 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Understand How You Feel: Enhancing Deeper Emotional Support Through Multilingual Emotional Validation in Dialogue System
Jun 10, 2026Emotional validation - explicitly acknowledging that a user's feelings make sense - has proven therapeutic value but has received little computational attention. Emotional validation in dialogue systems can be decomposed into (i) validating response identification, (ii) validation timing detection, and (iii) validating response generation. To support research on all three subtasks, we release M-EDESConv, a 120k English-Japanese multilingual corpus created through hybrid manual and automatic annotation, and M-TESC, a multilingual spoken-dialogue test set. For timing detection, we propose MEGUMI, a Multilingual Emotion-aware Gated Unit for Mutual Integration, that fuses frozen XLM-RoBERTa semantics with language-specific emotion encoders via cross-modal attention and gated fusion. MEGUMI shows superior performance on both the M-EDESConv and M-TESC datasets, both objectively and subjectively. Finally, our EmoValidBench benchmarks of GPT-4.1 Nano and Llama-3.1 8B indicate that current LLMs generate contextually similar and diverse validating responses, but emotional understanding remains a major area for improvement. Project page: https://github.com/zihaurpang/Multilingual-Emotional-Validation
LoASR-Bench: Evaluating Large Speech Language Models on Low-Resource Automatic Speech Recognition Across Language Families
Mar 20, 2026Large language models (LLMs) have driven substantial advances in speech language models (SpeechLMs), yielding strong performance in automatic speech recognition (ASR) under high-resource conditions. However, existing benchmarks predominantly focus on high-resource languages, leaving the ASR behavior of SpeechLMs in low-resource languages insufficiently understood. This gap is critical, as practical ASR systems must reliably support low-resource languages and generalize across diverse language families, and it directly hinders the deployment of SpeechLM-based ASR in real-world multilingual scenarios. As a result, it is essential to evaluate SpeechLMs on low-resource languages to ensure their generalizability across different language families. To address this problem, we propose \textbf{LoASR-Bench}, a comprehensive benchmark designed to evaluate \textbf{lo}w-resource \textbf{a}utomatic \textbf{s}peech \textbf{r}ecognition (\textbf{ASR}) of the latest SpeechLMs across diverse language families. LoASR-Bench comprises 25 languages from 9 language families, featuring both Latin and non-Latin scripts, enabling cross-linguistic and cross-script assessment of ASR performance of current SpeechLMs. Experimental results highlight the limitations of the latest SpeechLMs in handling real-world low-resource languages.
Multilingual and Continuous Backchannel Prediction: A Cross-lingual Study
Dec 16, 2025
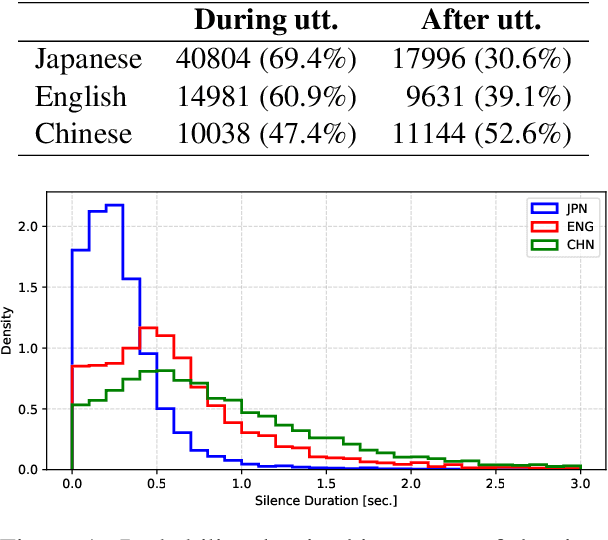
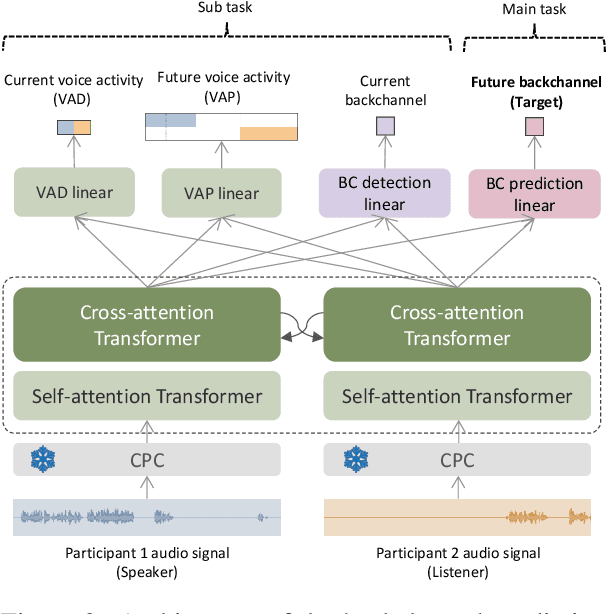
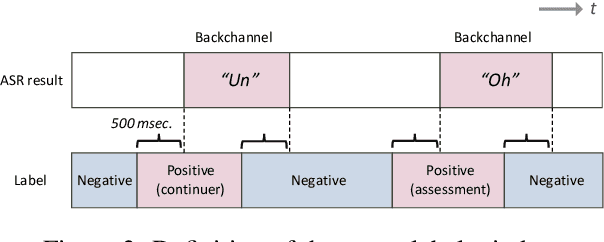
We present a multilingual, continuous backchannel prediction model for Japanese, English, and Chinese, and use it to investigate cross-linguistic timing behavior. The model is Transformer-based and operates at the frame level, jointly trained with auxiliary tasks on approximately 300 hours of dyadic conversations. Across all three languages, the multilingual model matches or surpasses monolingual baselines, indicating that it learns both language-universal cues and language-specific timing patterns. Zero-shot transfer with two-language training remains limited, underscoring substantive cross-lingual differences. Perturbation analyses reveal distinct cue usage: Japanese relies more on short-term linguistic information, whereas English and Chinese are more sensitive to silence duration and prosodic variation; multilingual training encourages shared yet adaptable representations and reduces overreliance on pitch in Chinese. A context-length study further shows that Japanese is relatively robust to shorter contexts, while Chinese benefits markedly from longer contexts. Finally, we integrate the trained model into a real-time processing software, demonstrating CPU-only inference. Together, these findings provide a unified model and empirical evidence for how backchannel timing differs across languages, informing the design of more natural, culturally-aware spoken dialogue systems.
