 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqformer: Image-Demoiréing Transformer via Efficient Frequency Decomposition
May 25, 2025



Image demoir\'eing remains a challenging task due to the complex interplay between texture corruption and color distortions caused by moir\'e patterns. Existing methods, especially those relying on direct image-to-image restoration, often fail to disentangle these intertwined artifacts effectively. While wavelet-based frequency-aware approaches offer a promising direction, their potential remains underexplored. In this paper, we present Freqformer, a Transformer-based framework specifically designed for image demoir\'eing through targeted frequency separation. Our method performs an effective frequency decomposition that explicitly splits moir\'e patterns into high-frequency spatially-localized textures and low-frequency scale-robust color distortions, which are then handled by a dual-branch architecture tailored to their distinct characteristics. We further propose a learnable Frequency Composition Transform (FCT) module to adaptively fuse the frequency-specific outputs, enabling consistent and high-fidelity reconstruction. To better aggregate the spatial dependencies and the inter-channel complementary information, we introduce a Spatial-Aware Channel Attention (SA-CA) module that refines moir\'e-sensitive regions without incurring high computational cost. Extensive experiments on various demoir\'eing benchmarks demonstrate that Freqformer achieves state-of-the-art performance with a compact model size. The code is publicly available at https://github.com/xyLiu339/Freqformer.
DVD-Quant: Data-free Video Diffusion Transformers Quantization
May 24, 2025Diffusion Transformers (DiTs) have emerged as the state-of-the-art architecture for video generation, yet their computational and memory demands hinder practical deployment. While post-training quantization (PTQ) presents a promising approach to accelerate Video DiT models, existing methods suffer from two critical limitations: (1) dependence on lengthy, computation-heavy calibration procedures, and (2) considerable performance deterioration after quantization. To address these challenges, we propose DVD-Quant, a novel Data-free quantization framework for Video DiTs. Our approach integrates three key innovations: (1) Progressive Bounded Quantization (PBQ) and (2) Auto-scaling Rotated Quantization (ARQ) for calibration data-free quantization error reduction, as well as (3) $\delta$-Guided Bit Switching ($\delta$-GBS) for adaptive bit-width allocation. Extensive experiments across multiple video generation benchmarks demonstrate that DVD-Quant achieves an approximately 2$\times$ speedup over full-precision baselines on HunyuanVideo while maintaining visual fidelity. Notably, DVD-Quant is the first to enable W4A4 PTQ for Video DiTs without compromising video quality. Code and models will be available at https://github.com/lhxcs/DVD-Quant.
HonestFace: Towards Honest Face Restoration with One-Step Diffusion Model
May 24, 2025Face restoration has achieved remarkable advancements through the years of development. However, ensuring that restored facial images exhibit high fidelity, preserve authentic features, and avoid introducing artifacts or biases remains a significant challenge. This highlights the need for models that are more "honest" in their reconstruction from low-quality inputs, accurately reflecting original characteristics. In this work, we propose HonestFace, a novel approach designed to restore faces with a strong emphasis on such honesty, particularly concerning identity consistency and texture realism. To achieve this, HonestFace incorporates several key components. First, we propose an identity embedder to effectively capture and preserve crucial identity features from both the low-quality input and multiple reference faces. Second, a masked face alignment method is presented to enhance fine-grained details and textural authenticity, thereby preventing the generation of patterned or overly synthetic textures and improving overall clarity. Furthermore, we present a new landmark-based evaluation metric. Based on affine transformation principles, this metric improves the accuracy compared to conventional L2 distance calculations for facial feature alignment. Leveraging these contributions within a one-step diffusion model framework, HonestFace delivers exceptional restoration results in terms of facial fidelity and realism. Extensive experiments demonstrate that our approach surpasses existing state-of-the-art methods, achieving superior performance in both visual quality and quantitative assessments. The code and pre-trained models will be made publicly available at https://github.com/jkwang28/HonestFace .
DOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution
May 22, 2025Diffusion models have demonstrated promising performance in real-world video super-resolution (VSR). However, the dozens of sampling steps they require, make inference extremely slow. Sampling acceleration techniques, particularly single-step, provide a potential solution. Nonetheless, achieving one step in VSR remains challenging, due to the high training overhead on video data and stringent fidelity demands. To tackle the above issues, we propose DOVE, an efficient one-step diffusion model for real-world VSR. DOVE is obtained by fine-tuning a pretrained video diffusion model (*i.e.*, CogVideoX). To effectively train DOVE, we introduce the latent-pixel training strategy. The strategy employs a two-stage scheme to gradually adapt the model to the video super-resolution task. Meanwhile, we design a video processing pipeline to construct a high-quality dataset tailored for VSR, termed HQ-VSR. Fine-tuning on this dataset further enhances the restoration capability of DOVE. Extensive experiments show that DOVE exhibits comparable or superior performance to multi-step diffusion-based VSR methods. It also offers outstanding inference efficiency, achieving up to a **28$\times$** speed-up over existing methods such as MGLD-VSR. Code is available at: https://github.com/zhengchen1999/DOVE.
