 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Deconfounding Against Spatio-Temporal Shifts: Theory and Modeling
Nov 21, 2023



As an important application of spatio-temporal (ST) data, ST traffic forecasting plays a crucial role in improving urban travel efficiency and promoting sustainable development. In practice, the dynamics of traffic data frequently undergo distributional shifts attributed to external factors such as time evolution and spatial differences. This entails forecasting models to handle the out-of-distribution (OOD) issue where test data is distributed differently from training data. In this work, we first formalize the problem by constructing a causal graph of past traffic data, future traffic data, and external ST contexts. We reveal that the failure of prior arts in OOD traffic data is due to ST contexts acting as a confounder, i.e., the common cause for past data and future ones. Then, we propose a theoretical solution named Disentangled Contextual Adjustment (DCA) from a causal lens. It differentiates invariant causal correlations against variant spurious ones and deconfounds the effect of ST contexts. On top of that, we devise a Spatio-Temporal sElf-superVised dEconfounding (STEVE) framework. It first encodes traffic data into two disentangled representations for associating invariant and variant ST contexts. Then, we use representative ST contexts from three conceptually different perspectives (i.e., temporal, spatial, and semantic) as self-supervised signals to inject context information into both representations. In this way, we improve the generalization ability of the learned context-oriented representations to OOD ST traffic forecasting. Comprehensive experiments on four large-scale benchmark datasets demonstrate that our STEVE consistently outperforms the state-of-the-art baselines across various ST OOD scenarios.
Rethinking the Evaluation Protocol of Domain Generalization
May 24, 2023



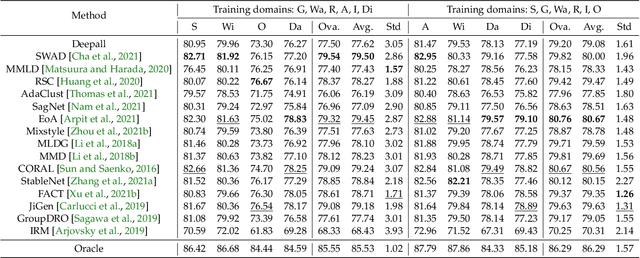
Domain generalization aims to solve the challenge of Out-of-Distribution (OOD) generalization by leveraging common knowledge learned from multiple training domains to generalize to unseen test domains. To accurately evaluate the OOD generalization ability, it is necessary to ensure that test data information is unavailable. However, the current domain generalization protocol may still have potential test data information leakage. This paper examines the potential risks of test data information leakage in two aspects of the current protocol: pretraining on ImageNet and oracle model selection. We propose that training from scratch and using multiple test domains would result in a more precise evaluation of OOD generalization ability. We also rerun the algorithms with the modified protocol and introduce a new leaderboard to encourage future research in domain generalization with a fairer comparison.
Exploring and Exploiting Data Heterogeneity in Recommendation
May 21, 2023



Massive amounts of data are the foundation of data-driven recommendation models. As an inherent nature of big data, data heterogeneity widely exists in real-world recommendation systems. It reflects the differences in the properties among sub-populations. Ignoring the heterogeneity in recommendation data could limit the performance of recommendation models, hurt the sub-populational robustness, and make the models misled by biases. However, data heterogeneity has not attracted substantial attention in the recommendation community. Therefore, it inspires us to adequately explore and exploit heterogeneity for solving the above problems and assisting data analysis. In this work, we focus on exploring two representative categories of heterogeneity in recommendation data that is the heterogeneity of prediction mechanism and covariate distribution and propose an algorithm that explores the heterogeneity through a bilevel clustering method. Furthermore, the uncovered heterogeneity is exploited for two purposes in recommendation scenarios which are prediction with multiple sub-models and supporting debias. Extensive experiments on real-world data validate the existence of heterogeneity in recommendation data and the effectiveness of exploring and exploiting data heterogeneity in recommendation.
Stable Learning via Sparse Variable Independence
Dec 02, 2022The problem of covariate-shift generalization has attracted intensive research attention. Previous stable learning algorithms employ sample reweighting schemes to decorrelate the covariates when there is no explicit domain information about training data. However, with finite samples, it is difficult to achieve the desirable weights that ensure perfect independence to get rid of the unstable variables. Besides, decorrelating within stable variables may bring about high variance of learned models because of the over-reduced effective sample size. A tremendous sample size is required for these algorithms to work. In this paper, with theoretical justification, we propose SVI (Sparse Variable Independence) for the covariate-shift generalization problem. We introduce sparsity constraint to compensate for the imperfectness of sample reweighting under the finite-sample setting in previous methods. Furthermore, we organically combine independence-based sample reweighting and sparsity-based variable selection in an iterative way to avoid decorrelating within stable variables, increasing the effective sample size to alleviate variance inflation. Experiments on both synthetic and real-world datasets demonstrate the improvement of covariate-shift generalization performance brought by SVI.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
Repainting and Imitating Learning for Lane Detection
Oct 11, 2022

