 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser Localization via Active Sensing with Electromagnetically Reconfigurable Antennas
Jan 29, 2026This paper presents an end-to-end deep learning framework for electromagnetically reconfigurable antenna (ERA)-aided user localization with active sensing, where ERAs provide additional electromagnetic reconfigurability to diversify the received measurements and enhance localization informativeness. To balance sensing flexibility and overhead, we adopt a two-timescale design: the digital combiner is updated at each stage, while the ERA patterns are reconfigured at each substage via a spherical-harmonic representation. The proposed mechanism integrates attention-based feature extraction and LSTM-based temporal learning, enabling the system to learn an optimized sensing strategy and progressively refine the UE position estimate from sequential observations. Simulation results show that the proposed approach consistently outperforms conventional digital beamforming-only and single-stage sensing baselines in terms of localization accuracy. These results highlight the effectiveness of ERA-enabled active sensing for user localization in future wireless systems.
Language Family Matters: Evaluating LLM-Based ASR Across Linguistic Boundaries
Jan 26, 2026Large Language Model (LLM)-powered Automatic Speech Recognition (ASR) systems achieve strong performance with limited resources by linking a frozen speech encoder to a pretrained LLM via a lightweight connector. Prior work trains a separate connector per language, overlooking linguistic relatedness. We propose an efficient and novel connector-sharing strategy based on linguistic family membership, enabling one connector per family, and empirically validate its effectiveness across two multilingual LLMs and two real-world corpora spanning curated and crowd-sourced speech. Our results show that family-based connectors reduce parameter count while improving generalization across domains, offering a practical and scalable strategy for multilingual ASR deployment.
Memorization Dynamics in Knowledge Distillation for Language Models
Jan 21, 2026Knowledge Distillation (KD) is increasingly adopted to transfer capabilities from large language models to smaller ones, offering significant improvements in efficiency and utility while often surpassing standard fine-tuning. Beyond performance, KD is also explored as a privacy-preserving mechanism to mitigate the risk of training data leakage. While training data memorization has been extensively studied in standard pre-training and fine-tuning settings, its dynamics in a knowledge distillation setup remain poorly understood. In this work, we study memorization across the KD pipeline using three large language model (LLM) families (Pythia, OLMo-2, Qwen-3) and three datasets (FineWeb, Wikitext, Nemotron-CC-v2). We find: (1) distilled models memorize significantly less training data than standard fine-tuning (reducing memorization by more than 50%); (2) some examples are inherently easier to memorize and account for a large fraction of memorization during distillation (over ~95%); (3) student memorization is predictable prior to distillation using features based on zlib entropy, KL divergence, and perplexity; and (4) while soft and hard distillation have similar overall memorization rates, hard distillation poses a greater risk: it inherits $2.7\times$ more teacher-specific examples than soft distillation. Overall, we demonstrate that distillation can provide both improved generalization and reduced memorization risks compared to standard fine-tuning.
Training-Free and Interpretable Hateful Video Detection via Multi-stage Adversarial Reasoning
Jan 21, 2026Hateful videos pose serious risks by amplifying discrimination, inciting violence, and undermining online safety. Existing training-based hateful video detection methods are constrained by limited training data and lack of interpretability, while directly prompting large vision-language models often struggle to deliver reliable hate detection. To address these challenges, this paper introduces MARS, a training-free Multi-stage Adversarial ReaSoning framework that enables reliable and interpretable hateful content detection. MARS begins with the objective description of video content, establishing a neutral foundation for subsequent analysis. Building on this, it develops evidence-based reasoning that supports potential hateful interpretations, while in parallel incorporating counter-evidence reasoning to capture plausible non-hateful perspectives. Finally, these perspectives are synthesized into a conclusive and explainable decision. Extensive evaluation on two real-world datasets shows that MARS achieves up to 10% improvement under certain backbones and settings compared to other training-free approaches and outperforms state-of-the-art training-based methods on one dataset. In addition, MARS produces human-understandable justifications, thereby supporting compliance oversight and enhancing the transparency of content moderation workflows. The code is available at https://github.com/Multimodal-Intelligence-Lab-MIL/MARS.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
6D Movable Antenna Enhanced Cell-free MIMO: Two-timescale Decentralized Beamforming and Antenna Movement Optimization
