 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioVLM: Routing Prompts, Not Parameters, for Cross-Modality Generalization in Biomedical VLMs
Apr 19, 2026Pretrained biomedical vision-language models (VLMs) such as BioMedCLIP perform well on average but often degrade on challenging modalities where inter-class margins are small and acquisition-specific variations are pronounced, especially under few-shot supervision and when modality priors differ from pretraining corpora substantially. We propose BioVLM, a prompt-learning framework that improves cross-domain generalization without extensive backbone fine-tuning. BioVLM learns a diverse prompt bank and introduces dynamic prompt selection: for each input, it selects the most discriminative prompts via a low-entropy criterion on the predictive distribution, effectively coupling sparse few-shot evidence with rich LLM semantic priors. To strengthen this coupling, we distill high-confidence LLM-derived attributes and enforce robust knowledge transfer through strong/weak augmentation consistency. At test time, BioVLM adapts by choosing modality-appropriate prompts, enabling transfer to unseen categories and domains, while keeping training lightweight and inference efficient. On 11 MedMNIST+ 2D datasets, BioVLM achieves new state of the art across three distinct generalization settings. Codes are available at https://github.com/mainaksingha01/BioVLM.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025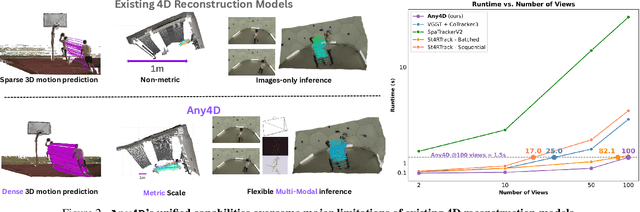
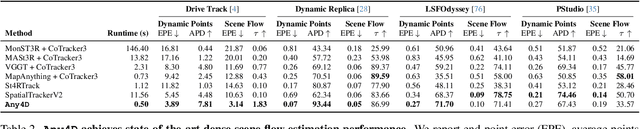
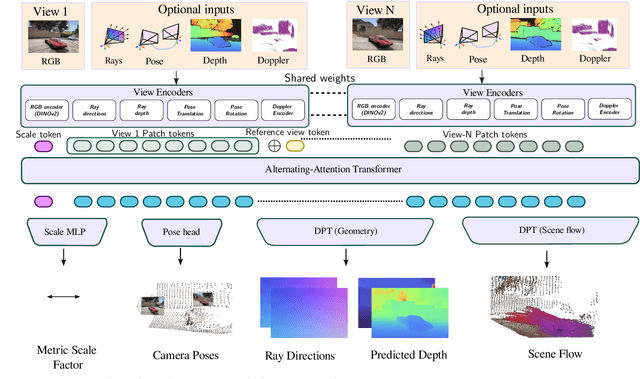
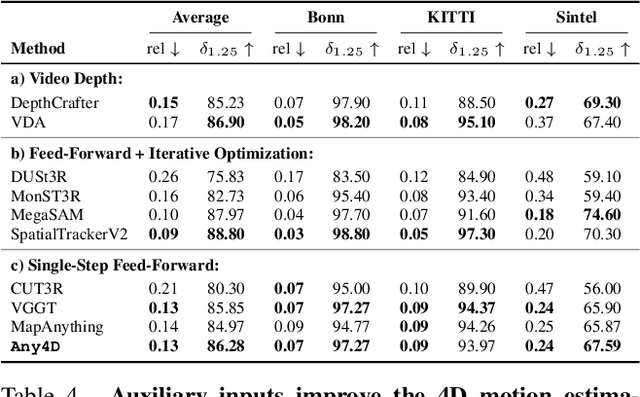
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
CDAD-Net: Bridging Domain Gaps in Generalized Category Discovery
Apr 08, 2024In Generalized Category Discovery (GCD), we cluster unlabeled samples of known and novel classes, leveraging a training dataset of known classes. A salient challenge arises due to domain shifts between these datasets. To address this, we present a novel setting: Across Domain Generalized Category Discovery (AD-GCD) and bring forth CDAD-NET (Class Discoverer Across Domains) as a remedy. CDAD-NET is architected to synchronize potential known class samples across both the labeled (source) and unlabeled (target) datasets, while emphasizing the distinct categorization of the target data. To facilitate this, we propose an entropy-driven adversarial learning strategy that accounts for the distance distributions of target samples relative to source-domain class prototypes. Parallelly, the discriminative nature of the shared space is upheld through a fusion of three metric learning objectives. In the source domain, our focus is on refining the proximity between samples and their affiliated class prototypes, while in the target domain, we integrate a neighborhood-centric contrastive learning mechanism, enriched with an adept neighborsmining approach. To further accentuate the nuanced feature interrelation among semantically aligned images, we champion the concept of conditional image inpainting, underscoring the premise that semantically analogous images prove more efficacious to the task than their disjointed counterparts. Experimentally, CDAD-NET eclipses existing literature with a performance increment of 8-15% on three AD-GCD benchmarks we present.