 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedVAE: Trajectory privacy preserving based on Federated Variational AutoEncoder
Jul 12, 2024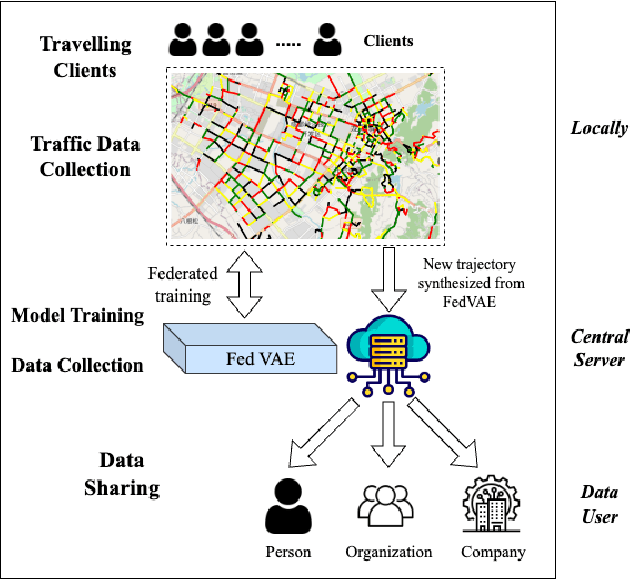
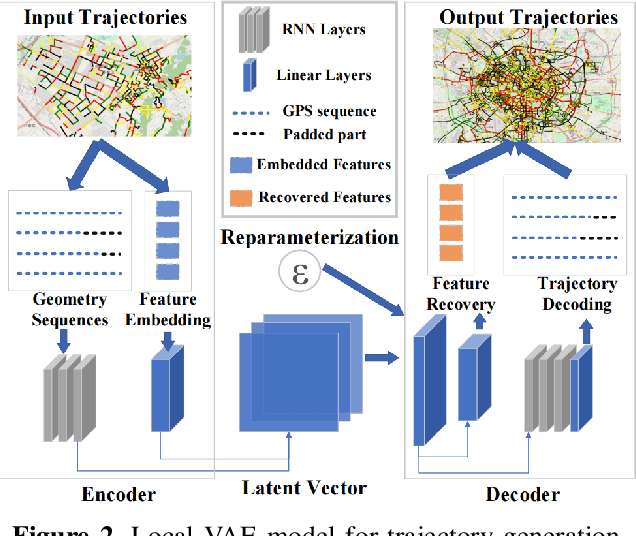
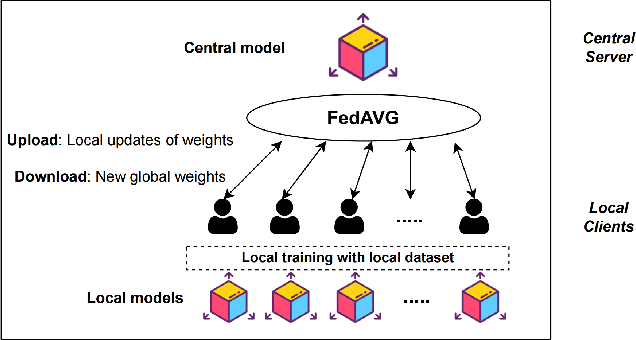
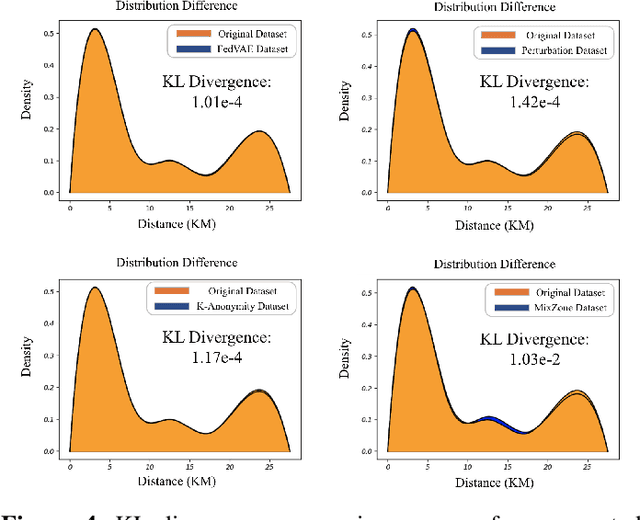
The use of trajectory data with abundant spatial-temporal information is pivotal in Intelligent Transport Systems (ITS) and various traffic system tasks. Location-Based Services (LBS) capitalize on this trajectory data to offer users personalized services tailored to their location information. However, this trajectory data contains sensitive information about users' movement patterns and habits, necessitating confidentiality and protection from unknown collectors. To address this challenge, privacy-preserving methods like K-anonymity and Differential Privacy have been proposed to safeguard private information in the dataset. Despite their effectiveness, these methods can impact the original features by introducing perturbations or generating unrealistic trajectory data, leading to suboptimal performance in downstream tasks. To overcome these limitations, we propose a Federated Variational AutoEncoder (FedVAE) approach, which effectively generates a new trajectory dataset while preserving the confidentiality of private information and retaining the structure of the original features. In addition, FedVAE leverages Variational AutoEncoder (VAE) to maintain the original feature space and generate new trajectory data, and incorporates Federated Learning (FL) during the training stage, ensuring that users' data remains locally stored to protect their personal information. The results demonstrate its superior performance compared to other existing methods, affirming FedVAE as a promising solution for enhancing data privacy and utility in location-based applications.
LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model
Jun 06, 2024



Designing 3D indoor layouts is a crucial task with significant applications in virtual reality, interior design, and automated space planning. Existing methods for 3D layout design either rely on diffusion models, which utilize spatial relationship priors, or heavily leverage the inferential capabilities of proprietary Large Language Models (LLMs), which require extensive prompt engineering and in-context exemplars via black-box trials. These methods often face limitations