 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaying Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
Apr 13, 2026As large language models (LLMs) become the engine behind conversational systems, their ability to reason about the intentions and states of their dialogue partners (i.e., form and use a theory-of-mind, or ToM) becomes increasingly critical for safe interaction with potentially adversarial partners. We propose a novel privacy-themed ToM challenge, ToM for Steering Beliefs (ToM-SB), in which a defender must act as a Double Agent to steer the beliefs of an attacker with partial prior knowledge within a shared universe. To succeed on ToM-SB, the defender must engage with and form a ToM of the attacker, with a goal of fooling the attacker into believing they have succeeded in extracting sensitive information. We find that strong frontier models like Gemini3-Pro and GPT-5.4 struggle on ToM-SB, often failing to fool attackers in hard scenarios with partial attacker prior knowledge, even when prompted to reason about the attacker's beliefs (ToM prompting). To close this gap, we train models on ToM-SB to act as AI Double Agents using reinforcement learning, testing both fooling and ToM rewards. Notably, we find a bidirectionally emergent relationship between ToM and attacker-fooling: rewarding fooling success alone improves ToM, and rewarding ToM alone improves fooling. Across four attackers with different strengths, six defender methods, and both in-distribution and out-of-distribution (OOD) evaluation, we find that gains in ToM and attacker-fooling are well-correlated, highlighting belief modeling as a key driver of success on ToM-SB. AI Double Agents that combine both ToM and fooling rewards yield the strongest fooling and ToM performance, outperforming Gemini3-Pro and GPT-5.4 with ToM prompting on hard scenarios. We also show that ToM-SB and AI Double Agents can be extended to stronger attackers, demonstrating generalization to OOD settings and the upgradability of our task.
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
Dec 10, 2025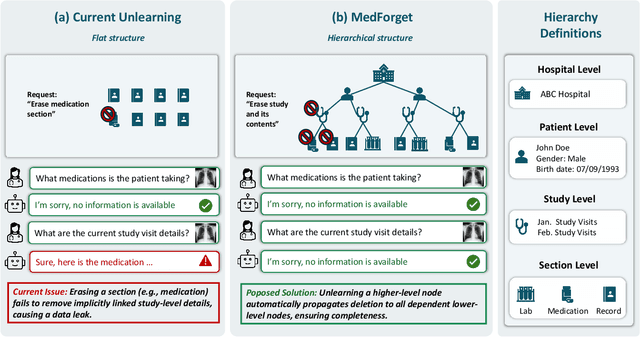

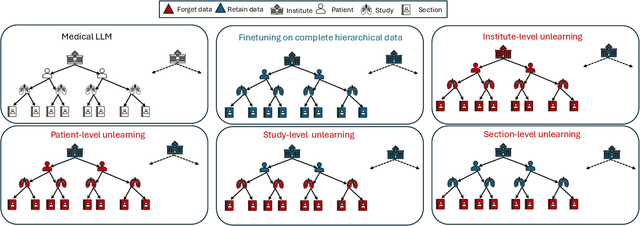

Pretrained Multimodal Large Language Models (MLLMs) are increasingly deployed in medical AI systems for clinical reasoning, diagnosis support, and report generation. However, their training on sensitive patient data raises critical privacy and compliance challenges under regulations such as HIPAA and GDPR, which enforce the "right to be forgotten". Unlearning, the process of tuning models to selectively remove the influence of specific training data points, offers a potential solution, yet its effectiveness in complex medical settings remains underexplored. To systematically study this, we introduce MedForget, a Hierarchy-Aware Multimodal Unlearning Testbed with explicit retain and forget splits and evaluation sets containing rephrased variants. MedForget models hospital data as a nested hierarchy (Institution -> Patient -> Study -> Section), enabling fine-grained assessment across eight organizational levels. The benchmark contains 3840 multimodal (image, question, answer) instances, each hierarchy level having a dedicated unlearning target, reflecting distinct unlearning challenges. Experiments with four SOTA unlearning methods on three tasks (generation, classification, cloze) show that existing methods struggle to achieve complete, hierarchy-aware forgetting without reducing diagnostic performance. To test whether unlearning truly deletes hierarchical pathways, we introduce a reconstruction attack that progressively adds hierarchical level context to prompts. Models unlearned at a coarse granularity show strong resistance, while fine-grained unlearning leaves models vulnerable to such reconstruction. MedForget provides a practical, HIPAA-aligned testbed for building compliant medical AI systems.
Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation
May 01, 2025



LLMs trained on massive datasets may inadvertently acquire sensitive information such as personal details and potentially harmful content. This risk is further heightened in multimodal LLMs as they integrate information from multiple modalities (image and text). Adversaries can exploit this knowledge through multimodal prompts to extract sensitive details. Evaluating how effectively MLLMs can forget such information (targeted unlearning) necessitates the creation of high-quality, well-annotated image-text pairs. While prior work on unlearning has focused on text, multimodal unlearning remains underexplored. To address this gap, we first introduce a multimodal unlearning benchmark, UnLOK-VQA (Unlearning Outside Knowledge VQA), as well as an attack-and-defense framework to evaluate methods for deleting specific multimodal knowledge from MLLMs. We extend a visual question-answering dataset using an automated pipeline that generates varying-proximity samples for testing generalization and specificity, followed by manual filtering for maintaining high quality. We then evaluate six defense objectives against seven attacks (four whitebox, three blackbox), including a novel whitebox method leveraging interpretability of hidden states. Our results show multimodal attacks outperform text- or image-only ones, and that the most effective defense removes answer information from internal model states. Additionally, larger models exhibit greater post-editing robustness, suggesting that scale enhances safety. UnLOK-VQA provides a rigorous benchmark for advancing unlearning in MLLMs.
UPCORE: Utility-Preserving Coreset Selection for Balanced Unlearning
Feb 20, 2025



User specifications or legal frameworks often require information to be removed from pretrained models, including large language models (LLMs). This requires deleting or "forgetting" a set of data points from an already-trained model, which typically degrades its performance on other data points. Thus, a balance must be struck between removing information and keeping the model's other abilities intact, with a failure to balance this trade-off leading to poor deletion or an unusable model. To this end, we propose UPCORE (Utility-Preserving Coreset Selection), a method-agnostic data selection framework for mitigating collateral damage during unlearning. Finding that the model damage is correlated with the variance of the model's representations on the forget set, we selectively prune the forget set to remove outliers, thereby minimizing model degradation after unlearning. We evaluate UPCORE across three standard unlearning methods consistently achieving a superior balance between the competing objectives of deletion efficacy and model preservation. To better evaluate this trade-off, we introduce a new metric, measuring the area-under-the-curve (AUC) across standard metrics. We find that UPCORE improves both standard metrics and AUC, benefitting from positive transfer between the coreset and pruned points while reducing negative transfer from the forget set to points outside of it.
SAFREE: Training-Free and Adaptive Guard for Safe Text-to-Image And Video Generation
Oct 16, 2024



Recent advances in diffusion models have significantly enhanced their ability to generate high-quality images and videos, but they have also increased the risk of producing unsafe content. Existing unlearning/editing-based methods for safe generation remove harmful concepts from models but face several challenges: (1) They cannot instantly remove harmful concepts without training. (2) Their safe generation capabilities depend on collected training data. (3) They alter model weights, risking degradation in quality for content unrelated to toxic concepts. To address these, we propose SAFREE, a novel, training-free approach for safe T2I and T2V, that does not alter the model's weights. Specifically, we detect a subspace corresponding to a set of toxic concepts in the text embedding space and steer prompt embeddings away from this subspace, thereby filtering out harmful content while preserving intended semantics. To balance the trade-off between filtering toxicity and preserving safe concepts, SAFREE incorporates a novel self-validating filtering mechanism that dynamically adjusts the denoising steps when applying the filtered embeddings. Additionally, we incorporate adaptive re-attention mechanisms within the diffusion latent space to selectively diminish the influence of features related to toxic concepts at the pixel level. In the end, SAFREE ensures coherent safety checking, preserving the fidelity, quality, and safety of the output. SAFREE achieves SOTA performance in suppressing unsafe content in T2I generation compared to training-free baselines and effectively filters targeted concepts while maintaining high-quality images. It also shows competitive results against training-based methods. We extend SAFREE to various T2I backbones and T2V tasks, showcasing its flexibility and generalization. SAFREE provides a robust and adaptable safeguard for ensuring safe visual generation.
Debiasing Multimodal Models via Causal Information Minimization
Nov 28, 2023Most existing debiasing methods for multimodal models, including causal intervention and inference methods, utilize approximate heuristics to represent the biases, such as shallow features from early stages of training or unimodal features for multimodal tasks like VQA, etc., which may not be accurate. In this paper, we study bias arising from confounders in a causal graph for multimodal data and examine a novel approach that leverages causally-motivated information minimization to learn the confounder representations. Robust predictive features contain diverse information that helps a model generalize to out-of-distribution data. Hence, minimizing the information content of features obtained from a pretrained biased model helps learn the simplest predictive features that capture the underlying data distribution. We treat these features as confounder representations and use them via methods motivated by causal theory to remove bias from models. We find that the learned confounder representations indeed capture dataset biases, and the proposed debiasing methods improve out-of-distribution (OOD) performance on multiple multimodal datasets without sacrificing in-distribution performance. Additionally, we introduce a novel metric to quantify the sufficiency of spurious features in models' predictions that further demonstrates the effectiveness of our proposed methods. Our code is available at: https://github.com/Vaidehi99/CausalInfoMin
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
Sep 29, 2023Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover "deleted" information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe societal implications for real-world deployment of language models.
