 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Scaling over Perception: Resolving the Grounding Paradox in Thinking with Images
Apr 13, 2026Recent multimodal large language models (MLLMs) have begun to support Thinking with Images by invoking visual tools such as zooming and cropping during inference. Yet these systems remain brittle in fine-grained visual reasoning because they must decide where to look before they have access to the evidence needed to make that decision correctly. We identify this circular dependency as the Grounding Paradox. To address it, we propose Test-Time Scaling over Perception (TTSP), a framework that treats perception itself as a scalable inference process. TTSP generates multiple exploratory perception traces, filters unreliable traces using entropy-based confidence estimation, distills validated observations into structured knowledge, and iteratively refines subsequent exploration toward unresolved uncertainty. Extensive experiments on high-resolution and general multimodal reasoning benchmarks show that TTSP consistently outperforms strong baselines across backbone sizes, while also exhibiting favorable scalability and token efficiency. Our results suggest that scaling perception at test time is a promising direction for robust multimodal reasoning under perceptual uncertainty.
MedVR: Annotation-Free Medical Visual Reasoning via Agentic Reinforcement Learning
Apr 09, 2026Medical Vision-Language Models (VLMs) hold immense promise for complex clinical tasks, but their reasoning capabilities are often constrained by text-only paradigms that fail to ground inferences in visual evidence. This limitation not only curtails performance on tasks requiring fine-grained visual analysis but also introduces risks of visual hallucination in safety-critical applications. Thus, we introduce MedVR, a novel reinforcement learning framework that enables annotation-free visual reasoning for medical VLMs. Its core innovation lies in two synergistic mechanisms: Entropy-guided Visual Regrounding (EVR) uses model uncertainty to direct exploration, while Consensus-based Credit Assignment (CCA) distills pseudo-supervision from rollout agreement. Without any human annotations for intermediate steps, MedVR achieves state-of-the-art performance on diverse public medical VQA benchmarks, significantly outperforming existing models. By learning to reason directly with visual evidence, MedVR promotes the robustness and transparency essential for accelerating the clinical deployment of medical AI.
SubFLOT: Submodel Extraction for Efficient and Personalized Federated Learning via Optimal Transport
Apr 08, 2026Federated Learning (FL) enables collaborative model training while preserving data privacy, but its practical deployment is hampered by system and statistical heterogeneity. While federated network pruning offers a path to mitigate these issues, existing methods face a critical dilemma: server-side pruning lacks personalization, whereas client-side pruning is computationally prohibitive for resource-constrained devices. Furthermore, the pruning process itself induces significant parametric divergence among heterogeneous submodels, destabilizing training and hindering global convergence. To address these challenges, we propose SubFLOT, a novel framework for server-side personalized federated pruning. SubFLOT introduces an Optimal Transport-enhanced Pruning (OTP) module that treats historical client models as proxies for local data distributions, formulating the pruning task as a Wasserstein distance minimization problem to generate customized submodels without accessing raw data. Concurrently, to counteract parametric divergence, our Scaling-based Adaptive Regularization (SAR) module adaptively penalizes a submodel's deviation from the global model, with the penalty's strength scaled by the client's pruning rate. Comprehensive experiments demonstrate that SubFLOT consistently and substantially outperforms state-of-the-art methods, underscoring its potential for deploying efficient and personalized models on resource-constrained edge devices.
Decoupling Defense Strategies for Robust Image Watermarking
Feb 23, 2026Deep learning-based image watermarking, while robust against conventional distortions, remains vulnerable to advanced adversarial and regeneration attacks. Conventional countermeasures, which jointly optimize the encoder and decoder via a noise layer, face 2 inevitable challenges: (1) decrease of clean accuracy due to decoder adversarial training and (2) limited robustness due to simultaneous training of all three advanced attacks. To overcome these issues, we propose AdvMark, a novel two-stage fine-tuning framework that decouples the defense strategies. In stage 1, we address adversarial vulnerability via a tailored adversarial training paradigm that primarily fine-tunes the encoder while only conditionally updating the decoder. This approach learns to move the image into a non-attackable region, rather than modifying the decision boundary, thus preserving clean accuracy. In stage 2, we tackle distortion and regeneration attacks via direct image optimization. To preserve the adversarial robustness gained in stage 1, we formulate a principled, constrained image loss with theoretical guarantees, which balances the deviation from cover and previous encoded images. We also propose a quality-aware early-stop to further guarantee the lower bound of visual quality. Extensive experiments demonstrate AdvMark outperforms with the highest image quality and comprehensive robustness, i.e. up to 29\%, 33\% and 46\% accuracy improvement for distortion, regeneration and adversarial attacks, respectively.
