in complex and dynamic traffic environments. In this study, we introduce HiT (Human-like Trajectory Prediction), a novel model designed to enhance trajectory prediction by incorporating behavior-aware modules and dynamic centrality measures. Unlike traditional methods that primarily rely on static graph structures, HiT leverages a dynamic framework that accounts for both direct and indirect interactions among traffic participants. This allows the model to capture the subtle yet significant influences of surrounding vehicles, enabling more accurate and human-like predictions. To evaluate HiT's performance, we conducted extensive experiments using diverse and challenging real-world datasets, including NGSIM, HighD, RounD, ApolloScape, and MoCAD++. The results demonstrate that HiT consistently outperforms other top models across multiple metrics, particularly excelling in scenarios involving aggressive driving behaviors. This research presents a significant step forward in trajectory prediction, offering a more reliable and interpretable approach for enhancing the safety and efficiency of fully autonomous driving systems.