GEMS: Scene Expansion using Generative Models of Graphs
Jul 08, 2022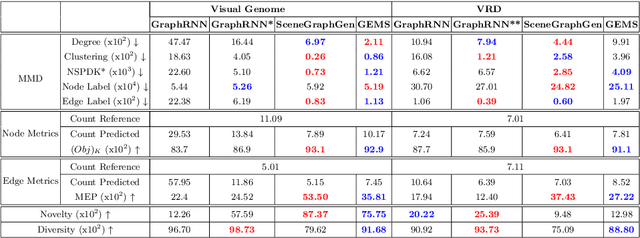
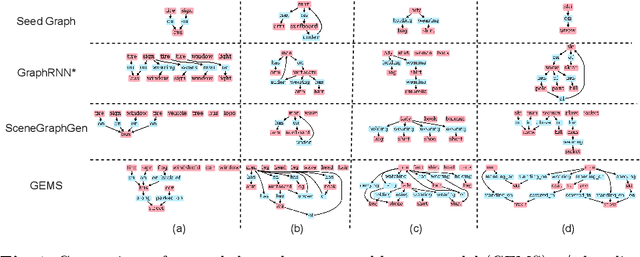
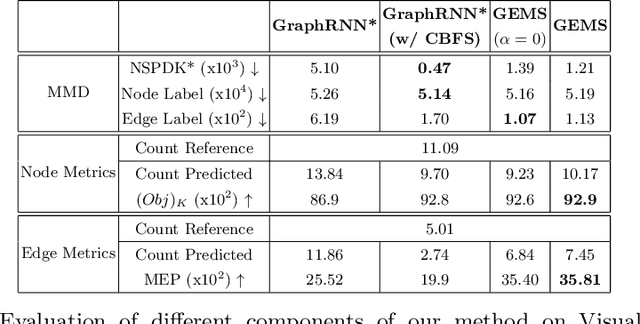
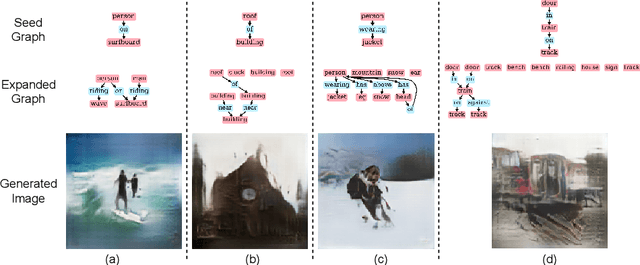
Applications based on image retrieval require editing and associating in intermediate spaces that are representative of the high-level concepts like objects and their relationships rather than dense, pixel-level representations like RGB images or semantic-label maps. We focus on one such representation, scene graphs, and propose a novel scene expansion task where we enrich an input seed graph by adding new nodes (objects) and the corresponding relationships. To this end, we formulate scene graph expansion as a sequential prediction task involving multiple steps of first predicting a new node and then predicting the set of relationships between the newly predicted node and previous nodes in the graph. We propose a sequencing strategy for observed graphs that retains the clustering patterns amongst nodes. In addition, we leverage external knowledge to train our graph generation model, enabling greater generalization of node predictions. Due to the inefficiency of existing maximum mean discrepancy (MMD) based metrics for graph generation problems in evaluating predicted relationships between nodes (objects), we design novel metrics that comprehensively evaluate different aspects of predicted relations. We conduct extensive experiments on Visual Genome and VRD datasets to evaluate the expanded scene graphs using the standard MMD-based metrics and our proposed metrics. We observe that the graphs generated by our method, GEMS, better represent the real distribution of the scene graphs than the baseline methods like GraphRNN.