OSCAR: One-Step Diffusion Codec Across Multiple Bit-rates
May 22, 2025Pretrained latent diffusion models have shown strong potential for lossy image compression, owing to their powerful generative priors. Most existing diffusion-based methods reconstruct images by iteratively denoising from random noise, guided by compressed latent representations. While these approaches have achieved high reconstruction quality, their multi-step sampling process incurs substantial computational overhead. Moreover, they typically require training separate models for different compression bit-rates, leading to significant training and storage costs. To address these challenges, we propose a one-step diffusion codec across multiple bit-rates. termed OSCAR. Specifically, our method views compressed latents as noisy variants of the original latents, where the level of distortion depends on the bit-rate. This perspective allows them to be modeled as intermediate states along a diffusion trajectory. By establishing a mapping from the compression bit-rate to a pseudo diffusion timestep, we condition a single generative model to support reconstructions at multiple bit-rates. Meanwhile, we argue that the compressed latents retain rich structural information, thereby making one-step denoising feasible. Thus, OSCAR replaces iterative sampling with a single denoising pass, significantly improving inference efficiency. Extensive experiments demonstrate that OSCAR achieves superior performance in both quantitative and visual quality metrics. The code and models will be released at https://github.com/jp-guo/OSCAR.
SGDPO: Self-Guided Direct Preference Optimization for Language Model Alignment
May 18, 2025Direct Preference Optimization (DPO) is broadly utilized for aligning Large Language Models (LLMs) with human values because of its flexibility. Despite its effectiveness, it has been observed that the capability of DPO to generate human-preferred response is limited and the results of DPO are far from resilient. To address these limitations, in this paper we propose a novel Self-Guided Direct Preference Optimization algorithm, i.e., SGDPO, which incorporates a pilot term to steer the gradient flow during the optimization process, allowing for fine-grained control over the updates of chosen and rejected rewards. We provide a detailed theoretical analysis of our proposed method and elucidate its operational mechanism. Furthermore, we conduct comprehensive experiments on various models and benchmarks. The extensive experimental results demonstrate the consistency between the empirical results and our theoretical analysis and confirm the effectiveness of our proposed approach (up to 9.19% higher score).
PMQ-VE: Progressive Multi-Frame Quantization for Video Enhancement
May 18, 2025



Multi-frame video enhancement tasks aim to improve the spatial and temporal resolution and quality of video sequences by leveraging temporal information from multiple frames, which are widely used in streaming video processing, surveillance, and generation. Although numerous Transformer-based enhancement methods have achieved impressive performance, their computational and memory demands hinder deployment on edge devices. Quantization offers a practical solution by reducing the bit-width of weights and activations to improve efficiency. However, directly applying existing quantization methods to video enhancement tasks often leads to significant performance degradation and loss of fine details. This stems from two limitations: (a) inability to allocate varying representational capacity across frames, which results in suboptimal dynamic range adaptation; (b) over-reliance on full-precision teachers, which limits the learning of low-bit student models. To tackle these challenges, we propose a novel quantization method for video enhancement: Progressive Multi-Frame Quantization for Video Enhancement (PMQ-VE). This framework features a coarse-to-fine two-stage process: Backtracking-based Multi-Frame Quantization (BMFQ) and Progressive Multi-Teacher Distillation (PMTD). BMFQ utilizes a percentile-based initialization and iterative search with pruning and backtracking for robust clipping bounds. PMTD employs a progressive distillation strategy with both full-precision and multiple high-bit (INT) teachers to enhance low-bit models' capacity and quality. Extensive experiments demonstrate that our method outperforms existing approaches, achieving state-of-the-art performance across multiple tasks and benchmarks.The code will be made publicly available at: https://github.com/xiaoBIGfeng/PMQ-VE.
