 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysAgent: Automating Physics-Based 4D Synthesis via Trajectory-Grounded Multi-Agent Feedback
Jun 07, 2026Achieving fully automated, physically plausible 3D motion synthesis is a core objective in graphics and generative AI. However, configuring complex environmental force fields still relies entirely on manual expert intervention, creating a severe bottleneck for large-scale simulation data generation. Existing automated methods primarily focus on material optimization and exhibit severe modality gaps and technical flaws when applied to the vastly more complex force field optimization space: naive Large Language Models (LLMs) lack underlying simulation feedback, causing severe physical inaccuracies, while traditional Score Distillation Sampling (SDS) suffers from sluggish gradients, local optima entrapment, and a mathematical inability to dynamically switch discrete force fields. To address this, we propose PhysAgent, the first simulator-in-the-loop multi-agent framework that leverages multimodal inputs for automated, physically grounded 4D synthesis. By decoupling intrinsic materials from extrinsic dynamics, PhysAgent utilizes a Semantic Agent equipped with an externalized Force Field Skill module to master simulation rules and generate valid initializations. Subsequently, the Refine Agents, driven by Trajectory-Grounded Multi-Agent Feedback, leverage vision foundation models to extract dense point trajectories from rendered frames. By converting these explicit motion trajectories into structured textual descriptors, the agent harnesses LLM commonsense reasoning to execute zero-shot macroscopic leaps, effectively escaping local optima and dynamically switching discrete force fields. Extensive experiments demonstrate that PhysAgent rapidly generates stable, diverse physical scenes from arbitrary multimodal prompts, significantly outperforming existing baselines in both generation diversity and physical accuracy.
HACK++: Towards More Effective Head-Aware Key-Value Compression for Efficient Visual Autoregressive Modeling
Jun 06, 2026Visual Autoregressive (VAR) models adopt a next-scale prediction paradigm, offering high-quality generation with substantially fewer decoding steps. However, existing VAR models suffer from significant attention complexity and severe memory overhead due to the accumulation of key-value (KV) caches across scales. In this paper, we tackle this challenge by introducing KV cache compression into the next-scale paradigm. We begin with an in-depth analysis of VAR attention and observe that attention heads can be stably divided into two functionally distinct categories: Contextual Heads focus on maintaining semantic consistency, while Structural Heads preserve spatial coherence. Their functional divergence makes existing one-size-fits-all compression methods perform poorly on VAR models. We further find that the two head types differ markedly in their reliance on historical scales, and that this reliance shifts across layers and generation steps, arguing for an adaptive cache budget allocation. To address these challenges, we propose HACK++, a training-free Head-Aware key-value Compression frameworK for VAR models. From a one-time offline calibration, HACK++ classifies head types and derives head-specific priors. At inference, it decouples attention from cache compression under independent budgets, bounding the current-scale attention cost while compressing the accumulated cache far more aggressively, via pattern-specific strategies and a reliance-aware budget allocation. Extensive experiments on multiple VAR models across text-to-image, class-conditional, and unified understanding-and-generation tasks validate the effectiveness and generalizability of HACK++. For example, on Infinity-2B/8B, HACK++ maintains near-lossless generation with only a 30% attention budget and a 10% cache budget, and remains robust even under a 1% cache budget.
Rec-Distill: An Industrial Distillation Pipeline for Large-Scale Recommendation Models
May 28, 2026Large recommendation models have demonstrated substantial potential gains under scaling laws, yet these gains are difficult to realize in industrial recommendation systems because real-world deployment requires lightweight models with strict serving efficiency and latency guarantees. This creates a fundamental gap between offline model scaling and online deployment. In this work, we present Rec-Distill, an industrial distillation pipeline that transfers the performance gains of large-scale recommendation modeling to efficient serving models. Rec-Distill combines large-teacher scaling with student-side transfer optimization through decoupled training, black-box distillation, debiasing mechanism, and a hybrid batch-streaming pipeline for dynamic recommendation environments. Across multiple recommendation and advertising scenarios on real-world platforms, our framework scales teacher models up to 24B dense parameters and 20K behavior sequence length, while enabling lightweight students to recover a substantial portion of teacher gains, with distillation transferability exceeding 60% in the best setting. Extensive offline and online experiments further show that these transferred gains consistently translate into measurable business improvements under industrial constraints. These results demonstrate that Rec-Distill provides a practical framework for distilling large-scale recommendation models into deployable, cost-efficient serving systems, while also establishing a reliable path toward scaling recommendation models to even larger regimes in the future.