Overlap-based Vocabulary Generation Improves Cross-lingual Transfer Among Related Languages
Mar 23, 2022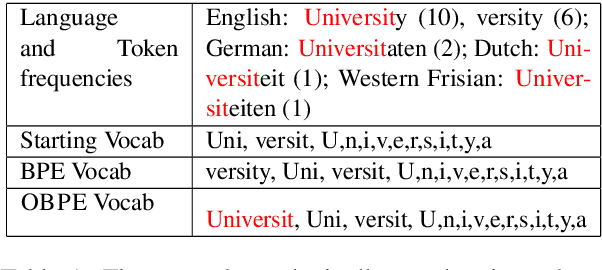
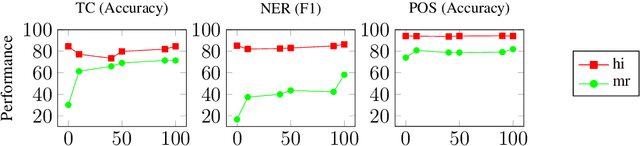


Pre-trained multilingual language models such as mBERT and XLM-R have demonstrated great potential for zero-shot cross-lingual transfer to low web-resource languages (LRL). However, due to limited model capacity, the large difference in the sizes of available monolingual corpora between high web-resource languages (HRL) and LRLs does not provide enough scope of co-embedding the LRL with the HRL, thereby affecting downstream task performance of LRLs. In this paper, we argue that relatedness among languages in a language family along the dimension of lexical overlap may be leveraged to overcome some of the corpora limitations of LRLs. We propose Overlap BPE (OBPE), a simple yet effective modification to the BPE vocabulary generation algorithm which enhances overlap across related languages. Through extensive experiments on multiple NLP tasks and datasets, we observe that OBPE generates a vocabulary that increases the representation of LRLs via tokens shared with HRLs. This results in improved zero-shot transfer from related HRLs to LRLs without reducing HRL representation and accuracy. Unlike previous studies that dismissed the importance of token-overlap, we show that in the low-resource related language setting, token overlap matters. Synthetically reducing the overlap to zero can cause as much as a four-fold drop in zero-shot transfer accuracy.
Characterization of a Meso-Scale Wearable Robot for Bathing Assistance
Feb 25, 2022
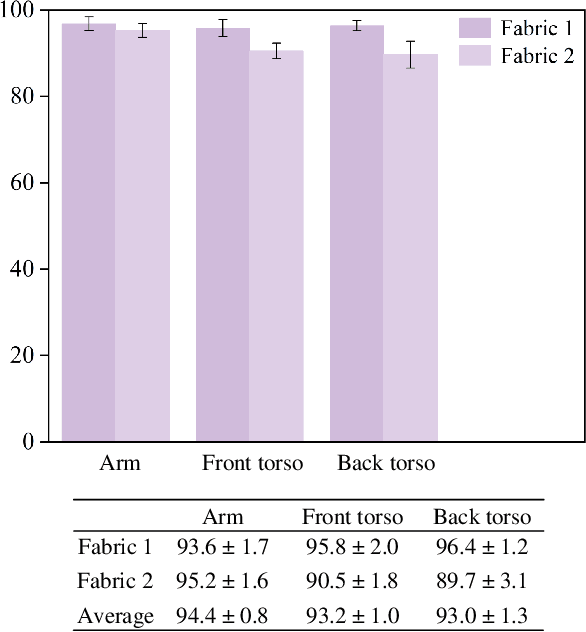
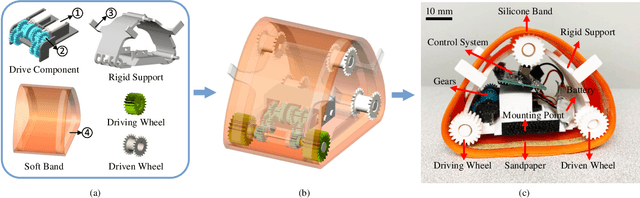
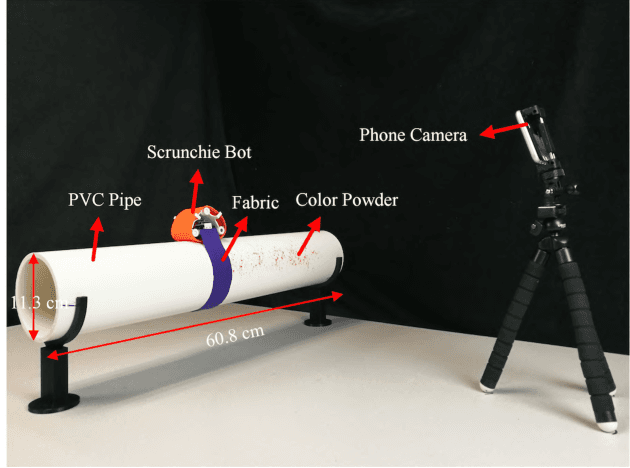
Robotic bathing assistance has long been considered an important and practical task in healthcare. Yet, achieving flexible and efficient cleaning tasks on the human body is challenging, since washing the body involves direct human-robot physical contact and simple, safe, and effective devices are needed for bathing and hygiene. In this paper, we present a meso-scale wearable robot that can locomote along the human body to provide bathing and skin care assistance. We evaluated the cleaning performance of the robot system under different scenarios. The experiments on the pipe show that the robot can achieve cleaning percentage over 92% with two types of stretchable fabrics. The robot removed most of the debris with average values of 94% on a human arm and 93% on a manikin torso. The results demonstrate that the robot exhibits high performance in cleaning tasks.