 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedASR2S: A State-of-the-Art Industrial-Grade All-in-One Automatic Speech Recognition System
Mar 11, 2026We present FireRedASR2S, a state-of-the-art industrial-grade all-in-one automatic speech recognition (ASR) system. It integrates four modules in a unified pipeline: ASR, Voice Activity Detection (VAD), Spoken Language Identification (LID), and Punctuation Prediction (Punc). All modules achieve SOTA performance on the evaluated benchmarks: FireRedASR2: An ASR module with two variants, FireRedASR2-LLM (8B+ parameters) and FireRedASR2-AED (1B+ parameters), supporting speech and singing transcription for Mandarin, Chinese dialects and accents, English, and code-switching. Compared to FireRedASR, FireRedASR2 delivers improved recognition accuracy and broader dialect and accent coverage. FireRedASR2-LLM achieves 2.89% average CER on 4 public Mandarin benchmarks and 11.55% on 19 public Chinese dialects and accents benchmarks, outperforming competitive baselines including Doubao-ASR, Qwen3-ASR, and Fun-ASR. FireRedVAD: An ultra-lightweight module (0.6M parameters) based on the Deep Feedforward Sequential Memory Network (DFSMN), supporting streaming VAD, non-streaming VAD, and multi-label VAD (mVAD). On the FLEURS-VAD-102 benchmark, it achieves 97.57% frame-level F1 and 99.60% AUC-ROC, outperforming Silero-VAD, TEN-VAD, FunASR-VAD, and WebRTC-VAD. FireRedLID: An Encoder-Decoder LID module supporting 100+ languages and 20+ Chinese dialects and accents. On FLEURS (82 languages), it achieves 97.18% utterance-level accuracy, outperforming Whisper and SpeechBrain. FireRedPunc: A BERT-style punctuation prediction module for Chinese and English. On multi-domain benchmarks, it achieves 78.90% average F1, outperforming FunASR-Punc (62.77%). To advance research in speech processing, we release model weights and code at https://github.com/FireRedTeam/FireRedASR2S.
A Calibrated Memorization Index (MI) for Detecting Training Data Leakage in Generative MRI Models
Feb 13, 2026Image generative models are known to duplicate images from the training data as part of their outputs, which can lead to privacy concerns when used for medical image generation. We propose a calibrated per-sample metric for detecting memorization and duplication of training data. Our metric uses image features extracted using an MRI foundation model, aggregates multi-layer whitened nearest-neighbor similarities, and maps them to a bounded \emph{Overfit/Novelty Index} (ONI) and \emph{Memorization Index} (MI) scores. Across three MRI datasets with controlled duplication percentages and typical image augmentations, our metric robustly detects duplication and provides more consistent metric values across datasets. At the sample level, our metric achieves near-perfect detection of duplicates.
MATRIX: Multi-Agent simulaTion fRamework for safe Interactions and conteXtual clinical conversational evaluation
Aug 26, 2025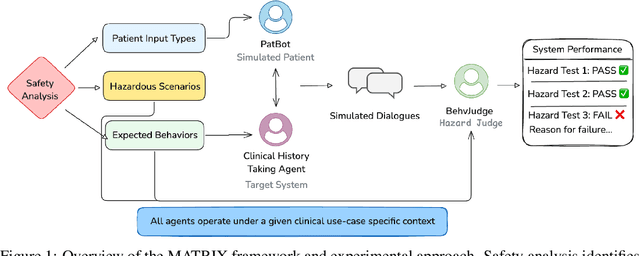


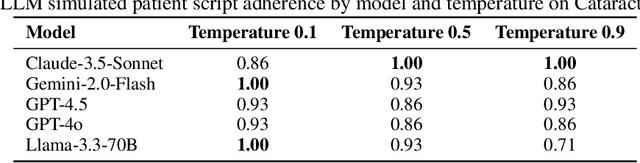
Despite the growing use of large language models (LLMs) in clinical dialogue systems, existing evaluations focus on task completion or fluency, offering little insight into the behavioral and risk management requirements essential for safety-critical systems. This paper presents MATRIX (Multi-Agent simulaTion fRamework for safe Interactions and conteXtual clinical conversational evaluation), a structured, extensible framework for safety-oriented evaluation of clinical dialogue agents. MATRIX integrates three components: (1) a safety-aligned taxonomy of clinical scenarios, expected system behaviors and failure modes derived through structured safety engineering methods; (2) BehvJudge, an LLM-based evaluator for detecting safety-relevant dialogue failures, validated against expert clinician annotations; and (3) PatBot, a simulated patient agent capable of producing diverse, scenario-conditioned responses, evaluated for realism and behavioral fidelity with human factors expertise, and a patient-preference study. Across three experiments, we show that MATRIX enables systematic, scalable safety evaluation. BehvJudge with Gemini 2.5-Pro achieves expert-level hazard detection (F1 0.96, sensitivity 0.999), outperforming clinicians in a blinded assessment of 240 dialogues. We also conducted one of the first realism analyses of LLM-based patient simulation, showing that PatBot reliably simulates realistic patient behavior in quantitative and qualitative evaluations. Using MATRIX, we demonstrate its effectiveness in benchmarking five LLM agents across 2,100 simulated dialogues spanning 14 hazard scenarios and 10 clinical domains. MATRIX is the first framework to unify structured safety engineering with scalable, validated conversational AI evaluation, enabling regulator-aligned safety auditing. We release all evaluation tools, prompts, structured scenarios, and datasets.