MDL: A Unified Multi-Distribution Learner in Large-scale Industrial Recommendation through Tokenization
Feb 07, 2026Industrial recommender systems increasingly adopt multi-scenario learning (MSL) and multi-task learning (MTL) to handle diverse user interactions and contexts, but existing approaches suffer from two critical drawbacks: (1) underutilization of large-scale model parameters due to limited interaction with complex feature modules, and (2) difficulty in jointly modeling scenario and task information in a unified framework. To address these challenges, we propose a unified \textbf{M}ulti-\textbf{D}istribution \textbf{L}earning (MDL) framework, inspired by the "prompting" paradigm in large language models (LLMs). MDL treats scenario and task information as specialized tokens rather than auxiliary inputs or gating signals. Specifically, we introduce a unified information tokenization module that transforms features, scenarios, and tasks into a unified tokenized format. To facilitate deep interaction, we design three synergistic mechanisms: (1) feature token self-attention for rich feature interactions, (2) domain-feature attention for scenario/task-adaptive feature activation, and (3) domain-fused aggregation for joint distribution prediction. By stacking these interactions, MDL enables scenario and task information to "prompt" and activate the model's vast parameter space in a bottom-up, layer-wise manner. Extensive experiments on real-world industrial datasets demonstrate that MDL significantly outperforms state-of-the-art MSL and MTL baselines. Online A/B testing on Douyin Search platform over one month yields +0.0626\% improvement in LT30 and -0.3267\% reduction in change query rate. MDL has been fully deployed in production, serving hundreds of millions of users daily.
TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders
Feb 06, 2026In recent years, the study of scaling laws for large recommendation models has gradually gained attention. Works such as Wukong, HiFormer, and DHEN have attempted to increase the complexity of interaction structures in ranking models and validate scaling laws between performance and parameters/FLOPs by stacking multiple layers. However, their experimental scale remains relatively limited. Our previous work introduced the TokenMixer architecture, an efficient variant of the standard Transformer where the self-attention mechanism is