in generalization and dynamic scene editing. In this paper, we introduce LLplace, a novel 3D indoor scene layout designer based on lightweight fine-tuned open-source LLM Llama3. LLplace circumvents the need for spatial relationship priors and in-context exemplars, enabling efficient and credible room layout generation based solely on user inputs specifying the room type and desired objects. We curated a new dialogue dataset based on the 3D-Front dataset, expanding the original data volume and incorporating dialogue data for adding and removing objects. This dataset can enhance the LLM's spatial understanding. Furthermore, through dialogue, LLplace activates the LLM's capability to understand 3D layouts and perform dynamic scene editing, enabling the addition and removal of objects. Our approach demonstrates that LLplace can effectively generate and edit 3D indoor layouts interactively and outperform existing methods in delivering high-quality 3D design solutions. Code and dataset will be released.
Enhancing Traffic Prediction with Learnable Filter Module
Oct 24, 2023



Modeling future traffic conditions often relies heavily on complex spatial-temporal neural networks to capture spatial and temporal correlations, which can overlook the inherent noise in the data. This noise, often manifesting as unexpected short-term peaks or drops in traffic observation, is typically caused by traffic accidents or inherent sensor vibration. In practice, such noise can be challenging to model due to its stochastic nature and can lead to overfitting risks if a neural network is designed to learn this behavior. To address this issue, we propose a learnable filter module to filter out noise in traffic data adaptively. This module leverages the Fourier transform to convert the data to the frequency domain, where noise is filtered based on its pattern. The denoised data is then recovered to the time domain using the inverse Fourier transform. Our approach focuses on enhancing the quality of the input data for traffic prediction models, which is a critical yet often overlooked aspect in the field. We demonstrate that the proposed module is lightweight, easy to integrate with existing models, and can significantly improve traffic prediction performance. Furthermore, we validate our approach with extensive experimental results on real-world datasets, showing that it effectively mitigates noise and enhances prediction accuracy.
