 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
May 01, 2025



Assessing how well a large language model (LLM) understands human, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM's higher-order social cognition. SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations. At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts. Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity. We also build a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena). SAGE thus provides a principled, scalable and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
MINT: Multi-Vector Search Index Tuning
Apr 28, 2025Vector search plays a crucial role in many real-world applications. In addition to single-vector search, multi-vector search becomes important for multi-modal and multi-feature scenarios today. In a multi-vector database, each row is an item, each column represents a feature of items, and each cell is a high-dimensional vector. In multi-vector databases, the choice of indexes can have a significant impact on performance. Although index tuning for relational databases has been extensively studied, index tuning for multi-vector search remains unclear and challenging. In this paper, we define multi-vector search index tuning and propose a framework to solve it. Specifically, given a multi-vector search workload, we develop algorithms to find indexes that minimize latency and meet storage and recall constraints. Compared to the baseline, our latency achieves 2.1X to 8.3X speedup.
GenCLS++: Pushing the Boundaries of Generative Classification in LLMs Through Comprehensive SFT and RL Studies Across Diverse Datasets
Apr 28, 2025As a fundamental task in machine learning, text classification plays a crucial role in many areas. With the rapid scaling of Large Language Models (LLMs), particularly through reinforcement learning (RL), there is a growing need for more capable discriminators. Consequently, advances in classification are becoming increasingly vital for enhancing the overall capabilities of LLMs. Traditional discriminative methods map text to labels but overlook LLMs' intrinsic generative strengths. Generative classification addresses this by prompting the model to directly output labels. However, existing studies still rely on simple SFT alone, seldom probing the interplay between training and inference prompts, and no work has systematically leveraged RL for generative text classifiers and unified SFT, RL, and inference-time prompting in one framework. We bridge this gap with GenCLS++, a framework that jointly optimizes SFT and RL while systematically exploring five high-level strategy dimensions-in-context learning variants, category definitions, explicit uncertainty labels, semantically irrelevant numeric labels, and perplexity-based decoding-during both training and inference. After an SFT "policy warm-up," we apply RL with a simple rule-based reward, yielding sizable extra gains. Across seven datasets, GenCLS++ achieves an average accuracy improvement of 3.46% relative to the naive SFT baseline; on public datasets, this improvement rises to 4.00%. Notably, unlike reasoning-intensive tasks that benefit from explicit thinking processes, we find that classification tasks perform better without such reasoning steps. These insights into the role of explicit reasoning provide valuable guidance for future LLM applications.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025

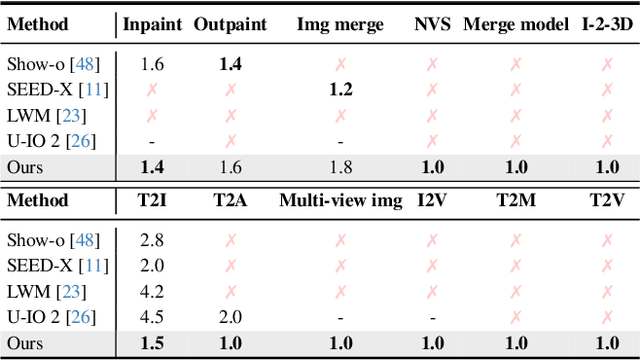

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
Apr 15, 2025



The capacity for complex mathematical reasoning is a key benchmark for artificial intelligence. While reinforcement learning (RL) applied to LLMs shows promise, progress is significantly hindered by the lack of large-scale training data that is sufficiently challenging, possesses verifiable answer formats suitable for RL, and is free from contamination with evaluation benchmarks. To address these limitations, we introduce DeepMath-103K, a new, large-scale dataset comprising approximately 103K mathematical problems, specifically designed to train advanced reasoning models via RL. DeepMath-103K is curated through a rigorous pipeline involving source analysis, stringent decontamination against numerous benchmarks, and filtering for high difficulty (primarily Levels 5-9), significantly exceeding existing open resources in challenge. Each problem includes a verifiable final answer, enabling rule-based RL, and three distinct R1-generated solutions suitable for diverse training paradigms like supervised fine-tuning or distillation. Spanning a wide range of mathematical topics, DeepMath-103K promotes the development of generalizable reasoning. We demonstrate that models trained on DeepMath-103K achieve significant improvements on challenging mathematical benchmarks, validating its effectiveness. We release DeepMath-103K publicly to facilitate community progress in building more capable AI reasoning systems: https://github.com/zwhe99/DeepMath.
Redefining Machine Translation on Social Network Services with Large Language Models
Apr 10, 2025The globalization of social interactions has heightened the need for machine translation (MT) on Social Network Services (SNS), yet traditional models struggle with culturally nuanced content like memes, slang, and pop culture references. While large language models (LLMs) have advanced general-purpose translation, their performance on SNS-specific content remains limited due to insufficient specialized training data and evaluation benchmarks. This paper introduces RedTrans, a 72B LLM tailored for SNS translation, trained on a novel dataset developed through three innovations: (1) Supervised Finetuning with Dual-LLM Back-Translation Sampling, an unsupervised sampling method using LLM-based back-translation to select diverse data for large-scale finetuning; (2) Rewritten Preference Optimization (RePO), an algorithm that identifies and corrects erroneous preference pairs through expert annotation, building reliable preference corpora; and (3) RedTrans-Bench, the first benchmark for SNS translation, evaluating phenomena like humor localization, emoji semantics, and meme adaptation. Experiments show RedTrans outperforms state-of-the-art LLMs. Besides, RedTrans has already been deployed in a real-world production environment, demonstrating that domain-specific adaptation, effectively bridges the gap between generic and culturally grounded translation systems.
WaveHiTS: Wavelet-Enhanced Hierarchical Time Series Modeling for Wind Direction Nowcasting in Eastern Inner Mongolia
Apr 09, 2025



