 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepR: Depth Guided Single-view Scene Reconstruction with Instance-level Diffusion
Jul 30, 2025We propose DepR, a depth-guided single-view scene reconstruction framework that integrates instance-level diffusion within a compositional paradigm. Instead of reconstructing the entire scene holistically, DepR generates individual objects and subsequently composes them into a coherent 3D layout. Unlike previous methods that use depth solely for object layout estimation during inference and therefore fail to fully exploit its rich geometric information, DepR leverages depth throughout both training and inference. Specifically, we introduce depth-guided conditioning to effectively encode shape priors into diffusion models. During inference, depth further guides DDIM sampling and layout optimization, enhancing alignment between the reconstruction and the input image. Despite being trained on limited synthetic data, DepR achieves state-of-the-art performance and demonstrates strong generalization in single-view scene reconstruction, as shown through evaluations on both synthetic and real-world datasets.
CKD-EHR:Clinical Knowledge Distillation for Electronic Health Records
Jun 18, 2025



Electronic Health Records (EHR)-based disease prediction models have demonstrated significant clinical value in promoting precision medicine and enabling early intervention. However, existing large language models face two major challenges: insufficient representation of medical knowledge and low efficiency in clinical deployment. To address these challenges, this study proposes the CKD-EHR (Clinical Knowledge Distillation for EHR) framework, which achieves efficient and accurate disease risk prediction through knowledge distillation techniques. Specifically, the large language model Qwen2.5-7B is first fine-tuned on medical knowledge-enhanced data to serve as the teacher model.It then generates interpretable soft labels through a multi-granularity attention distillation mechanism. Finally, the distilled knowledge is transferred to a lightweight BERT student model. Experimental results show that on the MIMIC-III dataset, CKD-EHR significantly outperforms the baseline model:diagnostic accuracy is increased by 9%, F1-score is improved by 27%, and a 22.2 times inference speedup is achieved. This innovative solution not only greatly improves resource utilization efficiency but also significantly enhances the accuracy and timeliness of diagnosis, providing a practical technical approach for resource optimization in clinical settings. The code and data for this research are available athttps://github.com/209506702/CKD_EHR.
Limited-Angle CBCT Reconstruction via Geometry-Integrated Cycle-domain Denoising Diffusion Probabilistic Models
Jun 16, 2025



Cone-beam CT (CBCT) is widely used in clinical radiotherapy for image-guided treatment, improving setup accuracy, adaptive planning, and motion management. However, slow gantry rotation limits performance by introducing motion artifacts, blurring, and increased dose. This work aims to develop a clinically feasible method for reconstructing high-quality CBCT volumes from consecutive limited-angle acquisitions, addressing imaging challenges in time- or dose-constrained settings. We propose a limited-angle (LA) geometry-integrated cycle-domain (LA-GICD) framework for CBCT reconstruction, comprising two denoising diffusion probabilistic models (DDPMs) connected via analytic cone-beam forward and back projectors. A Projection-DDPM completes missing projections, followed by back-projection, and an Image-DDPM refines the volume. This dual-domain design leverages complementary priors from projection and image spaces to achieve high-quality reconstructions from limited-angle (<= 90 degrees) scans. Performance was evaluated against full-angle reconstruction. Four board-certified medical physicists conducted assessments. A total of 78 planning CTs in common CBCT geometries were used for training and evaluation. The method achieved a mean absolute error of 35.5 HU, SSIM of 0.84, and PSNR of 29.8 dB, with visibly reduced artifacts and improved soft-tissue clarity. LA-GICD's geometry-aware dual-domain learning, embedded in analytic forward/backward operators, enabled artifact-free, high-contrast reconstructions from a single 90-degree scan, reducing acquisition time and dose four-fold. LA-GICD improves limited-angle CBCT reconstruction with strong data fidelity and anatomical realism. It offers a practical solution for short-arc acquisitions, enhancing CBCT use in radiotherapy by providing clinically applicable images with reduced scan time and dose for more accurate, personalized treatments.
Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
Jun 13, 2025



For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at https://github.com/TUM-AVS/FM-for-Scenario-Generation-Analysis.