Meta Attentive Graph Convolutional Recurrent Network for Traffic Forecasting
Aug 28, 2023Traffic forecasting is a fundamental problem in intelligent transportation systems. Existing traffic predictors are limited by their expressive power to model the complex spatial-temporal dependencies in traffic data, mainly due to the following limitations. Firstly, most approaches are primarily designed to model the local shared patterns, which makes them insufficient to capture the specific patterns associated with each node globally. Hence, they fail to learn each node's unique properties and diversified patterns. Secondly, most existing approaches struggle to accurately model both short- and long-term dependencies simultaneously. In this paper, we propose a novel traffic predictor, named Meta Attentive Graph Convolutional Recurrent Network (MAGCRN). MAGCRN utilizes a Graph Convolutional Recurrent Network (GCRN) as a core module to model local dependencies and improves its operation with two novel modules: 1) a Node-Specific Meta Pattern Learning (NMPL) module to capture node-specific patterns globally and 2) a Node Attention Weight Generation Module (NAWG) module to capture short- and long-term dependencies by connecting the node-specific features with the ones learned initially at each time step during GCRN operation. Experiments on six real-world traffic datasets demonstrate that NMPL and NAWG together enable MAGCRN to outperform state-of-the-art baselines on both short- and long-term predictions.
Diffusion Model for GPS Trajectory Generation
Apr 23, 2023



With the deployment of GPS-enabled devices and data acquisition technology, the massively generated GPS trajectory data provide a core support for advancing spatial-temporal data mining research. Nonetheless, GPS trajectories comprise personal geo-location information, rendering inevitable privacy concerns on plain data. One promising solution to this problem is trajectory generation, replacing the original data with the generated privacy-free ones. However, owing to the complex and stochastic behavior of human activities, generating high-quality trajectories is still in its infancy. To achieve the objective, we propose a diffusion-based trajectory generation (Diff-Traj) framework, effectively integrating the generation capability of the diffusion model and learning from the spatial-temporal features of trajectories. Specifically, we gradually convert real trajectories to noise through a forward trajectory noising process. Then, Diff-Traj reconstructs forged trajectories from the noise by a reverse trajectory denoising process. In addition, we design a trajectory UNet (Traj-UNet) structure to extract trajectory features for noise level prediction during the reverse process. Experiments on two real-world datasets show that Diff-Traj can be intuitively applied to generate high-quality trajectories while retaining the original distribution.
Adaptive Modeling of Uncertainties for Traffic Forecasting
Mar 16, 2023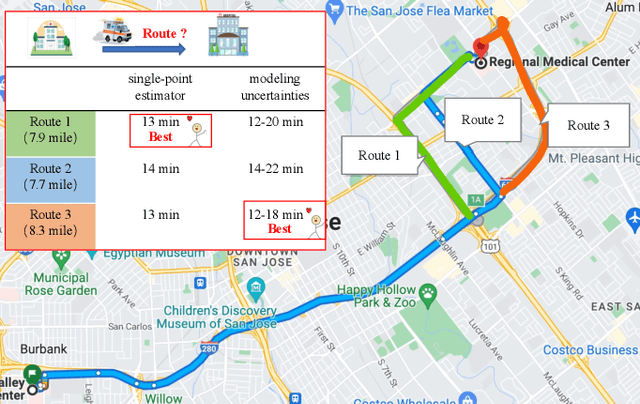


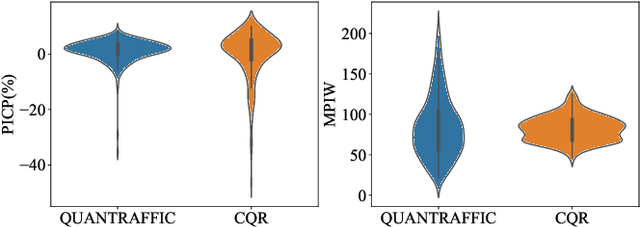
Deep neural networks (DNNs) have emerged as a dominant approach for developing traffic forecasting models. These models are typically trained to minimize error on averaged test cases and produce a single-point prediction, such as a scalar value for traffic speed or travel time. However, single-point predictions fail to account for prediction uncertainty that is critical for many transportation management scenarios, such as determining the best- or worst-case arrival time. We present QuanTraffic, a generic framework to enhance the capability of an arbitrary DNN model for uncertainty modeling. QuanTraffic requires little human involvement and does not change the base DNN architecture during deployment. Instead, it automatically learns a standard quantile function during the DNN model training to produce a prediction interval for the single-point prediction. The prediction interval defines a range where the true value of the traffic prediction is likely to fall. Furthermore, QuanTraffic develops an adaptive scheme that dynamically adjusts the prediction interval based on the location and prediction window of the test input. We evaluated QuanTraffic by applying it to five representative DNN models for traffic forecasting across seven public datasets. We then compared QuanTraffic against five uncertainty quantification methods. Compared to the baseline uncertainty modeling techniques, QuanTraffic with base DNN architectures delivers consistently better and more robust performance than the existing ones on the reported datasets.