Minority-Aware Satisfaction Estimation in Dialogue Systems via Preference-Adaptive Reinforcement Learning
Nov 07, 2025User satisfaction in dialogue systems is inherently subjective. When the same response strategy is applied across users, minority users may assign different satisfaction ratings than majority users due to variations in individual intents and preferences. However, existing alignment methods typically train one-size-fits-all models that aim for broad consensus, often overlooking minority perspectives and user-specific adaptation. We propose a unified framework that models both individual- and group-level preferences for user satisfaction estimation. First, we introduce Chain-of-Personalized-Reasoning (CoPeR) to capture individual preferences through interpretable reasoning chains. Second, we propose an expectation-maximization-based Majority-Minority Preference-Aware Clustering (M2PC) algorithm that discovers distinct user groups in an unsupervised manner to learn group-level preferences. Finally, we integrate these components into a preference-adaptive reinforcement learning framework (PAda-PPO) that jointly optimizes alignment with both individual and group preferences. Experiments on the Emotional Support Conversation dataset demonstrate consistent improvements in user satisfaction estimation, particularly for underrepresented user groups.
SONAR: Self-Distilled Continual Pre-training for Domain Adaptive Audio Representation
Sep 19, 2025Self-supervised learning (SSL) on large-scale datasets like AudioSet has become the dominant paradigm for audio representation learning. While the continuous influx of new, unlabeled audio presents an opportunity to enrich these static representations, a naive approach is to retrain the model from scratch using all available data. However, this method is computationally prohibitive and discards the valuable knowledge embedded in the previously trained model weights. To address this inefficiency, we propose SONAR (Self-distilled cONtinual pre-training for domain adaptive Audio Representation), a continual pre-training framework built upon BEATs. SONAR effectively adapts to new domains while mitigating catastrophic forgetting by tackling three key challenges: implementing a joint sampling strategy for new and prior data, applying regularization to balance specificity and generality, and dynamically expanding the tokenizer codebook for novel acoustic patterns. Experiments across four distinct domains demonstrate that our method achieves both high adaptability and robust resistance to forgetting.
Triadic Multi-party Voice Activity Projection for Turn-taking in Spoken Dialogue Systems
Jul 10, 2025Turn-taking is a fundamental component of spoken dialogue, however conventional studies mostly involve dyadic settings. This work focuses on applying voice activity projection (VAP) to predict upcoming turn-taking in triadic multi-party scenarios. The goal of VAP models is to predict the future voice activity for each speaker utilizing only acoustic data. This is the first study to extend VAP into triadic conversation. We trained multiple models on a Japanese triadic dataset where participants discussed a variety of topics. We found that the VAP trained on triadic conversation outperformed the baseline for all models but that the type of conversation affected the accuracy. This study establishes that VAP can be used for turn-taking in triadic dialogue scenarios. Future work will incorporate this triadic VAP turn-taking model into spoken dialogue systems.