Wind direction forecasting plays a crucial role in optimizing wind energy production, but faces significant challenges due to the circular nature of directional data, error accumulation in multi-step forecasting, and complex meteorological interactions. This paper presents a novel model, WaveHiTS, which integrates wavelet transform with Neural Hierarchical Interpolation for Time Series to address these challenges. Our approach decomposes wind direction into U-V components, applies wavelet transform to capture multi-scale frequency patterns, and utilizes a hierarchical structure to model temporal dependencies at multiple scales, effectively mitigating error propagation. Experiments conducted on real-world meteorological data from Inner Mongolia, China demonstrate that WaveHiTS significantly outperforms deep learning models (RNN, LSTM, GRU), transformer-based approaches (TFT, Informer, iTransformer), and hybrid models (EMD-LSTM). The proposed model achieves RMSE values of approximately 19.2{\deg}-19.4{\deg} compared to 56{\deg}-64{\deg} for deep learning recurrent models, maintaining consistent accuracy across all forecasting steps up to 60 minutes ahead. Moreover, WaveHiTS demonstrates superior robustness with vector correlation coefficients (VCC) of 0.985-0.987 and hit rates of 88.5%-90.1%, substantially outperforming baseline models. Ablation studies confirm that each component-wavelet transform, hierarchical structure, and U-V decomposition-contributes meaningfully to overall performance. These improvements in wind direction nowcasting have significant implications for enhancing wind turbine yaw control efficiency and grid integration of wind energy.
Domain-Conditioned Scene Graphs for State-Grounded Task Planning
Apr 09, 2025Recent robotic task planning frameworks have integrated large multimodal models (LMMs) such as GPT-4V. To address grounding issues of such models, it has been suggested to split the pipeline into perceptional state grounding and subsequent state-based planning. As we show in this work, the state grounding ability of LMM-based approaches is still limited by weaknesses in granular, structured, domain-specific scene understanding. To address this shortcoming, we develop a more structured state grounding framework that features a domain-conditioned scene graph as its scene representation. We show that such representation is actionable in nature as it is directly mappable to a symbolic state in classical planning languages such as PDDL. We provide an instantiation of our state grounding framework where the domain-conditioned scene graph generation is implemented with a lightweight vision-language approach that classifies domain-specific predicates on top of domain-relevant object detections. Evaluated across three domains, our approach achieves significantly higher state estimation accuracy and task planning success rates compared to the previous LMM-based approaches.
Grounding 3D Object Affordance with Language Instructions, Visual Observations and Interactions
Apr 07, 2025



Grounding 3D object affordance is a task that locates objects in 3D space where they can be manipulated, which links perception and action for embodied intelligence. For example, for an intelligent robot, it is necessary to accurately ground the affordance of an object and grasp it according to human instructions. In this paper, we introduce a novel task that grounds 3D object affordance based on language instructions, visual observations and interactions, which is inspired by cognitive science. We collect an Affordance Grounding dataset with Points, Images and Language instructions (AGPIL) to support the proposed task. In the 3D physical world, due to observation orientation, object rotation, or spatial occlusion, we can only get a partial observation of the object. So this dataset includes affordance estimations of objects from full-view, partial-view, and rotation-view perspectives. To accomplish this task, we propose LMAffordance3D, the first multi-modal, language-guided 3D affordance grounding network, which applies a vision-language model to fuse 2D and 3D spatial features with semantic features. Comprehensive experiments on AGPIL demonstrate the effectiveness and superiority of our method on this task, even in unseen experimental settings. Our project is available at https://sites.google.com/view/lmaffordance3d.