Traffic Prediction with Transfer Learning: A Mutual Information-based Approach
Mar 13, 2023



In modern traffic management, one of the most essential yet challenging tasks is accurately and timely predicting traffic. It has been well investigated and examined that deep learning-based Spatio-temporal models have an edge when exploiting Spatio-temporal relationships in traffic data. Typically, data-driven models require vast volumes of data, but gathering data in small cities can be difficult owing to constraints such as equipment deployment and maintenance costs. To resolve this problem, we propose TrafficTL, a cross-city traffic prediction approach that uses big data from other cities to aid data-scarce cities in traffic prediction. Utilizing a periodicity-based transfer paradigm, it identifies data similarity and reduces negative transfer caused by the disparity between two data distributions from distant cities. In addition, the suggested method employs graph reconstruction techniques to rectify defects in data from small data cities. TrafficTL is evaluated by comprehensive case studies on three real-world datasets and outperforms the state-of-the-art baseline by around 8 to 25 percent.
Uncertainty Quantification for Traffic Forecasting: A Unified Approach
Aug 11, 2022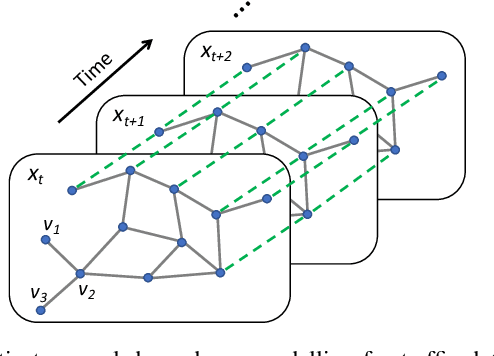
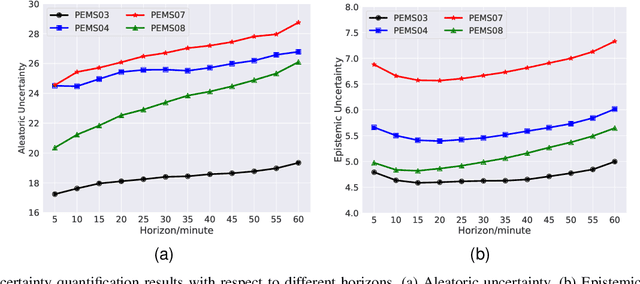
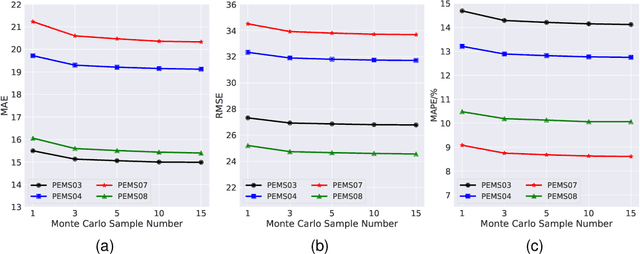
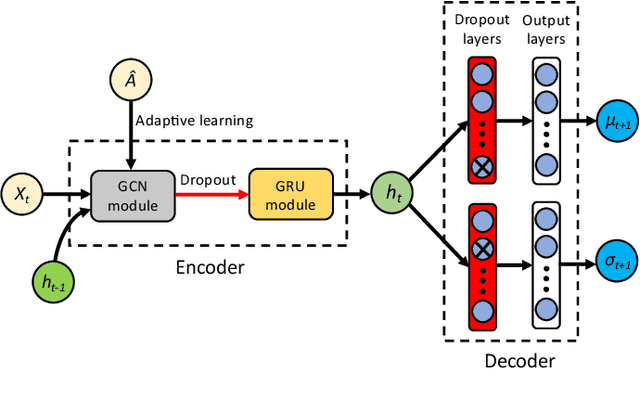
Uncertainty is an essential consideration for time series forecasting tasks. In this work, we specifically focus on quantifying the uncertainty of traffic forecasting. To achieve this, we develop Deep Spatio-Temporal Uncertainty Quantification (DeepSTUQ), which can estimate both aleatoric and epistemic uncertainty. We first leverage a spatio-temporal model to model the complex spatio-temporal correlations of traffic data. Subsequently, two independent sub-neural networks maximizing the heterogeneous log-likelihood are developed to estimate aleatoric uncertainty. For estimating epistemic uncertainty, we combine the merits of variational inference and deep ensembling by integrating the Monte Carlo dropout and the Adaptive Weight Averaging re-training methods, respectively. Finally, we propose a post-processing calibration approach based on Temperature Scaling, which improves the model's generalization ability to estimate uncertainty. Extensive experiments are conducted on four public datasets, and the empirical results suggest that the proposed method outperforms state-of-the-art methods in terms of both point prediction and uncertainty quantification.