UnfoldIR: Rethinking Deep Unfolding Network in Illumination Degradation Image Restoration
May 10, 2025Deep unfolding networks (DUNs) are widely employed in illumination degradation image restoration (IDIR) to merge the interpretability of model-based approaches with the generalization of learning-based methods. However, the performance of DUN-based methods remains considerably inferior to that of state-of-the-art IDIR solvers. Our investigation indicates that this limitation does not stem from structural shortcomings of DUNs but rather from the limited exploration of the unfolding structure, particularly for (1) constructing task-specific restoration models, (2) integrating advanced network architectures, and (3) designing DUN-specific loss functions. To address these issues, we propose a novel DUN-based method, UnfoldIR, for IDIR tasks. UnfoldIR first introduces a new IDIR model with dedicated regularization terms for smoothing illumination and enhancing texture. We unfold the iterative optimized solution of this model into a multistage network, with each stage comprising a reflectance-assisted illumination correction (RAIC) module and an illumination-guided reflectance enhancement (IGRE) module. RAIC employs a visual state space (VSS) to extract non-local features, enforcing illumination smoothness, while IGRE introduces a frequency-aware VSS to globally align similar textures, enabling mildly degraded regions to guide the enhancement of details in more severely degraded areas. This suppresses noise while enhancing details. Furthermore, given the multistage structure, we propose an inter-stage information consistent loss to maintain network stability in the final stages. This loss contributes to structural preservation and sustains the model's performance even in unsupervised settings. Experiments verify our effectiveness across 5 IDIR tasks and 3 downstream problems.
Low-bit Model Quantization for Deep Neural Networks: A Survey
May 08, 2025

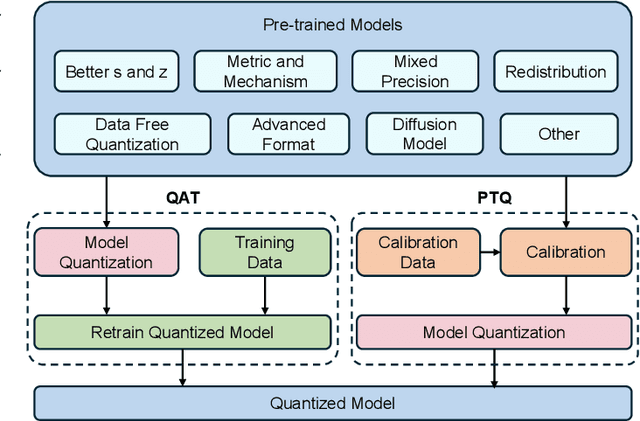
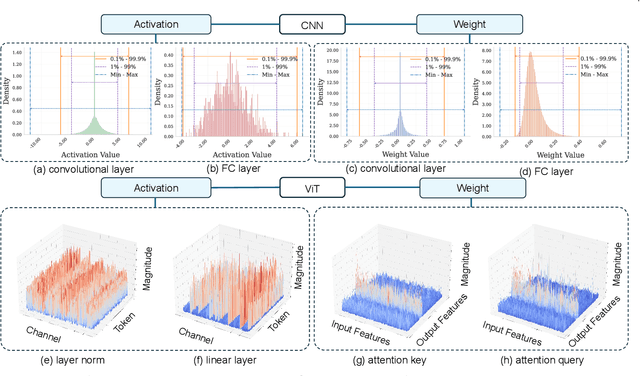
With unprecedented rapid development, deep neural networks (DNNs) have deeply influenced almost all fields. However, their heavy computation costs and model sizes are usually unacceptable in real-world deployment. Model quantization, an effective weight-lighting technique, has become an indispensable procedure in the whole deployment pipeline. The essence of quantization acceleration is the conversion from continuous floating-point numbers to discrete integer ones, which significantly speeds up the memory I/O and calculation, i.e., addition and multiplication. However, performance degradation also comes with the conversion because of the loss of precision. Therefore, it has become increasingly popular and critical to investigate how to perform the conversion and how to compensate for the information loss. This article surveys the recent five-year progress towards low-bit quantization on DNNs. We discuss and compare the state-of-the-art quantization methods and classify them into 8 main categories and 24 sub-categories according to their core techniques. Furthermore, we shed light on the potential research opportunities in the field of model quantization. A curated list of model quantization is provided at https://github.com/Kai-Liu001/Awesome-Model-Quantization.
NTIRE 2025 Challenge on Real-World Face Restoration: Methods and Results
Apr 20, 2025This paper provides a review of the NTIRE 2025 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural, realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. The track of the challenge evaluates performance using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 141 registrants, with 13 teams submitting valid models, and ultimately, 10 teams achieved a valid score in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.