 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
Dec 13, 2025Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.
EchoApex: A General-Purpose Vision Foundation Model for Echocardiography
Oct 14, 2024



Quantitative evaluation of echocardiography is essential for precise assessment of cardiac condition, monitoring disease progression, and guiding treatment decisions. The diverse nature of echo images, including variations in probe types, manufacturers, and pathologies, poses challenges for developing artificial intelligent models that can generalize across different clinical practice. We introduce EchoApex, the first general-purpose vision foundation model echocardiography with applications on a variety of clinical practice. Leveraging self-supervised learning, EchoApex is pretrained on over 20 million echo images from 11 clinical centres. By incorporating task-specific decoders and adapter modules, we demonstrate the effectiveness of EchoApex on 4 different kind of clinical applications with 28 sub-tasks, including view classification, interactive structure segmentation, left ventricle hypertrophy detection and automated ejection fraction estimation from view sequences. Compared to state-of-the-art task-specific models, EchoApex attains improved performance with a unified image encoding architecture, demonstrating the benefits of model pretraining at scale with in-domain data. Furthermore, EchoApex illustrates the potential for developing a general-purpose vision foundation model tailored specifically for echocardiography, capable of addressing a diverse range of clinical applications with high efficiency and efficacy.
Goal-conditioned reinforcement learning for ultrasound navigation guidance
May 02, 2024



Transesophageal echocardiography (TEE) plays a pivotal role in cardiology for diagnostic and interventional procedures. However, using it effectively requires extensive training due to the intricate nature of image acquisition and interpretation. To enhance the efficiency of novice sonographers and reduce variability in scan acquisitions, we propose a novel ultrasound (US) navigation assistance method based on contrastive learning as goal-conditioned reinforcement learning (GCRL). We augment the previous framework using a novel contrastive patient batching method (CPB) and a data-augmented contrastive loss, both of which we demonstrate are essential to ensure generalization to anatomical variations across patients. The proposed framework enables navigation to both standard diagnostic as well as intricate interventional views with a single model. Our method was developed with a large dataset of 789 patients and obtained an average error of 6.56 mm in position and 9.36 degrees in angle on a testing dataset of 140 patients, which is competitive or superior to models trained on individual views. Furthermore, we quantitatively validate our method's ability to navigate to interventional views such as the Left Atrial Appendage (LAA) view used in LAA closure. Our approach holds promise in providing valuable guidance during transesophageal ultrasound examinations, contributing to the advancement of skill acquisition for cardiac ultrasound practitioners.
Cardiac ultrasound simulation for autonomous ultrasound navigation
Feb 09, 2024



Ultrasound is well-established as an imaging modality for diagnostic and interventional purposes. However, the image quality varies with operator skills as acquiring and interpreting ultrasound images requires extensive training due to the imaging artefacts, the range of acquisition parameters and the variability of patient anatomies. Automating the image acquisition task could improve acquisition reproducibility and quality but training such an algorithm requires large amounts of navigation data, not saved in routine examinations. Thus, we propose a method to generate large amounts of ultrasound images from other modalities and from arbitrary positions, such that this pipeline can later be used by learning algorithms for navigation. We present a novel simulation pipeline which uses segmentations from other modalities, an optimized volumetric data representation and GPU-accelerated Monte Carlo path tracing to generate view-dependent and patient-specific ultrasound images. We extensively validate the correctness of our pipeline with a phantom experiment, where structures' sizes, contrast and speckle noise properties are assessed. Furthermore, we demonstrate its usability to train neural networks for navigation in an echocardiography view classification experiment by generating synthetic images from more than 1000 patients. Networks pre-trained with our simulations achieve significantly superior performance in settings where large real datasets are not available, especially for under-represented classes. The proposed approach allows for fast and accurate patient-specific ultrasound image generation, and its usability for training networks for navigation-related tasks is demonstrated.
PRANet: Point Cloud Registration with an Artificial Agent
Sep 23, 2021
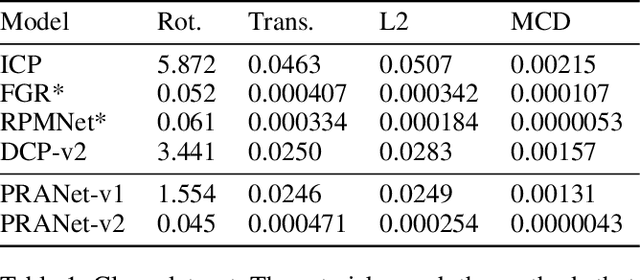
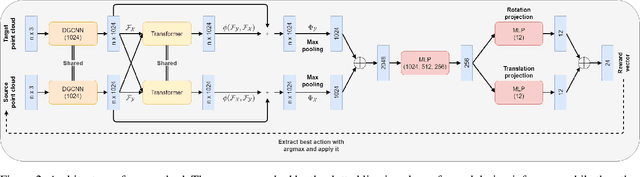
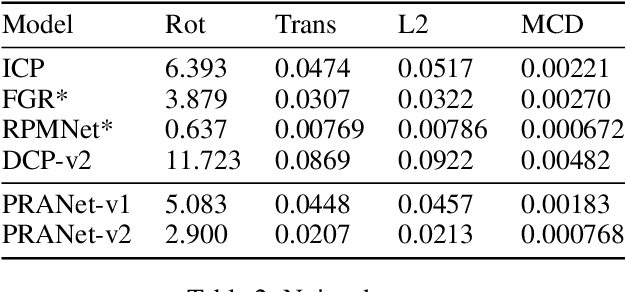
Point cloud registration plays a critical role in a multitude of computer vision tasks, such as pose estimation and 3D localization. Recently, a plethora of deep learning methods were formulated that aim to tackle this problem. Most of these approaches find point or feature correspondences, from which the transformations are computed. We give a different perspective and frame the registration problem as a Markov Decision Process. Instead of directly searching for the transformation, the problem becomes one of finding a sequence of translation and rotation actions that is equivalent to this transformation. To this end, we propose an artificial agent trained end-to-end using deep supervised learning. In contrast to conventional reinforcement learning techniques, the observations are sampled i.i.d. and thus no experience replay buffer is required, resulting in a more streamlined training process. Experiments on ModelNet40 show results comparable or superior to the state of the art in the case of clean, noisy and partially visible datasets.