HiVid: LLM-Guided Video Saliency For Content-Aware VOD And Live Streaming
Feb 15, 2026Content-aware streaming requires dynamic, chunk-level importance weights to optimize subjective quality of experience (QoE). However, direct human annotation is prohibitively expensive while vision-saliency models generalize poorly. We introduce HiVid, the first framework to leverage Large Language Models (LLMs) as a scalable human proxy to generate high-fidelity weights for both Video-on-Demand (VOD) and live streaming. We address 3 non-trivial challenges: (1) To extend LLMs' limited modality and circumvent token limits, we propose a perception module to assess frames in a local context window, autoregressively building a coherent understanding of the video. (2) For VOD with rating inconsistency across local windows, we propose a ranking module to perform global re-ranking with a novel LLM-guided merge-sort algorithm. (3) For live streaming which requires low-latency, online inference without future knowledge, we propose a prediction module to predict future weights with a multi-modal time series model, which comprises a content-aware attention and adaptive horizon to accommodate asynchronous LLM inference. Extensive experiments show HiVid improves weight prediction accuracy by up to 11.5\% for VOD and 26\% for live streaming over SOTA baselines. Real-world user study validates HiVid boosts streaming QoE correlation by 14.7\%.
RRNet: Configurable Real-Time Video Enhancement with Arbitrary Local Lighting Variations
Jan 05, 2026With the growing demand for real-time video enhancement in live applications, existing methods often struggle to balance speed and effective exposure control, particularly under uneven lighting. We introduce RRNet (Rendering Relighting Network), a lightweight and configurable framework that achieves a state-of-the-art tradeoff between visual quality and efficiency. By estimating parameters for a minimal set of virtual light sources, RRNet enables localized relighting through a depth-aware rendering module without requiring pixel-aligned training data. This object-aware formulation preserves facial identity and supports real-time, high-resolution performance using a streamlined encoder and lightweight prediction head. To facilitate training, we propose a generative AI-based dataset creation pipeline that synthesizes diverse lighting conditions at low cost. With its interpretable lighting control and efficient architecture, RRNet is well suited for practical applications such as video conferencing, AR-based portrait enhancement, and mobile photography. Experiments show that RRNet consistently outperforms prior methods in low-light enhancement, localized illumination adjustment, and glare removal.
A General Method For Automatic Discovery of Powerful Interactions In Click-Through Rate Prediction
May 21, 2021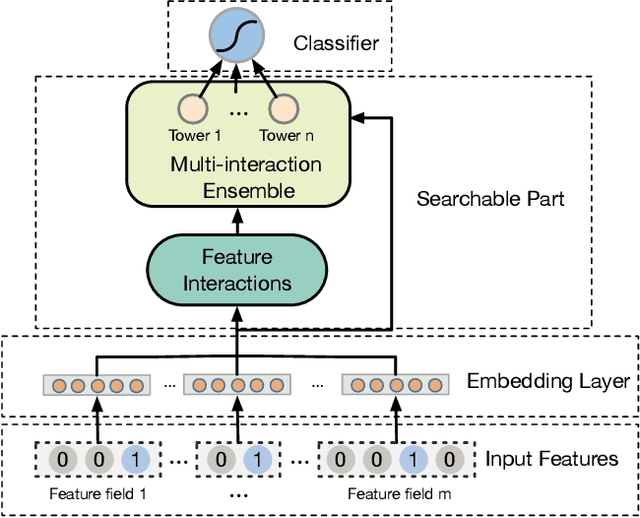
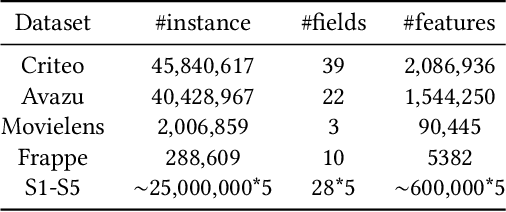