Social-DualCVAE: Multimodal Trajectory Forecasting Based on Social Interactions Pattern Aware and Dual Conditional Variational Auto-Encoder
Feb 08, 2022
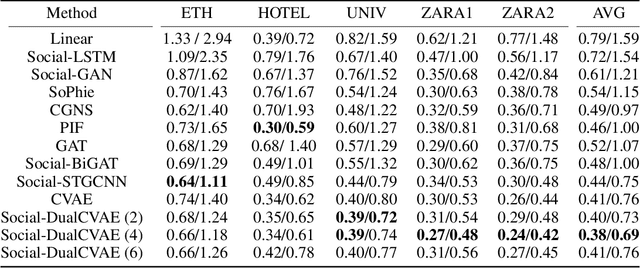
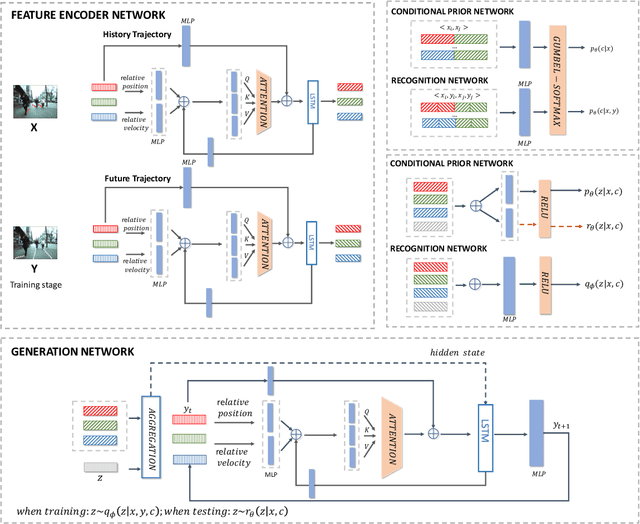
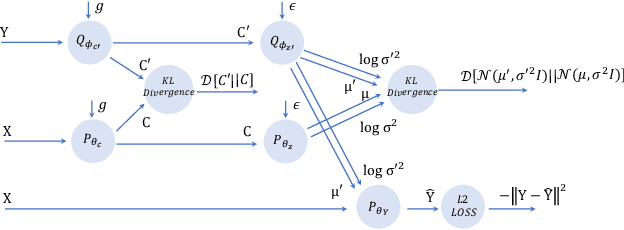
Pedestrian trajectory forecasting is a fundamental task in multiple utility areas, such as self-driving, autonomous robots, and surveillance systems. The future trajectory forecasting is multi-modal, influenced by physical interaction with scene contexts and intricate social interactions among pedestrians. The mainly existing literature learns representations of social interactions by deep learning networks, while the explicit interaction patterns are not utilized. Different interaction patterns, such as following or collision avoiding, will generate different trends of next movement, thus, the awareness of social interaction patterns is important for trajectory forecasting. Moreover, the social interaction patterns are privacy concerned or lack of labels. To jointly address the above issues, we present a social-dual conditional variational auto-encoder (Social-DualCVAE) for multi-modal trajectory forecasting, which is based on a generative model conditioned not only on the past trajectories but also the unsupervised classification of interaction patterns. After generating the category distribution of the unlabeled social interaction patterns, DualCVAE, conditioned on the past trajectories and social interaction pattern, is proposed for multi-modal trajectory prediction by latent variables estimating. A variational bound is derived as the minimization objective during training. The proposed model is evaluated on widely used trajectory benchmarks and outperforms the prior state-of-the-art methods.
