 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Consumer IoT Traffic: Security and Privacy
Mar 24, 2024



For the past few years, the Consumer Internet of Things (CIoT) has entered public lives. While CIoT has improved the convenience of people's daily lives, it has also brought new security and privacy concerns. In this survey, we try to figure out what researchers can learn about the security and privacy of CIoT by traffic analysis, a popular method in the security community. From the security and privacy perspective, this survey seeks out the new characteristics in CIoT traffic analysis, the state-of-the-art progress in CIoT traffic analysis, and the challenges yet to be solved. We collected 310 papers from January 2018 to December 2023 related to CIoT traffic analysis from the security and privacy perspective and summarized the process of CIoT traffic analysis in which the new characteristics of CIoT are identified. Then, we detail existing works based on five application goals: device fingerprinting, user activity inference, malicious traffic analysis, security analysis, and measurement. At last, we discuss the new challenges and future research directions.
Eyes Closed, Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation
Mar 22, 2024



Multimodal large language models (MLLMs) have shown impressive reasoning abilities, which, however, are also more vulnerable to jailbreak attacks than their LLM predecessors. Although still capable of detecting unsafe responses, we observe that safety mechanisms of the pre-aligned LLMs in MLLMs can be easily bypassed due to the introduction of image features. To construct robust MLLMs, we propose ECSO(Eyes Closed, Safety On), a novel training-free protecting approach that exploits the inherent safety awareness of MLLMs, and generates safer responses via adaptively transforming unsafe images into texts to activate intrinsic safety mechanism of pre-aligned LLMs in MLLMs. Experiments on five state-of-the-art (SoTA) MLLMs demonstrate that our ECSO enhances model safety significantly (e.g., a 37.6% improvement on the MM-SafetyBench (SD+OCR), and 71.3% on VLSafe for the LLaVA-1.5-7B), while consistently maintaining utility results on common MLLM benchmarks. Furthermore, we show that ECSO can be used as a data engine to generate supervised-finetuning (SFT) data for MLLM alignment without extra human intervention.
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.
Conditional Score-Based Diffusion Model for Cortical Thickness Trajectory Prediction
Mar 11, 2024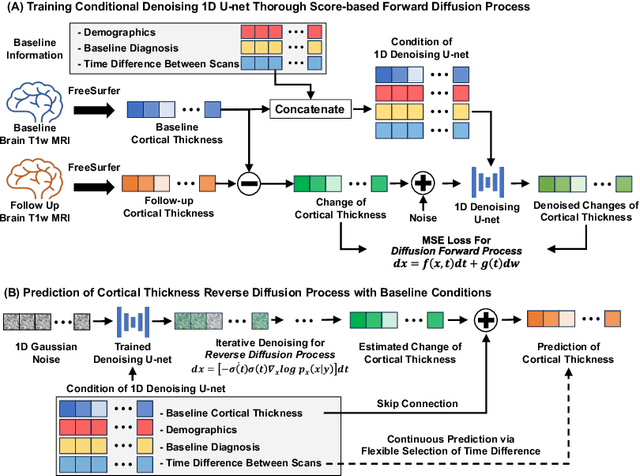
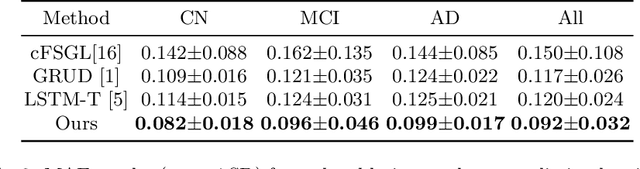
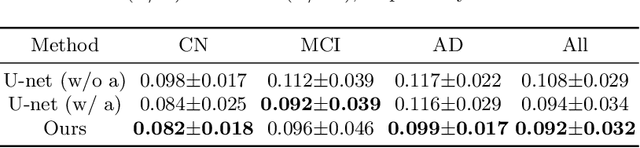
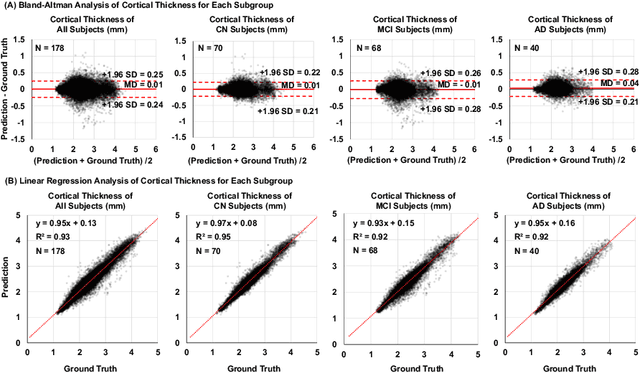
Alzheimer's Disease (AD) is a neurodegenerative condition characterized by diverse progression rates among individuals, with changes in cortical thickness (CTh) closely linked to its progression. Accurately forecasting CTh trajectories can significantly enhance early diagnosis and intervention strategies, providing timely care. However, the longitudinal data essential for these studies often suffer from temporal sparsity and incompleteness, presenting substantial challenges in modeling the disease's progression accurately. Existing methods are limited, focusing primarily on datasets without missing entries or requiring predefined assumptions about CTh progression. To overcome these obstacles, we propose a conditional score-based diffusion model specifically designed