replaced by a simple reshape operation, and the feed-forward network is adapted to a pertoken FFN. The effectiveness of this architecture was demonstrated in the ranking stage by the model presented in the RankMixer paper. However, this foundational TokenMixer architecture itself has several design limitations. In this paper, we propose TokenMixer-Large, which systematically addresses these core issues: sub-optimal residual design, insufficient gradient updates in deep models, incomplete MoE sparsification, and limited exploration of scalability. By leveraging a mixing-and-reverting operation, inter-layer residuals, the auxiliary loss and a novel Sparse-Pertoken MoE architecture, TokenMixer-Large successfully scales its parameters to 7-billion and 15-billion on online traffic and offline experiments, respectively. Currently deployed in multiple scenarios at ByteDance, TokenMixer -Large has achieved significant offline and online performance gains.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
A Knowledge Distillation-Based Approach to Enhance Transparency of Classifier Models
Feb 21, 2025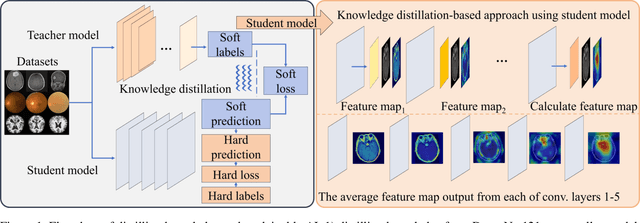
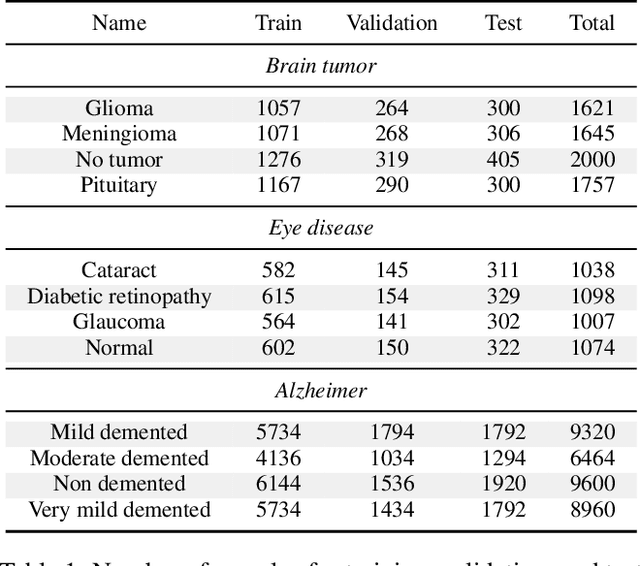
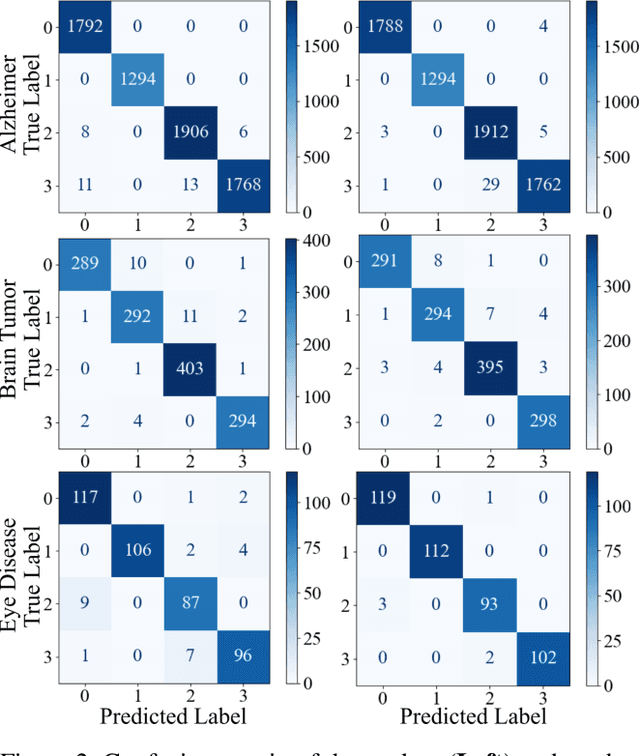
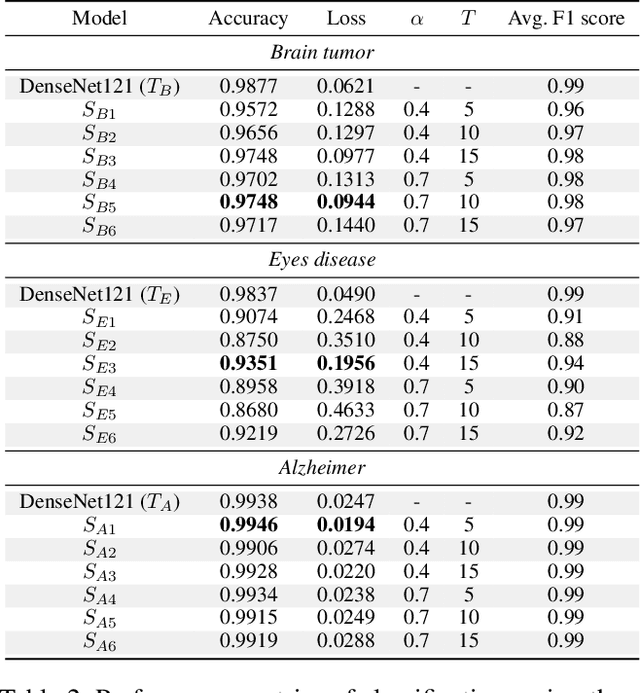
With the rapid development of artificial intelligence (AI), especially in the medical field, the need for its explainability has grown. In medical image analysis, a high degree of transparency and model interpretability can help clinicians better understand and trust the decision-making process of AI models. In this study, we propose a Knowledge Distillation (KD)-based approach that aims to enhance the transparency of the AI model in medical image analysis. The initial step is to use traditional CNN to obtain a teacher model and then use KD to simplify the CNN architecture, retain most of the features of the data set, and reduce the number of network layers. It also uses the feature map of the student model to perform hierarchical analysis to identify key features and decision-making processes. This leads to intuitive visual explanations. We selected three public medical data sets (brain tumor, eye disease, and Alzheimer's disease) to test our method. It shows that even when the number of layers is reduced, our model provides a remarkable result in the test set and reduces the time required for the interpretability analysis.