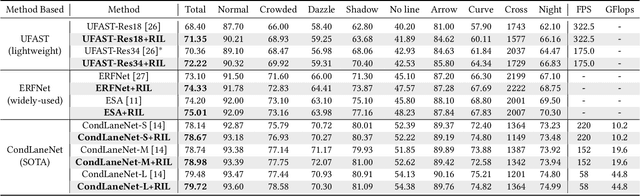
Current lane detection methods are struggling with the invisibility lane issue caused by heavy shadows, severe road mark degradation, and serious vehicle occlusion. As a result, discriminative lane features can be barely learned by the network despite elaborate designs due to the inherent invisibility of lanes in the wild. In this paper, we target at finding an enhanced feature space where the lane features are distinctive while maintaining a similar distribution of lanes in the wild. To achieve this, we propose a novel Repainting and Imitating Learning (RIL) framework containing a pair of teacher and student without any extra data or extra laborious labeling. Specifically, in the repainting step, an enhanced ideal virtual lane dataset is built in which only the lane regions are repainted while non-lane regions are kept unchanged, maintaining the similar distribution of lanes in the wild. The teacher model learns enhanced discriminative representation based on the virtual data and serves as the guidance for a student model to imitate. In the imitating learning step, through the scale-fusing distillation module, the student network is encouraged to generate features that mimic the teacher model both on the same scale and cross scales. Furthermore, the coupled adversarial module builds the bridge to connect not only teacher and student models but also virtual and real data, adjusting the imitating learning process dynamically. Note that our method introduces no extra time cost during inference and can be plug-and-play in various cutting-edge lane detection networks. Experimental results prove the effectiveness of the RIL framework both on CULane and TuSimple for four modern lane detection methods. The code and model will be available soon.
SoccerNet 2022 Challenges Results
Oct 05, 2022
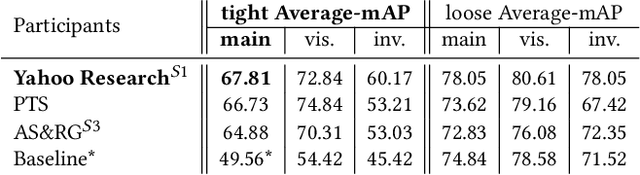
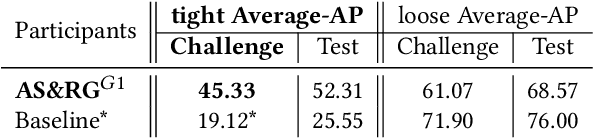
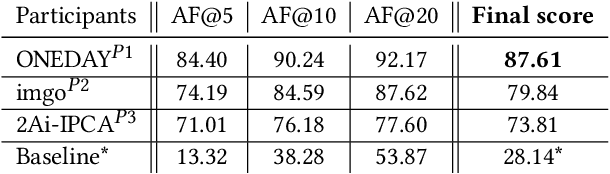
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
StylizedNeRF: Consistent 3D Scene Stylization as Stylized NeRF via 2D-3D Mutual Learning
May 25, 2022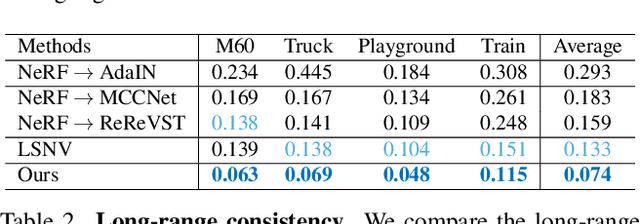

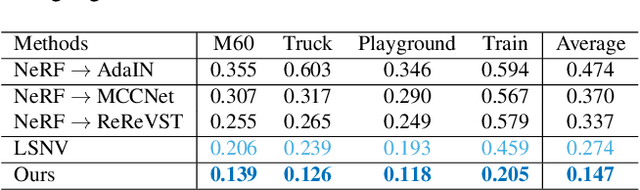
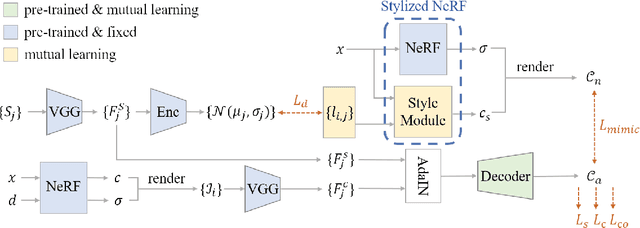
3D scene stylization aims at generating stylized images of the scene from arbitrary novel views following a given set of style examples, while ensuring consistency when rendered from different views. Directly applying methods for image or video stylization to 3D scenes cannot achieve such consistency. Thanks to recently proposed neural radiance fields (NeRF), we are able to represent a 3D scene in a consistent way. Consistent 3D scene stylization can be effectively achieved by stylizing the corresponding NeRF. However, there is a significant domain gap between style examples which are 2D images and NeRF which is an implicit volumetric representation. To address this problem, we propose a novel mutual learning framework for 3D scene stylization that combines a 2D image stylization network and NeRF to fuse the stylization ability of 2D stylization network with the 3D consistency of NeRF. We first pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF. It is followed by distilling the prior knowledge of spatial consistency from NeRF to the 2D stylization network through an introduced consistency loss. We also introduce a mimic loss to supervise the mutual learning of the NeRF style module and fine-tune the 2D stylization decoder. In order to further make our model handle ambiguities of 2D stylization results, we introduce learnable latent codes that obey the probability distributions conditioned on the style. They are attached to training samples as conditional inputs to better learn the style module in our novel stylized NeRF. Experimental results demonstrate that our method is superior to existing approaches in both visual quality and long-range consistency.
NICO++: Towards Better Benchmarking for Domain Generalization
Apr 21, 2022

