 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstraea: A State-Aware Scheduling Engine for LLM-Powered Agents
Dec 16, 2025



Large Language Models (LLMs) are increasingly being deployed as intelligent agents. Their multi-stage workflows, which alternate between local computation and calls to external network services like Web APIs, introduce a mismatch in their execution pattern and the scheduling granularity of existing inference systems such as vLLM. Existing systems typically focus on per-segment optimization which prevents them from minimizing the end-to-end latency of the complete agentic workflow, i.e., the global Job Completion Time (JCT) over the entire request lifecycle. To address this limitation, we propose Astraea, a service engine designed to shift the optimization from local segments to the global request lifecycle. Astraea employs a state-aware, hierarchical scheduling algorithm that integrates a request's historical state with future predictions. It dynamically classifies requests by their I/O and compute intensive nature and uses an enhanced HRRN policy to balance efficiency and fairness. Astraea also implements an adaptive KV cache manager that intelligently handles the agent state during I/O waits based on the system memory pressure. Extensive experiments show that Astraea reduces average JCT by up to 25.5\% compared to baseline methods. Moreover, our approach demonstrates strong robustness and stability under high load across various model scales.
ERASOR++: Height Coding Plus Egocentric Ratio Based Dynamic Object Removal for Static Point Cloud Mapping
Mar 08, 2024



Mapping plays a crucial role in location and navigation within automatic systems. However, the presence of dynamic objects in 3D point cloud maps generated from scan sensors can introduce map distortion and long traces, thereby posing challenges for accurate mapping and navigation. To address this issue, we propose ERASOR++, an enhanced approach based on the Egocentric Ratio of Pseudo Occupancy for effective dynamic object removal. To begin, we introduce the Height Coding Descriptor, which combines height difference and height layer information to encode the point cloud. Subsequently, we propose the Height Stack Test, Ground Layer Test, and Surrounding Point Test methods to precisely and efficiently identify the dynamic bins within point cloud bins, thus overcoming the limitations of prior approaches. Through extensive evaluation on open-source datasets, our approach demonstrates superior performance in terms of precision and efficiency compared to existing methods. Furthermore, the techniques described in our work hold promise for addressing various challenging tasks or aspects through subsequent migration.
AugSplicing: Synchronized Behavior Detection in Streaming Tensors
Jan 05, 2021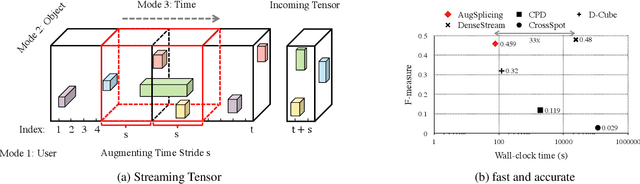
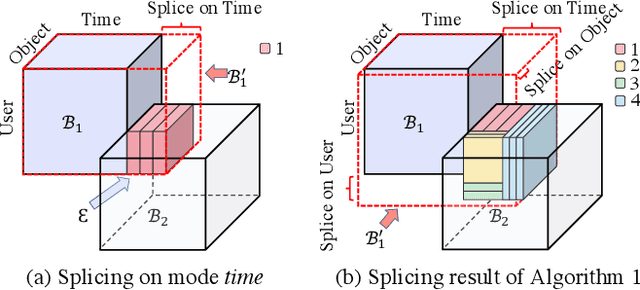
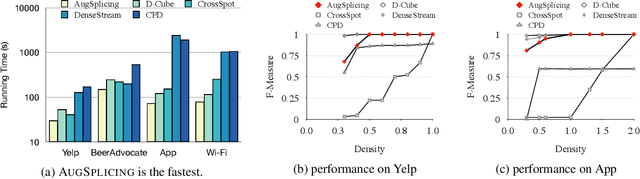
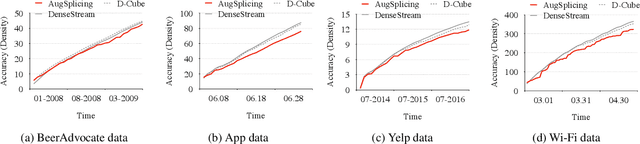
How can we track synchronized behavior in a stream of time-stamped tuples, such as mobile devices installing and uninstalling applications in the lockstep, to boost their ranks in the app store? We model such tuples as entries in a streaming tensor, which augments attribute sizes in its modes over time. Synchronized behavior tends to form dense blocks (i.e. subtensors) in such a tensor, signaling anomalous behavior, or interesting communities. However, existing dense block detection methods are either based on a static tensor, or lack an efficient algorithm in a streaming setting. Therefore, we propose a fast streaming algorithm, AugSplicing, which can detect the top dense blocks by incrementally splicing the previous detection with the incoming ones in new tuples, avoiding re-runs over all the history data at every tracking time step. AugSplicing is based on a splicing condition that guides the algorithm (Section 4). Compared to the state-of-the-art methods, our method is (1) effective to detect fraudulent behavior in installing data of real-world apps and find a synchronized group of students with interesting features in campus Wi-Fi data; (2) robust with splicing theory for dense block detection; (3) streaming and faster than the existing streaming algorithm, with closely comparable accuracy.