to generate CTh trajectories with the given baseline information, such as age, sex, and initial diagnosis. Our conditional diffusion model utilizes all available data during the training phase to make predictions based solely on baseline information during inference without needing prior history about CTh progression. The prediction accuracy of the proposed CTh prediction pipeline using a conditional score-based model was compared for sub-groups consisting of cognitively normal, mild cognitive impairment, and AD subjects. The Bland-Altman analysis shows our diffusion-based prediction model has a near-zero bias with narrow 95% confidential interval compared to the ground-truth CTh in 6-36 months. In addition, our conditional diffusion model has a stochastic generative nature, therefore, we demonstrated an uncertainty analysis of patient-specific CTh prediction through multiple realizations.
ERASOR++: Height Coding Plus Egocentric Ratio Based Dynamic Object Removal for Static Point Cloud Mapping
Mar 08, 2024



Mapping plays a crucial role in location and navigation within automatic systems. However, the presence of dynamic objects in 3D point cloud maps generated from scan sensors can introduce map distortion and long traces, thereby posing challenges for accurate mapping and navigation. To address this issue, we propose ERASOR++, an enhanced approach based on the Egocentric Ratio of Pseudo Occupancy for effective dynamic object removal. To begin, we introduce the Height Coding Descriptor, which combines height difference and height layer information to encode the point cloud. Subsequently, we propose the Height Stack Test, Ground Layer Test, and Surrounding Point Test methods to precisely and efficiently identify the dynamic bins within point cloud bins, thus overcoming the limitations of prior approaches. Through extensive evaluation on open-source datasets, our approach demonstrates superior performance in terms of precision and efficiency compared to existing methods. Furthermore, the techniques described in our work hold promise for addressing various challenging tasks or aspects through subsequent migration.
SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting
Mar 08, 2024We present SplattingAvatar, a hybrid 3D representation of photorealistic human avatars with Gaussian Splatting embedded on a triangle mesh, which renders over 300 FPS on a modern GPU and 30 FPS on a mobile device. We disentangle the motion and appearance of a virtual human with explicit mesh geometry and implicit appearance modeling with Gaussian Splatting. The Gaussians are defined by barycentric coordinates and displacement on a triangle mesh as Phong surfaces. We extend lifted optimization to simultaneously optimize the parameters of the Gaussians while walking on the triangle mesh. SplattingAvatar is a hybrid representation of virtual humans where the mesh represents low-frequency motion and surface deformation, while the Gaussians take over the high-frequency geometry and detailed appearance. Unlike existing deformation methods that rely on an MLP-based linear blend skinning (LBS) field for motion, we control the rotation and translation of the Gaussians directly by mesh, which empowers its compatibility with various animation techniques, e.g., skeletal animation, blend shapes, and mesh editing. Trainable from monocular videos for both full-body and head avatars, SplattingAvatar shows state-of-the-art rendering quality across multiple datasets.
