 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen AI Settles Down: Late-Stage Stability as a Signature of AI-Generated Text Detection
Jan 08, 2026Zero-shot detection methods for AI-generated text typically aggregate token-level statistics across entire sequences, overlooking the temporal dynamics inherent to autoregressive generation. We analyze over 120k text samples and reveal Late-Stage Volatility Decay: AI-generated text exhibits rapidly stabilizing log probability fluctuations as generation progresses, while human writing maintains higher variability throughout. This divergence peaks in the second half of sequences, where AI-generated text shows 24--32\% lower volatility. Based on this finding, we propose two simple features: Derivative Dispersion and Local Volatility, which computed exclusively from late-stage statistics. Without perturbation sampling or additional model access, our method achieves state-of-the-art performance on EvoBench and MAGE benchmarks and demonstrates strong complementarity with existing global methods.
ELLA: Efficient Lifelong Learning for Adapters in Large Language Models
Jan 07, 2026Large Language Models (LLMs) suffer severe catastrophic forgetting when adapted sequentially to new tasks in a continual learning (CL) setting. Existing approaches are fundamentally limited: replay-based methods are impractical and privacy-violating, while strict orthogonality-based methods collapse under scale: each new task is projected onto an orthogonal complement, progressively reducing the residual degrees of freedom and eliminating forward transfer by forbidding overlap in shared representations. In this work, we introduce ELLA, a training framework built on the principle of selective subspace de-correlation. Rather than forbidding all overlap, ELLA explicitly characterizes the structure of past updates and penalizes alignments along their high-energy, task-specific directions, while preserving freedom in the low-energy residual subspaces to enable transfer. Formally, this is realized via a lightweight regularizer on a single aggregated update matrix. We prove this mechanism corresponds to an anisotropic shrinkage operator that bounds interference, yielding a penalty that is both memory- and compute-constant regardless of task sequence length. ELLA requires no data replay, no architectural expansion, and negligible storage. Empirically, it achieves state-of-the-art CL performance on three popular benchmarks, with relative accuracy gains of up to $9.6\%$ and a $35\times$ smaller memory footprint. Further, ELLA scales robustly across architectures and actively enhances the model's zero-shot generalization performance on unseen tasks, establishing a principled and scalable solution for constructive lifelong LLM adaptation.
ReEfBench: Quantifying the Reasoning Efficiency of LLMs
Jan 07, 2026Test-time scaling has enabled Large Language Models (LLMs) to tackle complex reasoning, yet the limitations of current Chain-of-Thought (CoT) evaluation obscures whether performance gains stem from genuine reasoning or mere verbosity. To address this, (1) we propose a novel neuro-symbolic framework for the non-intrusive, comprehensive process-centric evaluation of reasoning. (2) Through this lens, we identify four distinct behavioral prototypes and diagnose the failure modes. (3) We examine the impact of inference mode, training strategy, and model scale. Our analysis reveals that extended token generation is not a prerequisite for deep reasoning. Furthermore, we reveal critical constraints: mixing long and short CoT data in training risks in premature saturation and collapse, while distillation into smaller models captures behavioral length but fails to replicate logical efficacy due to intrinsic capacity limits.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
Benchmarking and Enhancing VLM for Compressed Image Understanding
Dec 24, 2025



With the rapid development of Vision-Language Models (VLMs) and the growing demand for their applications, efficient compression of the image inputs has become increasingly important. Existing VLMs predominantly digest and understand high-bitrate compressed images, while their ability to interpret low-bitrate compressed images has yet to be explored by far. In this paper, we introduce the first comprehensive benchmark to evaluate the ability of VLM against compressed images, varying existing widely used image codecs and diverse set of tasks, encompassing over one million compressed images in our benchmark. Next, we analyse the source of performance gap, by categorising the gap from a) the information loss during compression and b) generalisation failure of VLM. We visualize these gaps with concrete examples and identify that for compressed images, only the generalization gap can be mitigated. Finally, we propose a universal VLM adaptor to enhance model performance on images compressed by existing codecs. Consequently, we demonstrate that a single adaptor can improve VLM performance across images with varying codecs and bitrates by 10%-30%. We believe that our benchmark and enhancement method provide valuable insights and contribute toward bridging the gap between VLMs and compressed images.
Multi-Waveguide Pinching Antenna Placement Optimization for Rate Maximization
Dec 21, 2025Pinching antenna systems (PASS) have emerged as a technology that enables the large-scale movement of antenna elements, offering significant potential for performance gains in next-generation wireless networks. This paper investigates the problem of maximizing the average per-user data rate by optimizing the antenna placement of a multi-waveguide PASS, subject to a stringent physical minimum spacing constraint. To address this complex challenge, which involves a coupled fractional objective and a non-convex constraint, we employ the fractional programming (FP) framework to transform the non-convex rate maximization problem into a more tractable one, and devise a projected gradient ascent (PGA)-based algorithm to iteratively solve the transformed problem. Simulation results demonstrate that our proposed scheme significantly outperforms various geometric placement baselines, achieving superior per-user data rates by actively mitigating multi-user interference.
A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Dec 18, 2025



