 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Delta: Unifying Remote Sensing Change Detection and Understanding with Multimodal Large Language Models
Apr 15, 2026While Multimodal Large Language Models (MLLMs) excel in general vision-language tasks, their application to remote sensing change understanding is hindered by a fundamental "temporal blindness". Existing architectures lack intrinsic mechanisms for multi-temporal contrastive reasoning and struggle with precise spatial grounding. To address this, we first introduce Delta-QA, a comprehensive benchmark comprising 180k visual question-answering samples. Delta-QA unifies pixel-level segmentation and visual question answering across bi- and tri-temporal scenarios, structuring change interpretation into four progressive cognitive dimensions. Methodologically, we propose Delta-LLaVA, a novel MLLM framework explicitly tailored for multi-temporal remote sensing interpretation. It overcomes the limitations of naive feature concatenation through three core innovations: a Change-Enhanced Attention module that systematically isolates and amplifies visual differences, a Change-SEG module utilizing Change Prior Embedding to extract differentiable difference features as input for the LLM, and Local Causal Attention to prevent cross-temporal contextual leakage. Extensive experiments demonstrate that Delta-LLaVA decisively outperforms leading generalist MLLMs and specialized segmentation models in complex change deduction and high-precision boundary localization, establishing a unified framework for earth observation intelligence.
Multi-step Temporal Modeling for UAV Tracking
Mar 07, 2024In the realm of unmanned aerial vehicle (UAV) tracking, Siamese-based approaches have gained traction due to their optimal balance between efficiency and precision. However, UAV scenarios often present challenges such as insufficient sampling resolution, fast motion and small objects with limited feature information. As a result, temporal context in UAV tracking tasks plays a pivotal role in target location, overshadowing the target's precise features. In this paper, we introduce MT-Track, a streamlined and efficient multi-step temporal modeling framework designed to harness the temporal context from historical frames for enhanced UAV tracking. This temporal integration occurs in two steps: correlation map generation and correlation map refinement. Specifically, we unveil a unique temporal correlation module that dynamically assesses the interplay between the template and search region features. This module leverages temporal information to refresh the template feature, yielding a more precise correlation map. Subsequently, we propose a mutual transformer module to refine the correlation maps of historical and current frames by modeling the temporal knowledge in the tracking sequence. This method significantly trims computational demands compared to the raw transformer. The compact yet potent nature of our tracking framework ensures commendable tracking outcomes, particularly in extended tracking scenarios.
MSINet: Twins Contrastive Search of Multi-Scale Interaction for Object ReID
Mar 13, 2023



Neural Architecture Search (NAS) has been increasingly appealing to the society of object Re-Identification (ReID), for that task-specific architectures significantly improve the retrieval performance. Previous works explore new optimizing targets and search spaces for NAS ReID, yet they neglect the difference of training schemes between image classification and ReID. In this work, we propose a novel Twins Contrastive Mechanism (TCM) to provide more appropriate supervision for ReID architecture search. TCM reduces the category overlaps between the training and validation data, and assists NAS in simulating real-world ReID training schemes. We then design a Multi-Scale Interaction (MSI) search space to search for rational interaction operations between multi-scale features. In addition, we introduce a Spatial Alignment Module (SAM) to further enhance the attention consistency confronted with images from different sources. Under the proposed NAS scheme, a specific architecture is automatically searched, named as MSINet. Extensive experiments demonstrate that our method surpasses state-of-the-art ReID methods on both in-domain and cross-domain scenarios. Source code available in https://github.com/vimar-gu/MSINet.
A Preliminary Research on Space Situational Awareness Based on Event Cameras
Mar 25, 2022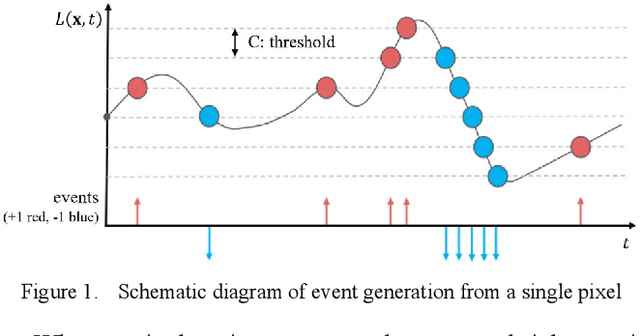


Event camera is a new type of sensor that is different from traditional cameras. Each pixel is triggered asynchronously by an event. The trigger event is the change of the brightness irradiated on the pixel. If the increment or decrement is higher than a certain threshold, the event is output. Compared with traditional cameras, event cameras have the advantages of high temporal resolution, low latency, high dynamic range, low bandwidth and low power consumption. We carried out a series of observation experiments in a simulated space lighting environment. The experimental results show that the event camera can give full play to the above advantages in space situational awareness. This article first introduces the basic principles of the event camera, then analyzes its advantages and disadvantages, then introduces the observation experiment and analyzes the experimental results, and finally, a workflow of space situational awareness based on event cameras is given.
Unified Structured Learning for Simultaneous Human Pose Estimation and Garment Attribute Classification
Sep 22, 2014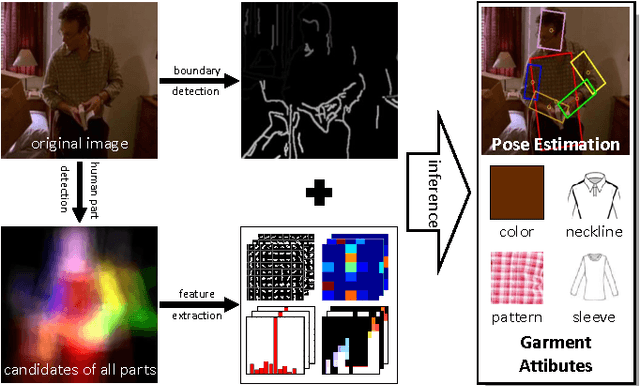