Real-Time Adaptive Safety-Critical Control with Gaussian Processes in High-Order Uncertain Models
Mar 05, 2024This paper presents an adaptive online learning framework for systems with uncertain parameters to ensure safety-critical control in non-stationary environments. Our approach consists of two phases. The initial phase is centered on a novel sparse Gaussian process (GP) framework. We first integrate a forgetting factor to refine a variational sparse GP algorithm, thus enhancing its adaptability. Subsequently, the hyperparameters of the Gaussian model are trained with a specially compound kernel, and the Gaussian model's online inferential capability and computational efficiency are strengthened by updating a solitary inducing point derived from new samples, in conjunction with the learned hyperparameters. In the second phase, we propose a safety filter based on high-order control barrier functions (HOCBFs), synergized with the previously trained learning model. By leveraging the compound kernel from the first phase, we effectively address the inherent limitations of GPs in handling high-dimensional problems for real-time applications. The derived controller ensures a rigorous lower bound on the probability of satisfying the safety specification. Finally, the efficacy of our proposed algorithm is demonstrated through real-time obstacle avoidance experiments executed using both a simulation platform and a real-world 7-DOF robot.
Online Efficient Safety-Critical Control for Mobile Robots in Unknown Dynamic Multi-Obstacle Environments
Feb 26, 2024This paper proposes a LiDAR-based goal-seeking and exploration framework, addressing the efficiency of online obstacle avoidance in unstructured environments populated with static and moving obstacles. This framework addresses two significant challenges associated with traditional dynamic control barrier functions (D-CBFs): their online construction and the diminished real-time performance caused by utilizing multiple D-CBFs. To tackle the first challenge, the framework's perception component begins with clustering point clouds via the DBSCAN algorithm, followed by encapsulating these clusters with the minimum bounding ellipses (MBEs) algorithm to create elliptical representations. By comparing the current state of MBEs with those stored from previous moments, the differentiation between static and dynamic obstacles is realized, and the Kalman filter is utilized to predict the movements of the latter. Such analysis facilitates the D-CBF's online construction for each MBE. To tackle the second challenge, we introduce buffer zones, generating Type-II D-CBFs online for each identified obstacle. Utilizing these buffer zones as activation areas substantially reduces the number of D-CBFs that need to be activated. Upon entering these buffer zones, the system prioritizes safety, autonomously navigating safe paths, and hence referred to as the exploration mode. Exiting these buffer zones triggers the system's transition to goal-seeking mode. We demonstrate that the system's states under this framework achieve safety and asymptotic stabilization. Experimental results in simulated and real-world environments have validated our framework's capability, allowing a LiDAR-equipped mobile robot to efficiently and safely reach the desired location within dynamic environments containing multiple obstacles.
CFRet-DVQA: Coarse-to-Fine Retrieval and Efficient Tuning for Document Visual Question Answering
Feb 26, 2024



Document Visual Question Answering (DVQA) is a task that involves responding to queries based on the content of images. Existing work is limited to locating information within a single page and does not facilitate cross-page question-and-answer interaction. Furthermore, the token length limitation imposed on inputs to the model may lead to truncation of segments pertinent to the answer. In this study, we introduce a simple but effective methodology called CFRet-DVQA, which focuses on retrieval and efficient tuning to address this critical issue effectively. For that, we initially retrieve multiple segments from the document that correlate with the question at hand. Subsequently, we leverage the advanced reasoning abilities of the large language model (LLM), further augmenting its performance through instruction tuning. This approach enables the generation of answers that align with the style of the document labels. The experiments demonstrate that our methodology achieved state-of-the-art or competitive results with both single-page and multi-page documents in various fields.
A Unified Taxonomy-Guided Instruction Tuning Framework for Entity Set Expansion and Taxonomy Expansion
Feb 20, 2024Entity Set Expansion, Taxonomy Expansion, and Seed-Guided Taxonomy Construction are three representative tasks that can be used to automatically populate an existing taxonomy with new entities. However, previous approaches often address these tasks separately with heterogeneous techniques, lacking a unified perspective. To tackle this issue, in this paper, we identify the common key skills needed for these tasks from the view of taxonomy structures -- finding 'siblings' and finding 'parents' -- and propose a unified taxonomy-guided instruction tuning framework to jointly solve the three tasks. To be specific, by leveraging the existing taxonomy as a rich source of entity relationships, we utilize instruction tuning to fine-tune a large language model to generate parent and sibling entities. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of TaxoInstruct, which outperforms task-specific baselines across all three tasks.