Siamese Multiple Attention Temporal Convolution Networks for Human Mobility Signature Identification
Aug 17, 2024



The Human Mobility Signature Identification (HuMID) problem stands as a fundamental task within the realm of driving style representation, dedicated to discerning latent driving behaviors and preferences from diverse driver trajectories for driver identification. Its solutions hold significant implications across various domains (e.g., ride-hailing, insurance), wherein their application serves to safeguard users and mitigate potential fraudulent activities. Present HuMID solutions often exhibit limitations in adaptability when confronted with lengthy trajectories, consequently incurring substantial computational overhead. Furthermore, their inability to effectively extract crucial local information further impedes their performance. To address this problem, we propose a Siamese Multiple Attention Temporal Convolutional Network (Siamese MA-TCN) to capitalize on the strengths of both TCN architecture and multi-head self-attention, enabling the proficient extraction of both local and long-term dependencies. Additionally, we devise a novel attention mechanism tailored for the efficient aggregation of multi-scale representations derived from our model. Experimental evaluations conducted on two real-world taxi trajectory datasets reveal that our proposed model effectively extracts both local key information and long-term dependencies. These findings highlight the model's outstanding generalization capabilities, demonstrating its robustness and adaptability across datasets of varying sizes.
FedVAE: Trajectory privacy preserving based on Federated Variational AutoEncoder
Jul 12, 2024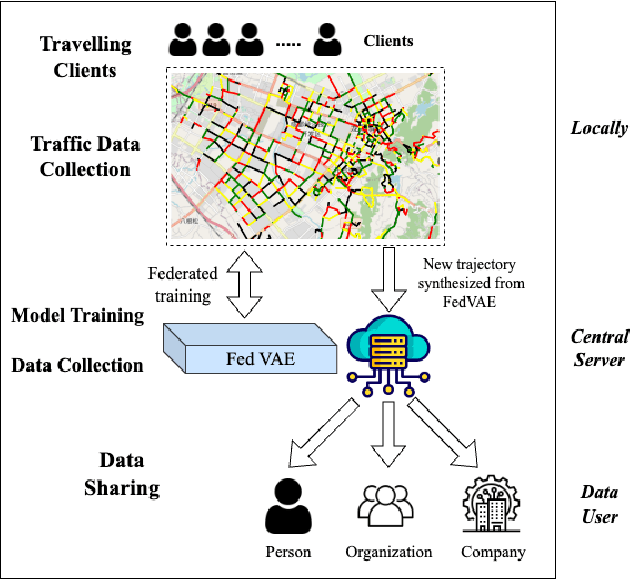
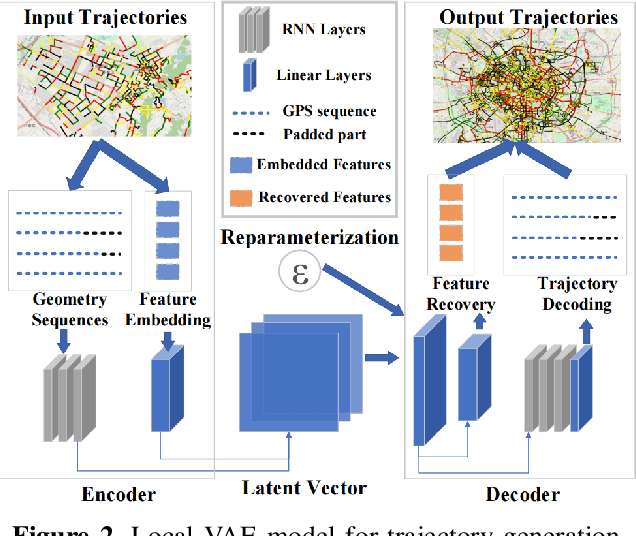