In this paper, we utilize structured learning to simultaneously address two intertwined problems: human pose estimation (HPE) and garment attribute classification (GAC), which are valuable for a variety of computer vision and multimedia applications. Unlike previous works that usually handle the two problems separately, our approach aims to produce a jointly optimal estimation for both HPE and GAC via a unified inference procedure. To this end, we adopt a preprocessing step to detect potential human parts from each image (i.e., a set of "candidates") that allows us to have a manageable input space. In this way, the simultaneous inference of HPE and GAC is converted to a structured learning problem, where the inputs are the collections of candidate ensembles, the outputs are the joint labels of human parts and garment attributes, and the joint feature representation involves various cues such as pose-specific features, garment-specific features, and cross-task features that encode correlations between human parts and garment attributes. Furthermore, we explore the "strong edge" evidence around the potential human parts so as to derive more powerful representations for oriented human parts. Such evidences can be seamlessly integrated into our structured learning model as a kind of energy function, and the learning process could be performed by standard structured Support Vector Machines (SVM) algorithm. However, the joint structure of the two problems is a cyclic graph, which hinders efficient inference. To resolve this issue, we compute instead approximate optima by using an iterative procedure, where in each iteration the variables of one problem are fixed. In this way, satisfactory solutions can be efficiently computed by dynamic programming. Experimental results on two benchmark datasets show the state-of-the-art performance of our approach.
Cross-Scale Cost Aggregation for Stereo Matching
Mar 03, 2014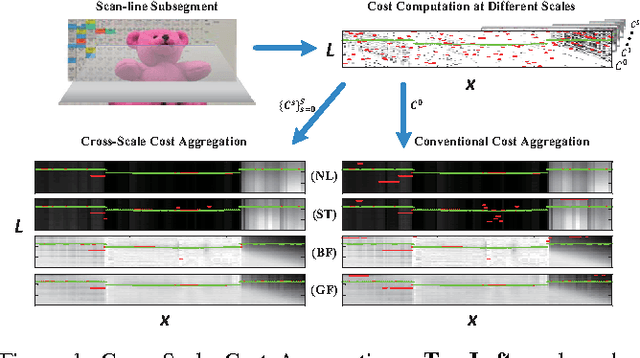
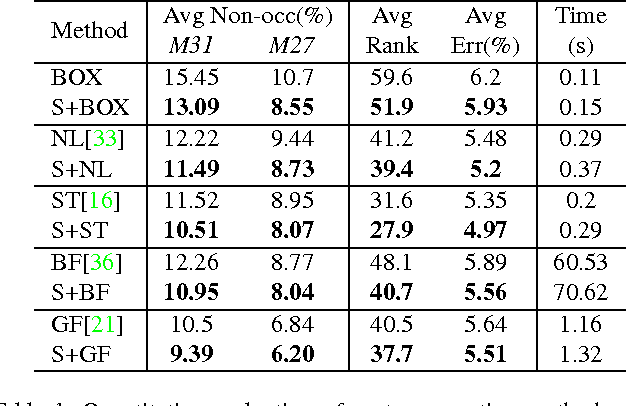
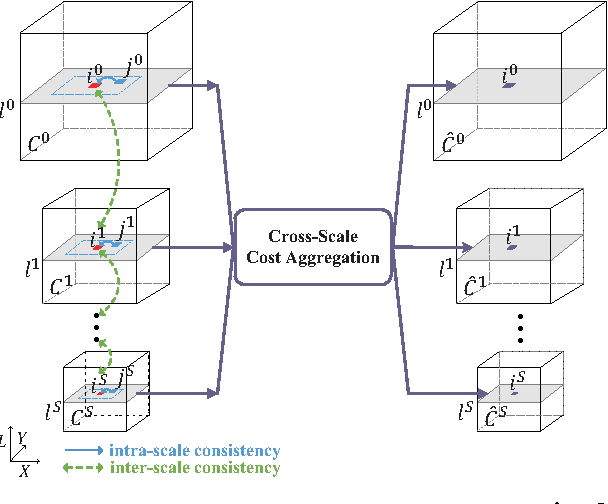
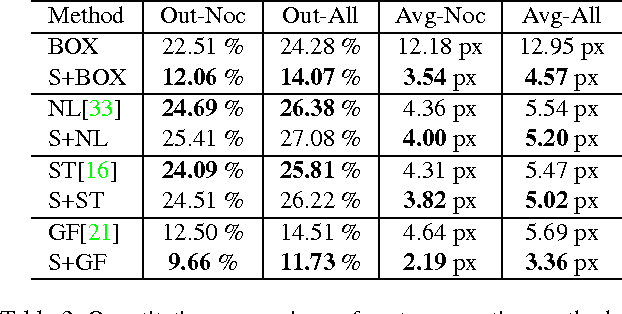
Human beings process stereoscopic correspondence across multiple scales. However, this bio-inspiration is ignored by state-of-the-art cost aggregation methods for dense stereo correspondence. In this paper, a generic cross-scale cost aggregation framework is proposed to allow multi-scale interaction in cost aggregation. We firstly reformulate cost aggregation from a unified optimization perspective and show that different cost aggregation methods essentially differ in the choices of similarity kernels. Then, an inter-scale regularizer is introduced into optimization and solving this new optimization problem leads to the proposed framework. Since the regularization term is independent of the similarity kernel, various cost aggregation methods can be integrated into the proposed general framework. We show that the cross-scale framework is important as it effectively and efficiently expands state-of-the-art cost aggregation methods and leads to significant improvements, when evaluated on Middlebury, KITTI and New Tsukuba datasets.