Metrics that matter: Evaluating image quality metrics for medical image generation
May 12, 2025Evaluating generative models for synthetic medical imaging is crucial yet challenging, especially given the high standards of fidelity, anatomical accuracy, and safety required for clinical applications. Standard evaluation of generated images often relies on no-reference image quality metrics when ground truth images are unavailable, but their reliability in this complex domain is not well established. This study comprehensively assesses commonly used no-reference image quality metrics using brain MRI data, including tumour and vascular images, providing a representative exemplar for the field. We systematically evaluate metric sensitivity to a range of challenges, including noise, distribution shifts, and, critically, localised morphological alterations designed to mimic clinically relevant inaccuracies. We then compare these metric scores against model performance on a relevant downstream segmentation task, analysing results across both controlled image perturbations and outputs from different generative model architectures. Our findings reveal significant limitations: many widely-used no-reference image quality metrics correlate poorly with downstream task suitability and exhibit a profound insensitivity to localised anatomical details crucial for clinical validity. Furthermore, these metrics can yield misleading scores regarding distribution shifts, e.g. data memorisation. This reveals the risk of misjudging model readiness, potentially leading to the deployment of flawed tools that could compromise patient safety. We conclude that ensuring generative models are truly fit for clinical purpose requires a multifaceted validation framework, integrating performance on relevant downstream tasks with the cautious interpretation of carefully selected no-reference image quality metrics.
The case for delegated AI autonomy for Human AI teaming in healthcare
Mar 24, 2025In this paper we propose an advanced approach to integrating artificial intelligence (AI) into healthcare: autonomous decision support. This approach allows the AI algorithm to act autonomously for a subset of patient cases whilst serving a supportive role in other subsets of patient cases based on defined delegation criteria. By leveraging the complementary strengths of both humans and AI, it aims to deliver greater overall performance than existing human-AI teaming models. It ensures safe handling of patient cases and potentially reduces clinician review time, whilst being mindful of AI tool limitations. After setting the approach within the context of current human-AI teaming models, we outline the delegation criteria and apply them to a specific AI-based tool used in histopathology. The potential impact of the approach and the regulatory requirements for its successful implementation are then discussed.
Evolutionary Trigger Detection and Lightweight Model Repair Based Backdoor Defense
Jul 07, 2024



Deep Neural Networks (DNNs) have been widely used in many areas such as autonomous driving and face recognition. However, DNN model is fragile to backdoor attack. A backdoor in the DNN model can be activated by a poisoned input with trigger and leads to wrong prediction, which causes serious security issues in applications. It is challenging for current defenses to eliminate the backdoor effectively with limited computing resources, especially when the sizes and numbers of the triggers are variable as in the physical world. We propose an efficient backdoor defense based on evolutionary trigger detection and lightweight model repair. In the first phase of our method, CAM-focus Evolutionary Trigger Filter (CETF) is proposed for trigger detection. CETF is an effective sample-preprocessing based method with the evolutionary algorithm, and our experimental results show that CETF not only distinguishes the images with triggers accurately from the clean images, but also can be widely used in practice for its simplicity and stability in different backdoor attack situations. In the second phase of our method, we leverage several lightweight unlearning methods with the trigger detected by CETF for model repair, which also constructively demonstrate the underlying correlation of the backdoor with Batch Normalization layers. Source code will be published after accepted.
