 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurst Image Super-Resolution via Multi-Cross Attention Encoding and Multi-Scan State-Space Decoding
May 26, 2025



Multi-image super-resolution (MISR) can achieve higher image quality than single-image super-resolution (SISR) by aggregating sub-pixel information from multiple spatially shifted frames. Among MISR tasks, burst super-resolution (BurstSR) has gained significant attention due to its wide range of applications. Recent methods have increasingly adopted Transformers over convolutional neural networks (CNNs) in super-resolution tasks, due to their superior ability to capture both local and global context. However, most existing approaches still rely on fixed and narrow attention windows that restrict the perception of features beyond the local field. This limitation hampers alignment and feature aggregation, both of which are crucial for high-quality super-resolution. To address these limitations, we propose a novel feature extractor that incorporates two newly designed attention mechanisms: overlapping cross-window attention and cross-frame attention, enabling more precise and efficient extraction of sub-pixel information across multiple frames. Furthermore, we introduce a Multi-scan State-Space Module with the cross-frame attention mechanism to enhance feature aggregation. Extensive experiments on both synthetic and real-world benchmarks demonstrate the superiority of our approach. Additional evaluations on ISO 12233 resolution test charts further confirm its enhanced super-resolution performance.
Enhancing Text-to-Image Diffusion Transformer via Split-Text Conditioning
May 25, 2025Current text-to-image diffusion generation typically employs complete-text conditioning. Due to the intricate syntax, diffusion transformers (DiTs) inherently suffer from a comprehension defect of complete-text captions. One-fly complete-text input either overlooks critical semantic details or causes semantic confusion by simultaneously modeling diverse semantic primitive types. To mitigate this defect of DiTs, we propose a novel split-text conditioning framework named DiT-ST. This framework converts a complete-text caption into a split-text caption, a collection of simplified sentences, to explicitly express various semantic primitives and their interconnections. The split-text caption is then injected into different denoising stages of DiT-ST in a hierarchical and incremental manner. Specifically, DiT-ST leverages Large Language Models to parse captions, extracting diverse primitives and hierarchically sorting out and constructing these primitives into a split-text input. Moreover, we partition the diffusion denoising process according to its differential sensitivities to diverse semantic primitive types and determine the appropriate timesteps to incrementally inject tokens of diverse semantic primitive types into input tokens via cross-attention. In this way, DiT-ST enhances the representation learning of specific semantic primitive types across different stages. Extensive experiments validate the effectiveness of our proposed DiT-ST in mitigating the complete-text comprehension defect.
MOSLIM:Align with diverse preferences in prompts through reward classification
May 24, 2025The multi-objective alignment of Large Language Models (LLMs) is essential for ensuring foundational models conform to diverse human preferences. Current research in this field typically involves either multiple policies or multiple reward models customized for various preferences, or the need to train a preference-specific supervised fine-tuning (SFT) model. In this work, we introduce a novel multi-objective alignment method, MOSLIM, which utilizes a single reward model and policy model to address diverse objectives. MOSLIM provides a flexible way to control these objectives through prompting and does not require preference training during SFT phase, allowing thousands of off-the-shelf models to be directly utilized within this training framework. MOSLIM leverages a multi-head reward model that classifies question-answer pairs instead of scoring them and then optimize policy model with a scalar reward derived from a mapping function that converts classification results from reward model into reward scores. We demonstrate the efficacy of our proposed method across several multi-objective benchmarks and conduct ablation studies on various reward model sizes and policy optimization methods. The MOSLIM method outperforms current multi-objective approaches in most results while requiring significantly fewer GPU computing resources compared with existing policy optimization methods.
Consistent World Models via Foresight Diffusion
May 22, 2025Diffusion and flow-based models have enabled significant progress in generation tasks across various modalities and have recently found applications in world modeling. However, unlike typical generation tasks that encourage sample diversity, world models entail different sources of uncertainty and require consistent samples aligned with the ground-truth trajectory, which is a limitation we empirically observe in diffusion models. We argue that a key bottleneck in learning consistent diffusion-based world models lies in the suboptimal predictive ability, which we attribute to the entanglement of condition understanding and target denoising within shared architectures and co-training schemes. To address this, we propose Foresight Diffusion (ForeDiff), a diffusion-based world modeling framework that enhances consistency by decoupling condition understanding from target denoising. ForeDiff incorporates a separate deterministic predictive stream to process conditioning inputs independently of the denoising stream, and further leverages a pretrained predictor to extract informative representations that guide generation. Extensive experiments on robot video prediction and scientific spatiotemporal forecasting show that ForeDiff improves both predictive accuracy and sample consistency over strong baselines, offering a promising direction for diffusion-based world models.