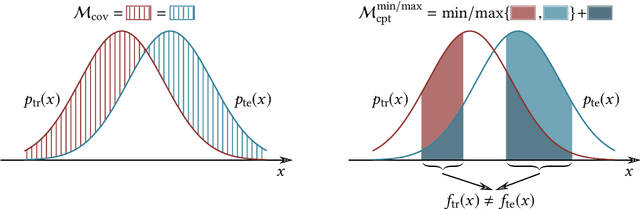
Despite the remarkable performance that modern deep neural networks have achieved on independent and identically distributed (I.I.D.) data, they can crash under distribution shifts. Most current evaluation methods for domain generalization (DG) adopt the leave-one-out strategy as a compromise on the limited number of domains. We propose a large-scale benchmark with extensive labeled domains named NICO++ along with more rational evaluation methods for comprehensively evaluating DG algorithms. To evaluate DG datasets, we propose two metrics to quantify covariate shift and concept shift, respectively. Two novel generalization bounds from the perspective of data construction are proposed to prove that limited concept shift and significant covariate shift favor the evaluation capability for generalization. Through extensive experiments, NICO++ shows its superior evaluation capability compared with current DG datasets and its contribution in alleviating unfairness caused by the leak of oracle knowledge in model selection.
CausPref: Causal Preference Learning for Out-of-Distribution Recommendation
Feb 09, 2022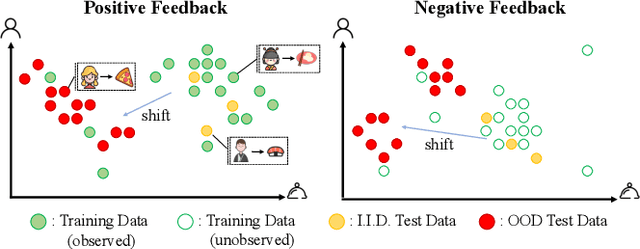
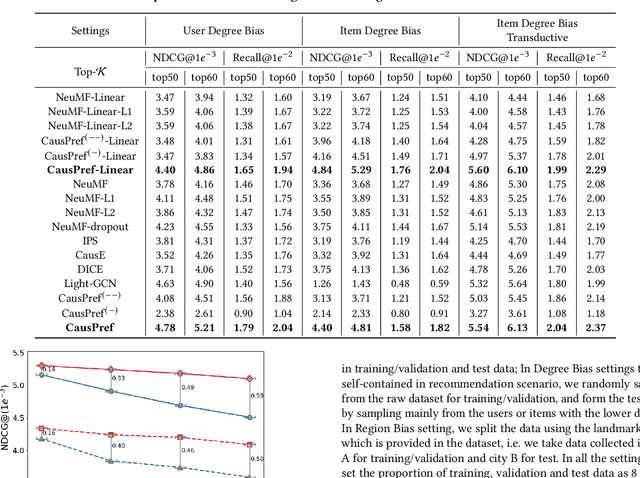
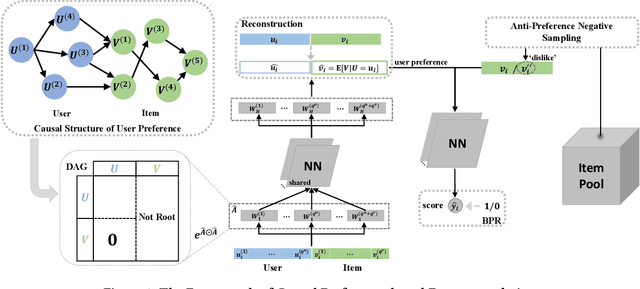
In spite of the tremendous development of recommender system owing to the progressive capability of machine learning recently, the current recommender system is still vulnerable to the distribution shift of users and items in realistic scenarios, leading to the sharp decline of performance in testing environments. It is even more severe in many common applications where only the implicit feedback from sparse data is available. Hence, it is crucial to promote the performance stability of recommendation method in different environments. In this work, we first make a thorough analysis of implicit recommendation problem from the viewpoint of out-of-distribution (OOD) generalization. Then under the guidance of our theoretical analysis, we propose to incorporate the recommendation-specific DAG learner into a novel causal preference-based recommendation framework named CausPref, mainly consisting of causal learning of invariant user preference and anti-preference negative sampling to deal with implicit feedback. Extensive experimental results from real-world datasets clearly demonstrate that our approach surpasses the benchmark models significantly under types of out-of-distribution settings, and show its impressive interpretability.