Jan 08, 2026This paper investigates a six-dimensional movable antenna (6DMA)-aided cell-free multi-user multiple-input multiple-output (MIMO) communication system. In this system, each distributed access point (AP) can flexibly adjust its array orientation and antenna positions to adapt to spatial channel variations and enhance communication performance. However, frequent antenna movements and centralized beamforming based on global instantaneous channel state information (CSI) sharing among APs entail extremely high signal processing delay and system overhead, which is difficult to be practically implemented in high-mobility scenarios with short channel coherence time. To address these practical implementation challenges and improve scalability, a two-timescale decentralized optimization framework is proposed in this paper to jointly design the beamformer, antenna positions, and array orientations. In the short timescale, each AP updates its receive beamformer based on local instantaneous CSI and global statistical CSI. In the long timescale, the central processing unit optimizes the antenna positions and array orientations at all APs based on global statistical CSI to maximize the ergodic sum rate of all users. The resulting optimization problem is non-convex and involves highly coupled variables, thus posing significant challenges for obtaining efficient solutions. To address this problem, a constrained stochastic successive convex approximation algorithm is developed. Numerical results demonstrate that the proposed 6DMA-aided cell-free system with decentralized beamforming significantly outperforms other antenna movement schemes with less flexibility and even achieves a performance comparable to that of the centralized beamforming benchmark.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Decentralized Cooperative Beamforming for Networked LEO Satellites with Statistical CSI
Dec 21, 2025Inter-satellite-link-enabled low-Earth-orbit (LEO) satellite constellations are evolving toward networked architectures that support constellation-level cooperation, enabling multiple satellites to jointly serve user terminals through cooperative beamforming. While such cooperation can substantially enhance link budgets and achievable rates, its practical realization is challenged by the scalability limitations of centralized beamforming designs and the stringent computational and signaling constraints of large LEO constellations. This paper develops a fully decentralized cooperative beamforming framework for networked LEO satellite downlinks. Using an ergodic-rate-based formulation, we first derive a centralized weighted minimum mean squared error (WMMSE) solution as a performance benchmark. Building on this formulation, we propose a topology-agnostic decentralized beamforming algorithm by localizing the benchmark and exchanging a set of globally coupled variables whose dimensions are independent of the antenna number and enforcing consensus over arbitrary connected inter-satellite networks. The resulting algorithm admits fully parallel execution across satellites. To further enhance scalability, we eliminate the consensus-related auxiliary variables in closed form and derive a low-complexity per-satellite update rule that is optimal to local iteration and admits a quasi-closed-form solution via scalar line search. Simulation results show that the proposed decentralized schemes closely approach centralized performance under practical inter-satellite topologies, while significantly reducing computational complexity and signaling overhead, enabling scalable cooperative beamforming for large LEO constellations.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025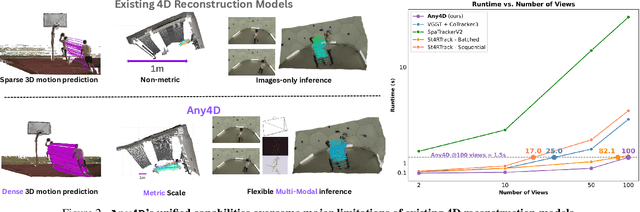
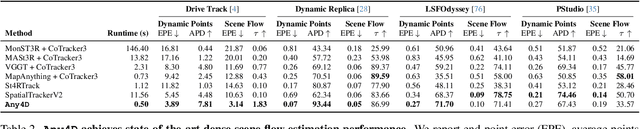
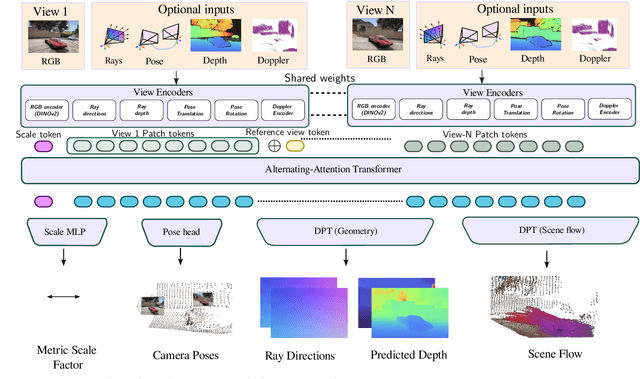
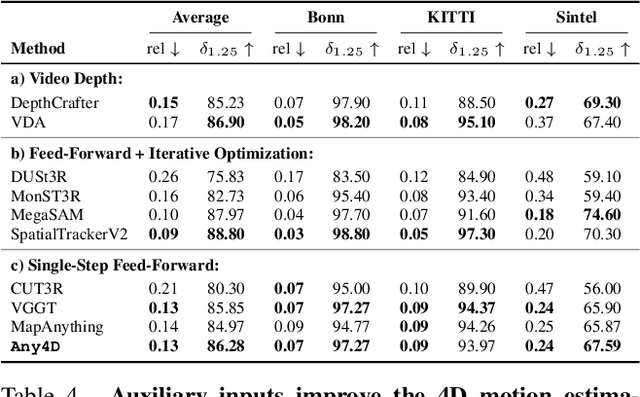
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
MultiHateLoc: Towards Temporal Localisation of Multimodal Hate Content in Online Videos
Dec 11, 2025The rapid growth of video content on platforms such as TikTok and YouTube has intensified the spread of multimodal hate speech, where harmful cues emerge subtly and asynchronously across visual, acoustic, and textual streams. Existing research primarily focuses on video-level classification, leaving the practically crucial task of temporal localisation, identifying when hateful segments occur, largely unaddressed. This challenge is even more noticeable under weak supervision, where only video-level labels are available, and static fusion or classification-based architectures struggle to capture cross-modal and temporal dynamics. To address these challenges, we propose MultiHateLoc, the first framework designed for weakly-supervised multimodal hate localisation. MultiHateLoc incorporates (1) modality-aware temporal encoders to model heterogeneous sequential patterns, including a tailored text-based preprocessing module for feature enhancement; (2) dynamic cross-modal fusion to adaptively emphasise the most informative modality at each moment and a cross-modal contrastive alignment strategy to enhance multimodal feature consistency; (3) a modality-aware MIL objective to identify discriminative segments under video-level supervision. Despite relying solely on coarse labels, MultiHateLoc produces fine-grained, interpretable frame-level predictions. Experiments on HateMM and MultiHateClip show that our method achieves state-of-the-art performance in the localisation task.