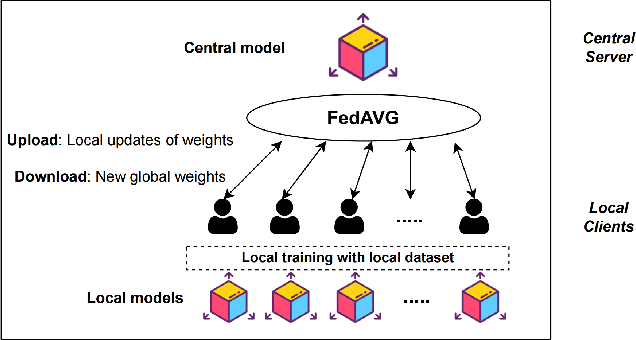
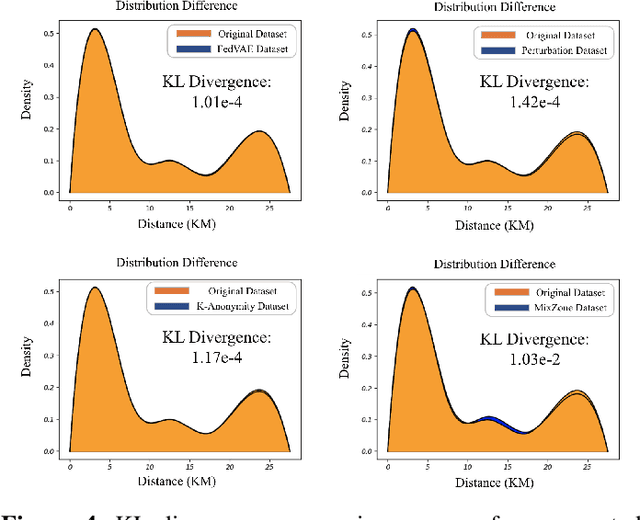
The use of trajectory data with abundant spatial-temporal information is pivotal in Intelligent Transport Systems (ITS) and various traffic system tasks. Location-Based Services (LBS) capitalize on this trajectory data to offer users personalized services tailored to their location information. However, this trajectory data contains sensitive information about users' movement patterns and habits, necessitating confidentiality and protection from unknown collectors. To address this challenge, privacy-preserving methods like K-anonymity and Differential Privacy have been proposed to safeguard private information in the dataset. Despite their effectiveness, these methods can impact the original features by introducing perturbations or generating unrealistic trajectory data, leading to suboptimal performance in downstream tasks. To overcome these limitations, we propose a Federated Variational AutoEncoder (FedVAE) approach, which effectively generates a new trajectory dataset while preserving the confidentiality of private information and retaining the structure of the original features. In addition, FedVAE leverages Variational AutoEncoder (VAE) to maintain the original feature space and generate new trajectory data, and incorporates Federated Learning (FL) during the training stage, ensuring that users' data remains locally stored to protect their personal information. The results demonstrate its superior performance compared to other existing methods, affirming FedVAE as a promising solution for enhancing data privacy and utility in location-based applications.
Robust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023



In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.