NeuralOM: Neural Ocean Model for Subseasonal-to-Seasonal Simulation
May 27, 2025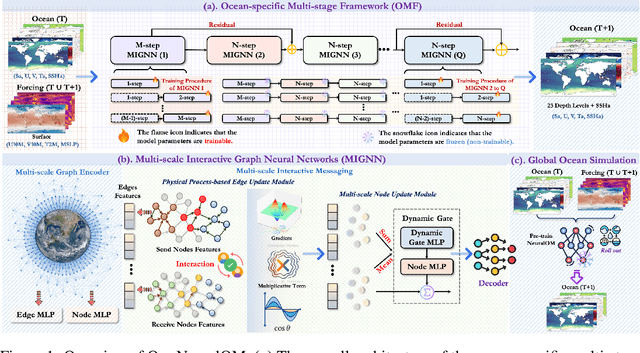
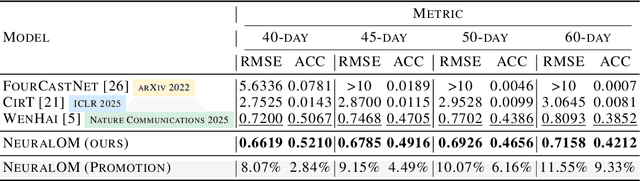
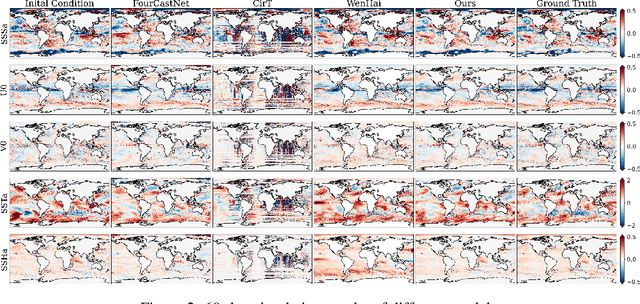
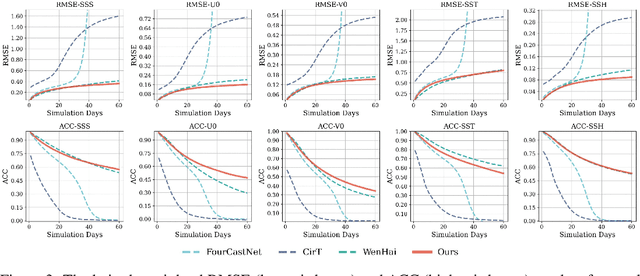
Accurate Subseasonal-to-Seasonal (S2S) ocean simulation is critically important for marine research, yet remains challenging due to its substantial thermal inertia and extended time delay. Machine learning (ML)-based models have demonstrated significant advancements in simulation accuracy and computational efficiency compared to traditional numerical methods. Nevertheless, a significant limitation of current ML models for S2S ocean simulation is their inadequate incorporation of physical consistency and the slow-changing properties of the ocean system. In this work, we propose a neural ocean model (NeuralOM) for S2S ocean simulation with a multi-scale interactive graph neural network to emulate diverse physical phenomena associated with ocean systems effectively. Specifically, we propose a multi-stage framework tailored to model the ocean's slowly changing nature. Additionally, we introduce a multi-scale interactive messaging module to capture complex dynamical behaviors, such as gradient changes and multiplicative coupling relationships inherent in ocean dynamics. Extensive experimental evaluations confirm that our proposed NeuralOM outperforms state-of-the-art models in S2S and extreme event simulation. The codes are available at https://github.com/YuanGao-YG/NeuralOM.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
Turb-L1: Achieving Long-term Turbulence Tracing By Tackling Spectral Bias
May 25, 2025



Accurately predicting the long-term evolution of turbulence is crucial for advancing scientific understanding and optimizing engineering applications. However, existing deep learning methods face significant bottlenecks in long-term autoregressive prediction, which exhibit excessive smoothing and fail to accurately track complex fluid dynamics. Our extensive experimental and spectral analysis of prevailing methods provides an interpretable explanation for this shortcoming, identifying Spectral Bias as the core obstacle. Concretely, spectral bias is the inherent tendency of models to favor low-frequency, smooth features while overlooking critical high-frequency details during training, thus reducing fidelity and causing physical distortions in long-term predictions. Building on this insight, we propose Turb-L1, an innovative turbulence prediction method, which utilizes a Hierarchical Dynamics Synthesis mechanism within a multi-grid architecture to explicitly overcome spectral bias. It accurately captures cross-scale interactions and preserves the fidelity of high-frequency dynamics, enabling reliable long-term tracking of turbulence evolution. Extensive experiments on the 2D turbulence benchmark show that Turb-L1 demonstrates excellent performance: (I) In long-term predictions, it reduces Mean Squared Error (MSE) by $80.3\%$ and increases Structural Similarity (SSIM) by over $9\times$ compared to the SOTA baseline, significantly improving prediction fidelity. (II) It effectively overcomes spectral bias, accurately reproducing the full enstrophy spectrum and maintaining physical realism in high-wavenumber regions, thus avoiding the spectral distortions or spurious energy accumulation seen in other methods.