Bridging Speech Emotion Recognition and Personality: Dataset and Temporal Interaction Condition Network
May 20, 2025This study investigates the interaction between personality traits and emotional expression, exploring how personality information can improve speech emotion recognition (SER). We collected personality annotation for the IEMOCAP dataset, and the statistical analysis identified significant correlations between personality traits and emotional expressions. To extract finegrained personality features, we propose a temporal interaction condition network (TICN), in which personality features are integrated with Hubert-based acoustic features for SER. Experiments show that incorporating ground-truth personality traits significantly enhances valence recognition, improving the concordance correlation coefficient (CCC) from 0.698 to 0.785 compared to the baseline without personality information. For practical applications in dialogue systems where personality information about the user is unavailable, we develop a front-end module of automatic personality recognition. Using these automatically predicted traits as inputs to our proposed TICN model, we achieve a CCC of 0.776 for valence recognition, representing an 11.17% relative improvement over the baseline. These findings confirm the effectiveness of personality-aware SER and provide a solid foundation for further exploration in personality-aware speech processing applications.
Combining Deterministic Enhanced Conditions with Dual-Streaming Encoding for Diffusion-Based Speech Enhancement
May 20, 2025



Diffusion-based speech enhancement (SE) models need to incorporate correct prior knowledge as reliable conditions to generate accurate predictions. However, providing reliable conditions using noisy features is challenging. One solution is to use features enhanced by deterministic methods as conditions. However, the information distortion and loss caused by deterministic methods might affect the diffusion process. In this paper, we first investigate the effects of using different deterministic SE models as conditions for diffusion. We validate two conditions depending on whether the noisy feature was used as part of the condition: one using only the deterministic feature (deterministic-only), and the other using both deterministic and noisy features (deterministic-noisy). Preliminary investigation found that using deterministic enhanced conditions improves hearing experiences on real data, while the choice between using deterministic-only or deterministic-noisy conditions depends on the deterministic models. Based on these findings, we propose a dual-streaming encoding Repair-Diffusion Model for SE (DERDM-SE) to more effectively utilize both conditions. Moreover, we found that fine-grained deterministic models have greater potential in objective evaluation metrics, while UNet-based deterministic models provide more stable diffusion performance. Therefore, in the DERDM-SE, we propose a deterministic model that combines coarse- and fine-grained processing. Experimental results on CHiME4 show that the proposed models effectively leverage deterministic models to achieve better SE evaluation scores, along with more stable performance compared to other diffusion-based SE models.
Does the Appearance of Autonomous Conversational Robots Affect User Spoken Behaviors in Real-World Conference Interactions?
Mar 17, 2025We investigate the impact of robot appearance on users' spoken behavior during real-world interactions by comparing a human-like android, ERICA, with a less anthropomorphic humanoid, TELECO. Analyzing data from 42 participants at SIGDIAL 2024, we extracted linguistic features such as disfluencies and syntactic complexity from conversation transcripts. The results showed moderate effect sizes, suggesting that participants produced fewer disfluencies and employed more complex syntax when interacting with ERICA. Further analysis involving training classification models like Na\"ive Bayes, which achieved an F1-score of 71.60\%, and conducting feature importance analysis, highlighted the significant role of disfluencies and syntactic complexity in interactions with robots of varying human-like appearances. Discussing these findings within the frameworks of cognitive load and Communication Accommodation Theory, we conclude that designing robots to elicit more structured and fluent user speech can enhance their communicative alignment with humans.
A Noise-Robust Turn-Taking System for Real-World Dialogue Robots: A Field Experiment
Mar 08, 2025Turn-taking is a crucial aspect of human-robot interaction, directly influencing conversational fluidity and user engagement. While previous research has explored turn-taking models in controlled environments, their robustness in real-world settings remains underexplored. In this study, we propose a noise-robust voice activity projection (VAP) model, based on a Transformer architecture, to enhance real-time turn-taking in dialogue robots. To evaluate the effectiveness of the proposed system, we conducted a field experiment in a shopping mall, comparing the VAP system with a conventional cloud-based speech recognition system. Our analysis covered both subjective user evaluations and objective behavioral analysis. The results showed that the proposed system significantly reduced response latency, leading to a more natural conversation where both the robot and users responded faster. The subjective evaluations suggested that faster responses contribute to a better interaction experience.