Internal and External Impacts of Natural Language Processing Papers
May 21, 2025We investigate the impacts of NLP research published in top-tier conferences (i.e., ACL, EMNLP, and NAACL) from 1979 to 2024. By analyzing citations from research articles and external sources such as patents, media, and policy documents, we examine how different NLP topics are consumed both within the academic community and by the broader public. Our findings reveal that language modeling has the widest internal and external influence, while linguistic foundations have lower impacts. We also observe that internal and external impacts generally align, but topics like ethics, bias, and fairness show significant attention in policy documents with much fewer academic citations. Additionally, external domains exhibit distinct preferences, with patents focusing on practical NLP applications and media and policy documents engaging more with the societal implications of NLP models.
Reconstruction of Graph Signals on Complex Manifolds with Kernel Methods
May 21, 2025Graph signals are widely used to describe vertex attributes or features in graph-structured data, with applications spanning the internet, social media, transportation, sensor networks, and biomedicine. Graph signal processing (GSP) has emerged to facilitate the analysis, processing, and sampling of such signals. While kernel methods have been extensively studied for estimating graph signals from samples provided on a subset of vertices, their application to complex-valued graph signals remains largely unexplored. This paper introduces a novel framework for reconstructing graph signals using kernel methods on complex manifolds. By embedding graph vertices into a higher-dimensional complex ambient space that approximates a lower-dimensional manifold, the framework extends the reproducing kernel Hilbert space to complex manifolds. It leverages Hermitian metrics and geometric measures to characterize kernels and graph signals. Additionally, several traditional kernels and graph topology-driven kernels are proposed for reconstructing complex graph signals. Finally, experimental results on synthetic and real-world datasets demonstrate the effectiveness of this framework in accurately reconstructing complex graph signals, outperforming conventional kernel-based approaches. This work lays a foundational basis for integrating complex geometry and kernel methods in GSP.
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
May 20, 2025



Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks.
HR-VILAGE-3K3M: A Human Respiratory Viral Immunization Longitudinal Gene Expression Dataset for Systems Immunity
May 19, 2025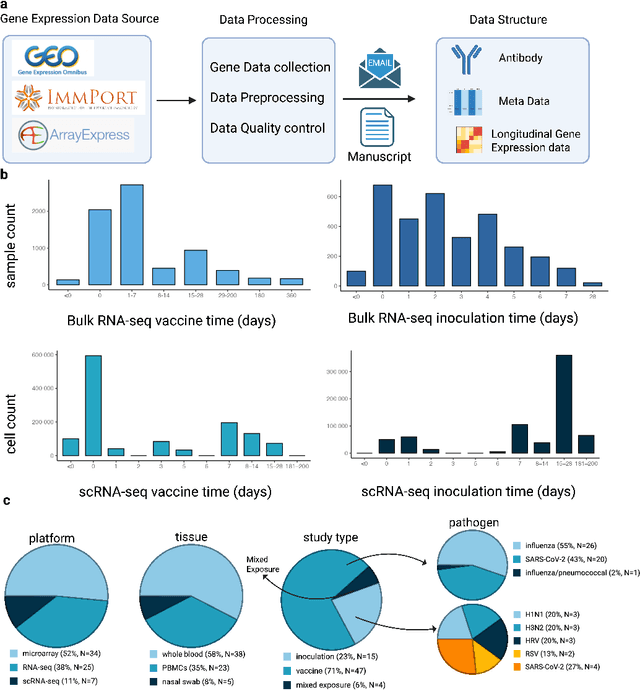
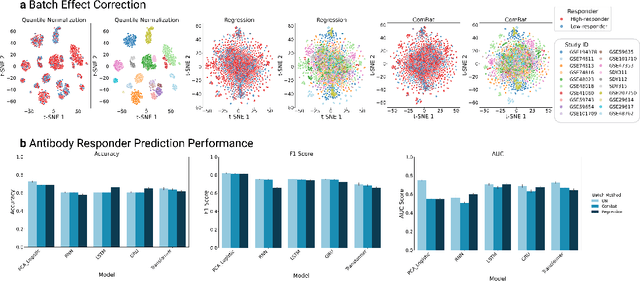
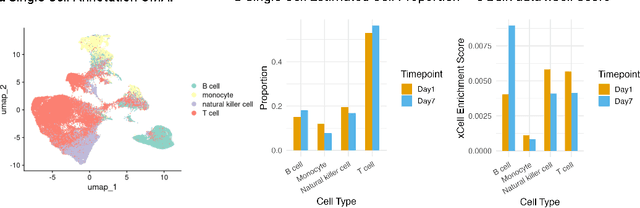
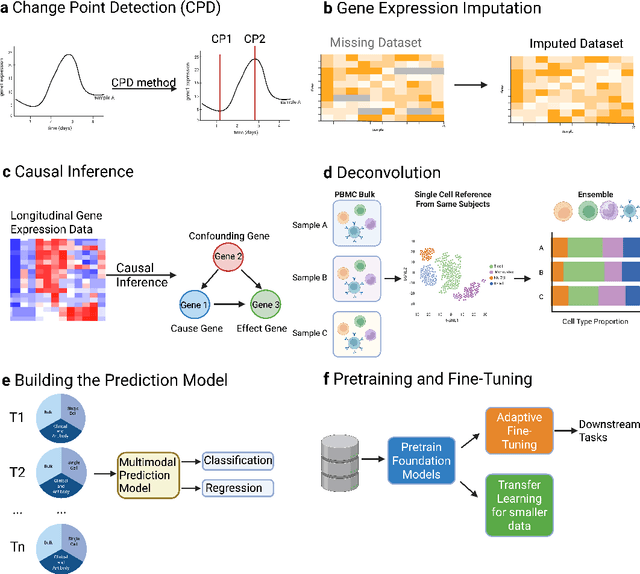
Respiratory viral infections pose a global health burden, yet the cellular immune responses driving protection or pathology remain unclear. Natural infection cohorts often lack pre-exposure baseline data and structured temporal sampling. In contrast, inoculation and vaccination trials generate insightful longitudinal transcriptomic data. However, the scattering of these datasets across platforms, along with inconsistent metadata and preprocessing procedure, hinders AI-driven discovery. To address these challenges, we developed the Human Respiratory Viral Immunization LongitudinAl Gene Expression (HR-VILAGE-3K3M) repository: an AI-ready, rigorously curated dataset that integrates 14,136 RNA-seq profiles from 3,178 subjects across 66 studies encompassing over 2.56 million cells. Spanning vaccination, inoculation, and mixed exposures, the dataset includes microarray, bulk RNA-seq, and single-cell RNA-seq from whole blood, PBMCs, and nasal swabs, sourced from GEO, ImmPort, and ArrayExpress. We harmonized subject-level metadata, standardized outcome measures, applied unified preprocessing pipelines with rigorous quality control, and aligned all data to official gene symbols. To demonstrate the utility