A Survey on Consumer IoT Traffic: Security and Privacy
Mar 24, 2024



For the past few years, the Consumer Internet of Things (CIoT) has entered public lives. While CIoT has improved the convenience of people's daily lives, it has also brought new security and privacy concerns. In this survey, we try to figure out what researchers can learn about the security and privacy of CIoT by traffic analysis, a popular method in the security community. From the security and privacy perspective, this survey seeks out the new characteristics in CIoT traffic analysis, the state-of-the-art progress in CIoT traffic analysis, and the challenges yet to be solved. We collected 310 papers from January 2018 to December 2023 related to CIoT traffic analysis from the security and privacy perspective and summarized the process of CIoT traffic analysis in which the new characteristics of CIoT are identified. Then, we detail existing works based on five application goals: device fingerprinting, user activity inference, malicious traffic analysis, security analysis, and measurement. At last, we discuss the new challenges and future research directions.
Syntax-Guided Domain Adaptation for Aspect-based Sentiment Analysis
Nov 10, 2022



Aspect-based sentiment analysis (ABSA) aims at extracting opinionated aspect terms in review texts and determining their sentiment polarities, which is widely studied in both academia and industry. As a fine-grained classification task, the annotation cost is extremely high. Domain adaptation is a popular solution to alleviate the data deficiency issue in new domains by transferring common knowledge across domains. Most cross-domain ABSA studies are based on structure correspondence learning (SCL), and use pivot features to construct auxiliary tasks for narrowing down the gap between domains. However, their pivot-based auxiliary tasks can only transfer knowledge of aspect terms but not sentiment, limiting the performance of existing models. In this work, we propose a novel Syntax-guided Domain Adaptation Model, named SDAM, for more effective cross-domain ABSA. SDAM exploits syntactic structure similarities for building pseudo training instances, during which aspect terms of target domain are explicitly related to sentiment polarities. Besides, we propose a syntax-based BERT mask language model for further capturing domain-invariant features. Finally, to alleviate the sentiment inconsistency issue in multi-gram aspect terms, we introduce a span-based joint aspect term and sentiment analysis module into the cross-domain End2End ABSA. Experiments on five benchmark datasets show that our model consistently outperforms the state-of-the-art baselines with respect to Micro-F1 metric for the cross-domain End2End ABSA task.
LeVoice ASR Systems for the ISCSLP 2022 Intelligent Cockpit Speech Recognition Challenge
Oct 17, 2022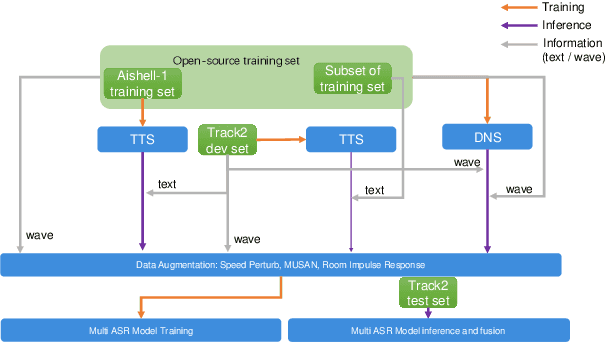
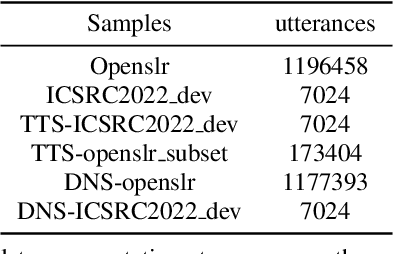
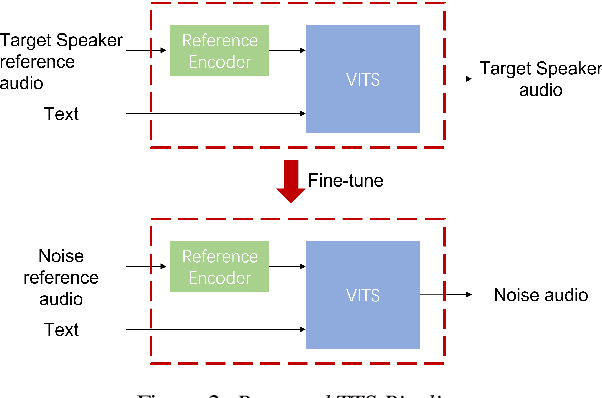
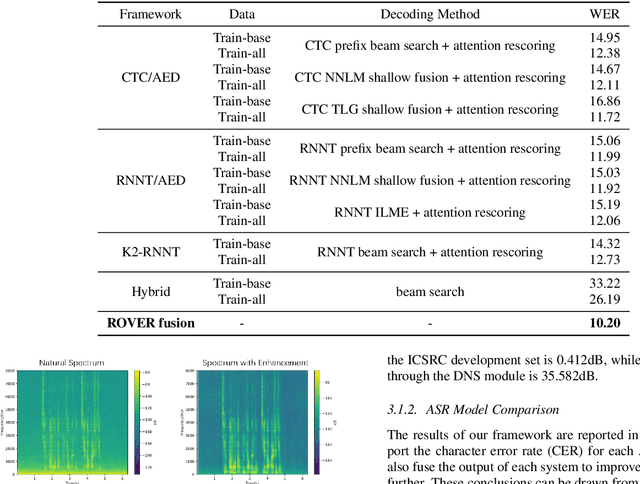
This paper describes LeVoice automatic speech recognition systems to track2 of intelligent cockpit speech recognition challenge 2022. Track2 is a speech recognition task without limits on the scope of model size. Our main points include deep learning based speech enhancement, text-to-speech based speech generation, training data augmentation via various techniques and speech recognition model fusion. We compared and fused the hybrid architecture and two kinds of end-to-end architecture. For end-to-end modeling, we used models based on connectionist temporal classification/attention-based encoder-decoder architecture and recurrent neural network transducer/attention-based encoder-decoder architecture. The performance of these models is evaluated with an additional language model to improve word error rates. As a result, our system achieved 10.2\% character error rate on the challenge test set data and ranked third place among the submitted systems in the challenge.