Bridging Speech Emotion Recognition and Personality: Dataset and Temporal Interaction Condition Network
May 20, 2025This study investigates the interaction between personality traits and emotional expression, exploring how personality information can improve speech emotion recognition (SER). We collected personality annotation for the IEMOCAP dataset, and the statistical analysis identified significant correlations between personality traits and emotional expressions. To extract finegrained personality features, we propose a temporal interaction condition network (TICN), in which personality features are integrated with Hubert-based acoustic features for SER. Experiments show that incorporating ground-truth personality traits significantly enhances valence recognition, improving the concordance correlation coefficient (CCC) from 0.698 to 0.785 compared to the baseline without personality information. For practical applications in dialogue systems where personality information about the user is unavailable, we develop a front-end module of automatic personality recognition. Using these automatically predicted traits as inputs to our proposed TICN model, we achieve a CCC of 0.776 for valence recognition, representing an 11.17% relative improvement over the baseline. These findings confirm the effectiveness of personality-aware SER and provide a solid foundation for further exploration in personality-aware speech processing applications.
Neural Inverse Scattering with Score-based Regularization
May 20, 2025Inverse scattering is a fundamental challenge in many imaging applications, ranging from microscopy to remote sensing. Solving this problem often requires jointly estimating two unknowns -- the image and the scattering field inside the object -- necessitating effective image prior to regularize the inference. In this paper, we propose a regularized neural field (NF) approach which integrates the denoising score function used in score-based generative models. The neural field formulation offers convenient flexibility to performing joint estimation, while the denoising score function imposes the rich structural prior of images. Our results on three high-contrast simulated objects show that the proposed approach yields a better imaging quality compared to the state-of-the-art NF approach, where regularization is based on total variation.
APCoTTA: Continual Test-Time Adaptation for Semantic Segmentation of Airborne LiDAR Point Clouds
May 15, 2025Airborne laser scanning (ALS) point cloud segmentation is a fundamental task for large-scale 3D scene understanding. In real-world applications, models are typically fixed after training. However, domain shifts caused by changes in the environment, sensor types, or sensor degradation often lead to a decline in model performance. Continuous Test-Time Adaptation (CTTA) offers a solution by adapting a source-pretrained model to evolving, unlabeled target domains. Despite its potential, research on ALS point clouds remains limited, facing challenges such as the absence of standardized datasets and the risk of catastrophic forgetting and error accumulation during prolonged adaptation. To tackle these challenges, we propose APCoTTA, the first CTTA method tailored for ALS point cloud semantic segmentation. We propose a dynamic trainable layer selection module. This module utilizes gradient information to select low-confidence layers for training, and the remaining layers are kept frozen, mitigating catastrophic forgetting. To further reduce error accumulation, we propose an entropy-based consistency loss. By losing such samples based on entropy, we apply consistency loss only to the reliable samples, enhancing model stability. In addition, we propose a random parameter interpolation mechanism, which randomly blends parameters from the selected trainable layers with those of the source model. This approach helps balance target adaptation and source knowledge retention, further alleviating forgetting. Finally, we construct two benchmarks, ISPRSC and H3DC, to address the lack of CTTA benchmarks for ALS point cloud segmentation. Experimental results demonstrate that APCoTTA achieves the best performance on two benchmarks, with mIoU improvements of approximately 9% and 14% over direct inference. The new benchmarks and code are available at https://github.com/Gaoyuan2/APCoTTA.