Resource-constrained Federated Edge Learning with Heterogeneous Data: Formulation and Analysis
Oct 14, 2021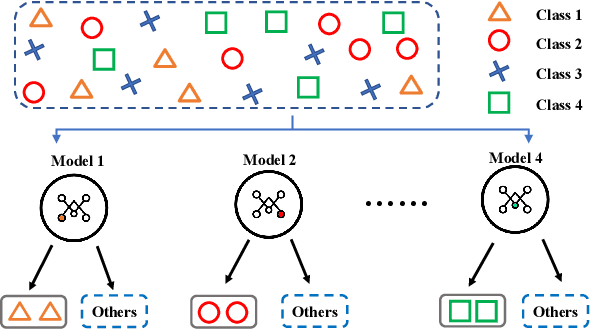

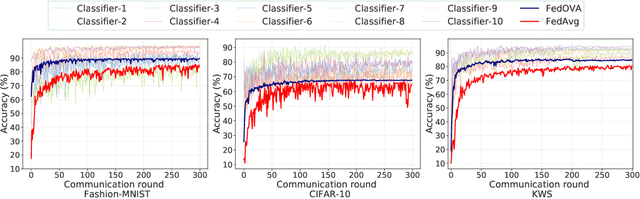
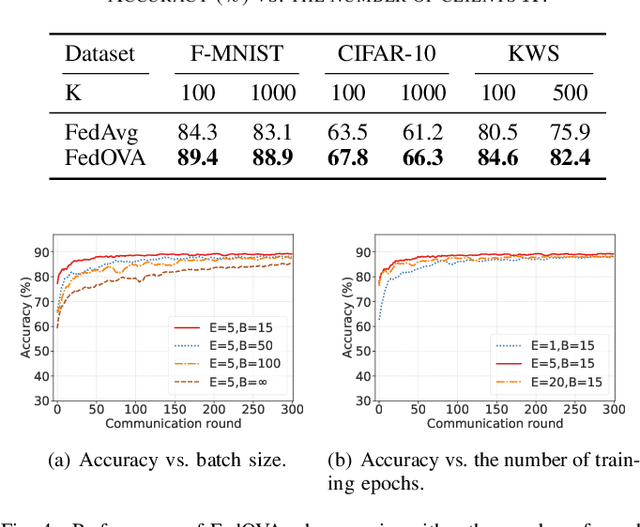
Efficient collaboration between collaborative machine learning and wireless communication technology, forming a Federated Edge Learning (FEEL), has spawned a series of next-generation intelligent applications. However, due to the openness of network connections, the FEEL framework generally involves hundreds of remote devices (or clients), resulting in expensive communication costs, which is not friendly to resource-constrained FEEL. To address this issue, we propose a distributed approximate Newton-type algorithm with fast convergence speed to alleviate the problem of FEEL resource (in terms of communication resources) constraints. Specifically, the proposed algorithm is improved based on distributed L-BFGS algorithm and allows each client to approximate the high-cost Hessian matrix by computing the low-cost Fisher matrix in a distributed manner to find a "better" descent direction, thereby speeding up convergence. Second, we prove that the proposed algorithm has linear convergence in strongly convex and non-convex cases and analyze its computational and communication complexity. Similarly, due to the heterogeneity of the connected remote devices, FEEL faces the challenge of heterogeneous data and non-IID (Independent and Identically Distributed) data. To this end, we design a simple but elegant training scheme, namely FedOVA, to solve the heterogeneous statistical challenge brought by heterogeneous data. In this way, FedOVA first decomposes a multi-class classification problem into more straightforward binary classification problems and then combines their respective outputs using ensemble learning. In particular, the scheme can be well integrated with our communication efficient algorithm to serve FEEL. Numerical results verify the effectiveness and superiority of the proposed algorithm.