Generating Adversarial Samples For Training Wake-up Word Detection Systems Against Confusing Words
Jan 01, 2022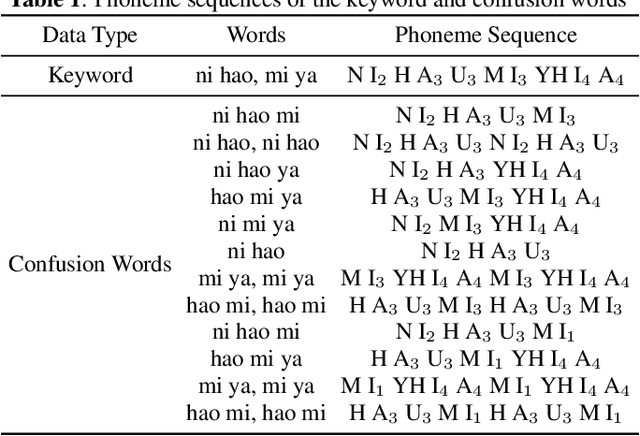
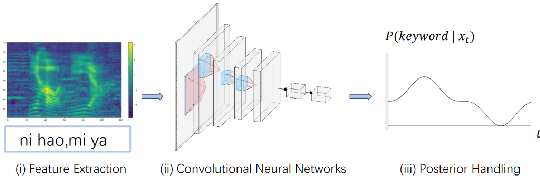
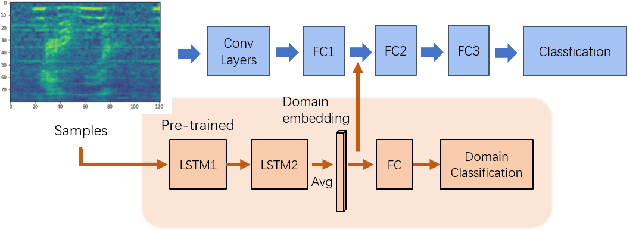
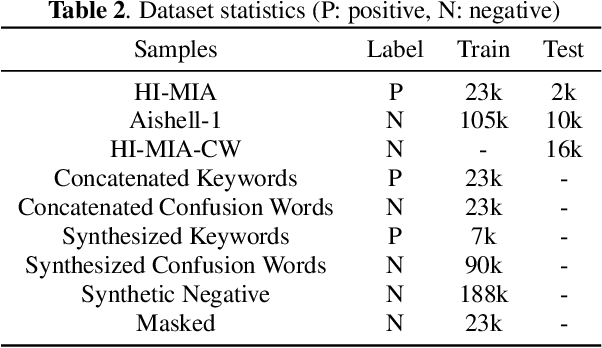
Wake-up word detection models are widely used in real life, but suffer from severe performance degradation when encountering adversarial samples. In this paper we discuss the concept of confusing words in adversarial samples. Confusing words are commonly encountered, which are various kinds of words that sound similar to the predefined keywords. To enhance the wake word detection system's robustness against confusing words, we propose several methods to generate the adversarial confusing samples for simulating real confusing words scenarios in which we usually do not have any real confusing samples in the training set. The generated samples include concatenated audio, synthesized data, and partially masked keywords. Moreover, we use a domain embedding concatenated system to improve the performance. Experimental results show that the adversarial samples generated in our approach help improve the system's robustness in both the common scenario and the confusing words scenario. In addition, we release the confusing words testing database called HI-MIA-CW for future research.