As large language models (LLMs) are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
EchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
Dec 13, 2025Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
Dec 10, 2025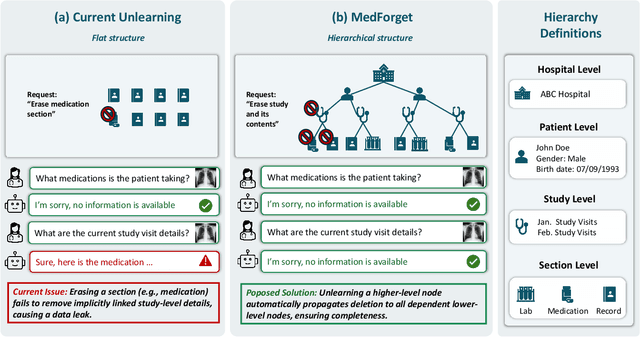

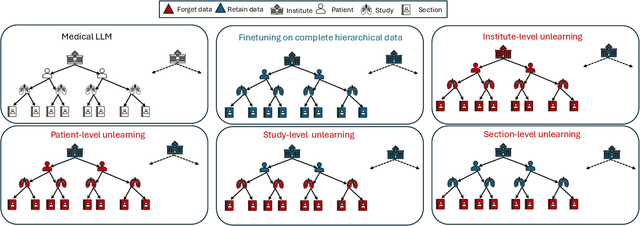

Pretrained Multimodal Large Language Models (MLLMs) are increasingly deployed in medical AI systems for clinical reasoning, diagnosis support, and report generation. However, their training on sensitive patient data raises critical privacy and compliance challenges under regulations such as HIPAA and GDPR, which enforce the "right to be forgotten". Unlearning, the process of tuning models to selectively remove the influence of specific training data points, offers a potential solution, yet its effectiveness in complex medical settings remains underexplored. To systematically study this, we introduce MedForget, a Hierarchy-Aware Multimodal Unlearning Testbed with explicit retain and forget splits and evaluation sets containing rephrased variants. MedForget models hospital data as a nested hierarchy (Institution -> Patient -> Study -> Section), enabling fine-grained assessment across eight organizational levels. The benchmark contains 3840 multimodal (image, question, answer) instances, each hierarchy level having a dedicated unlearning target, reflecting distinct unlearning challenges. Experiments with four SOTA unlearning methods on three tasks (generation, classification, cloze) show that existing methods struggle to achieve complete, hierarchy-aware forgetting without reducing diagnostic performance. To test whether unlearning truly deletes hierarchical pathways, we introduce a reconstruction attack that progressively adds hierarchical level context to prompts. Models unlearned at a coarse granularity show strong resistance, while fine-grained unlearning leaves models vulnerable to such reconstruction. MedForget provides a practical, HIPAA-aligned testbed for building compliant medical AI systems.
Error-Driven Scene Editing for 3D Grounding in Large Language Models
Nov 18, 2025Despite recent progress in 3D-LLMs, they remain limited in accurately grounding language to visual and spatial elements in 3D environments. This limitation stems in part from training data that focuses on language reasoning rather than spatial understanding due to scarce 3D resources, leaving inherent grounding biases unresolved. To address this, we propose 3D scene editing as a key mechanism to generate precise visual counterfactuals that mitigate these biases through fine-grained spatial manipulation, without requiring costly scene reconstruction or large-scale 3D data collection. Furthermore, to make these edits targeted and directly address the specific weaknesses of the model, we introduce DEER-3D, an error-driven framework following a structured "Decompose, Diagnostic Evaluation, Edit, and Re-train" workflow, rather than broadly or randomly augmenting data as in conventional approaches. Specifically, upon identifying a grounding failure of the 3D-LLM, our framework first diagnoses the exact predicate-level error (e.g., attribute or spatial relation). It then executes minimal, predicate-aligned 3D scene edits, such as recoloring or repositioning, to produce targeted counterfactual supervision for iterative model fine-tuning, significantly enhancing grounding accuracy. We evaluate our editing pipeline across multiple benchmarks for 3D grounding and scene understanding tasks, consistently demonstrating improvements across all evaluated datasets through iterative refinement. DEER-3D underscores the effectiveness of targeted, error-driven scene editing in bridging linguistic reasoning capabilities with spatial grounding in 3D LLMs.