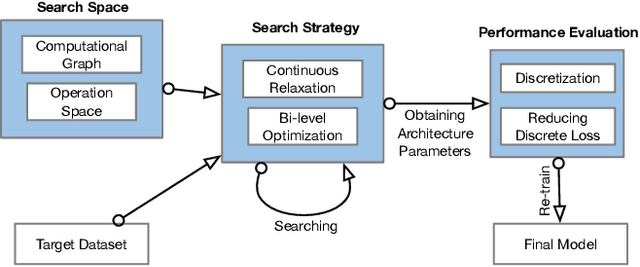
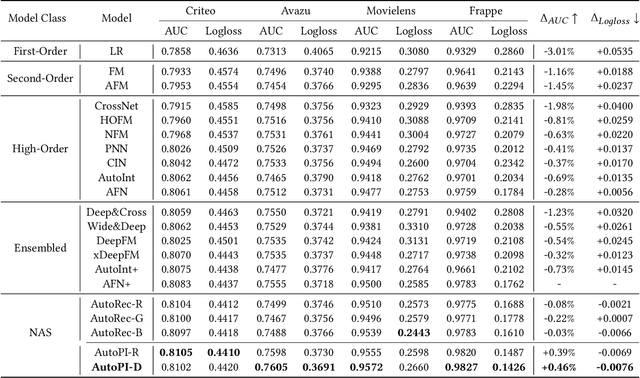
Modeling powerful interactions is a critical challenge in Click-through rate (CTR) prediction, which is one of the most typical machine learning tasks in personalized advertising and recommender systems. Although developing hand-crafted interactions is effective for a small number of datasets, it generally requires laborious and tedious architecture engineering for extensive scenarios. In recent years, several neural architecture search (NAS) methods have been proposed for designing interactions automatically. However, existing methods only explore limited types and connections of operators for interaction generation, leading to low generalization ability. To address these problems, we propose a more general automated method for building powerful interactions named AutoPI. The main contributions of this paper are as follows: AutoPI adopts a more general search space in which the computational graph is generalized from existing network connections, and the interactive operators in the edges of the graph are extracted from representative hand-crafted works. It allows searching for various powerful feature interactions to produce higher AUC and lower Logloss in a wide variety of applications. Besides, AutoPI utilizes a gradient-based search strategy for exploration with a significantly low computational cost. Experimentally, we evaluate AutoPI on a diverse suite of benchmark datasets, demonstrating the generalizability and efficiency of AutoPI over hand-crafted architectures and state-of-the-art NAS algorithms.
Continual Local Training for Better Initialization of Federated Models
May 26, 2020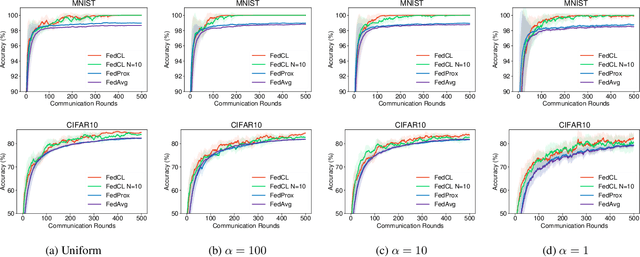
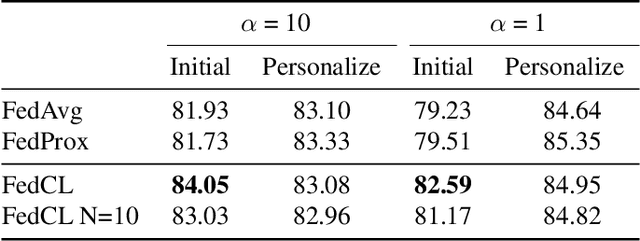
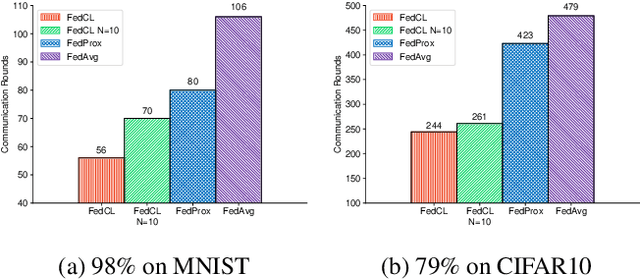
Federated learning (FL) refers to the learning paradigm that trains machine learning models directly in the decentralized systems consisting of smart edge devices without transmitting the raw data, which avoids the heavy communication costs and privacy concerns. Given the typical heterogeneous data distributions in such situations, the popular FL algorithm \emph{Federated Averaging} (FedAvg) suffers from weight divergence and thus cannot achieve a competitive performance for the global model (denoted as the \emph{initial performance} in FL) compared to centralized methods. In this paper, we propose the local continual training strategy to address this problem. Importance weights are evaluated on a small proxy dataset on the central server and then used to constrain the local training. With this additional term, we alleviate the weight divergence and continually integrate the knowledge on different local clients into the global model, which ensures a better generalization ability. Experiments on various FL settings demonstrate that our method significantly improves the initial performance of federated models with few extra communication costs.