of HR-VILAGE-3K3M, we performed predictive modeling of vaccine responders and evaluated batch-effect correction methods. Beyond these initial demonstrations, it supports diverse systems immunology applications and benchmarking of feature selection and transfer learning algorithms. Its scale and heterogeneity also make it ideal for pretraining foundation models of the human immune response and for advancing multimodal learning frameworks. As the largest longitudinal transcriptomic resource for human respiratory viral immunization, it provides an accessible platform for reproducible AI-driven research, accelerating systems immunology and vaccine development against emerging viral threats.
ChromFound: Towards A Universal Foundation Model for Single-Cell Chromatin Accessibility Data
May 19, 2025The advent of single-cell Assay for Transposase-Accessible Chromatin using sequencing (scATAC-seq) offers an innovative perspective for deciphering regulatory mechanisms by assembling a vast repository of single-cell chromatin accessibility data. While foundation models have achieved significant success in single-cell transcriptomics, there is currently no foundation model for scATAC-seq that supports zero-shot high-quality cell identification and comprehensive multi-omics analysis simultaneously. Key challenges lie in the high dimensionality and sparsity of scATAC-seq data, as well as the lack of a standardized schema for representing open chromatin regions (OCRs). Here, we present \textbf{ChromFound}, a foundation model tailored for scATAC-seq. ChromFound utilizes a hybrid architecture and genome-aware tokenization to effectively capture genome-wide long contexts and regulatory signals from dynamic chromatin landscapes. Pretrained on 1.97 million cells from 30 tissues and 6 disease conditions, ChromFound demonstrates broad applicability across 6 diverse tasks. Notably, it achieves robust zero-shot performance in generating universal cell representations and exhibits excellent transferability in cell type annotation and cross-omics prediction. By uncovering enhancer-gene links undetected by existing computational methods, ChromFound offers a promising framework for understanding disease risk variants in the noncoding genome.
FLASH: Latent-Aware Semi-Autoregressive Speculative Decoding for Multimodal Tasks
May 19, 2025Large language and multimodal models (LLMs and LMMs) exhibit strong inference capabilities but are often limited by slow decoding speeds. This challenge is especially acute in LMMs, where visual inputs typically comprise more tokens with lower information density than text -- an issue exacerbated by recent trends toward finer-grained visual tokenizations to boost performance. Speculative decoding has been effective in accelerating LLM inference by using a smaller draft model to generate candidate tokens, which are then selectively verified by the target model, improving speed without sacrificing output quality. While this strategy has been extended to LMMs, existing methods largely overlook the unique properties of visual inputs and depend solely on text-based draft models. In this work, we propose \textbf{FLASH} (Fast Latent-Aware Semi-Autoregressive Heuristics), a speculative decoding framework designed specifically for LMMs, which leverages two key properties of multimodal data to design the draft model. First, to address redundancy in visual tokens, we propose a lightweight latent-aware token compression mechanism. Second, recognizing that visual objects often co-occur within a scene, we employ a semi-autoregressive decoding strategy to generate multiple tokens per forward pass. These innovations accelerate draft decoding while maintaining high acceptance rates, resulting in faster overall inference. Experiments show that FLASH significantly outperforms prior speculative decoding approaches in both unimodal and multimodal settings, achieving up to \textbf{2.68$\times$} speed-up on video captioning and \textbf{2.55$\times$} on visual instruction tuning tasks compared to the original LMM.