Adversarial Feature Alignment: Avoid Catastrophic Forgetting in Incremental Task Lifelong Learning
Oct 24, 2019Human beings are able to master a variety of knowledge and skills with ongoing learning. By contrast, dramatic performance degradation is observed when new tasks are added to an existing neural network model. This phenomenon, termed as \emph{Catastrophic Forgetting}, is one of the major roadblocks that prevent deep neural networks from achieving human-level artificial intelligence. Several research efforts, e.g. \emph{Lifelong} or \emph{Continual} learning algorithms, have been proposed to tackle this problem. However, they either suffer from an accumulating drop in performance as the task sequence grows longer, or require to store an excessive amount of model parameters for historical memory, or cannot obtain competitive performance on the new tasks. In this paper, we focus on the incremental multi-task image classification scenario. Inspired by the learning process of human students, where they usually decompose complex tasks into easier goals, we propose an adversarial feature alignment method to avoid catastrophic forgetting. In our design, both the low-level visual features and high-level semantic features serve as soft targets and guide the training process in multiple stages, which provide sufficient supervised information of the old tasks and help to reduce forgetting. Due to the knowledge distillation and regularization phenomenons, the proposed method gains even better performance than finetuning on the new tasks, which makes it stand out from other methods. Extensive experiments in several typical lifelong learning scenarios demonstrate that our method outperforms the state-of-the-art methods in both accuracies on new tasks and performance preservation on old tasks.
Federated Learning with Unbiased Gradient Aggregation and Controllable Meta Updating
Oct 22, 2019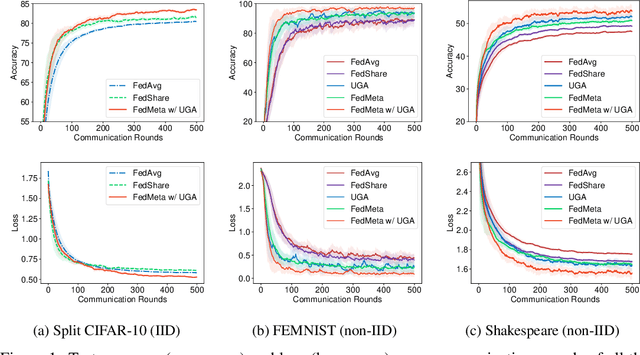
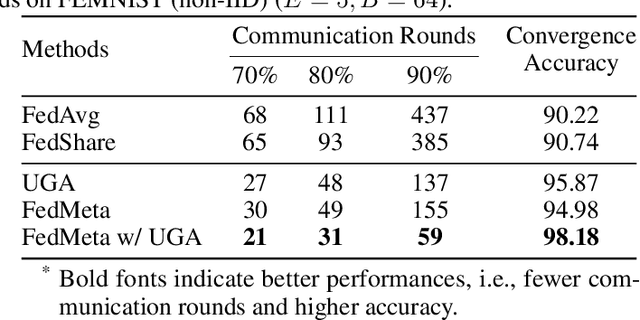
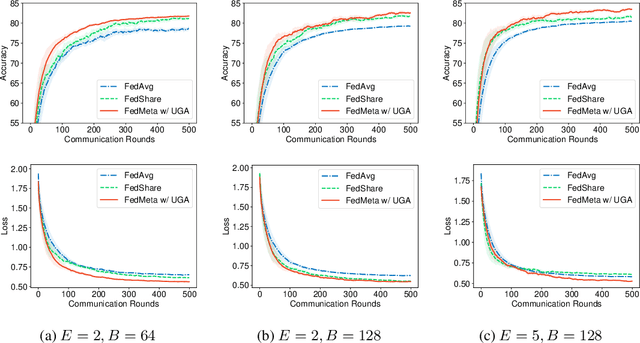
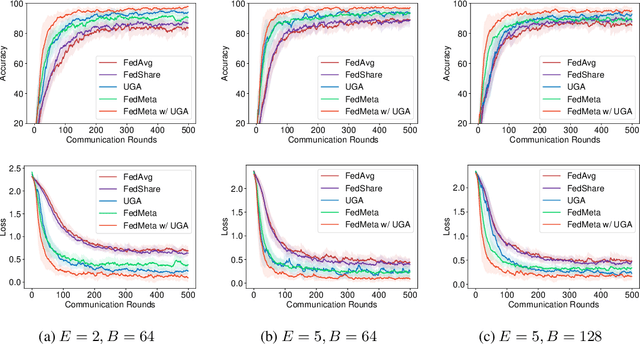
Federated Averaging (FedAvg) serves as the fundamental framework in Federated Learning (FL) settings. However, we argue that 1) the multiple steps of local updating will result in gradient biases and 2) there is an inconsistency between the target distribution and the optimization objectives following the training paradigm in FedAvg. To tackle these problems, we first propose an unbiased gradient aggregation algorithm with the keep-trace gradient descent and gradient evaluation strategy. Then we introduce a meta updating procedure with a controllable meta training set to provide a clear and consistent optimization objective. Experimental results demonstrate that the proposed methods outperform compared ones with various network architectures in both the IID and non-IID FL settings.