 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
Zero-shot Cross-lingual Voice Transfer for TTS
Sep 20, 2024

In this paper, we introduce a zero-shot Voice Transfer (VT) module that can be seamlessly integrated into a multi-lingual Text-to-speech (TTS) system to transfer an individual's voice across languages. Our proposed VT module comprises a speaker-encoder that processes reference speech, a bottleneck layer, and residual adapters, connected to preexisting TTS layers. We compare the performance of various configurations of these components and report Mean Opinion Score (MOS) and Speaker Similarity across languages. Using a single English reference speech per speaker, we achieve an average voice transfer similarity score of 73% across nine target languages. Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, due to physical or neurological conditions, can lead to a profound sense of loss, impacting one's core identity. As a case study, we demonstrate that our approach can not only transfer typical speech but also restore the voices of individuals with dysarthria, even when only atypical speech samples are available - a valuable utility for those who have never had typical speech or banked their voice. Cross-lingual typical audio samples, plus videos demonstrating voice restoration for dysarthric speakers are available here (google.github.io/tacotron/publications/zero_shot_voice_transfer).
Adversarial training of Keyword Spotting to Minimize TTS Data Overfitting
Aug 20, 2024



The keyword spotting (KWS) problem requires large amounts of real speech training data to achieve high accuracy across diverse populations. Utilizing large amounts of text-to-speech (TTS) synthesized data can reduce the cost and time associated with KWS development. However, TTS data may contain artifacts not present in real speech, which the KWS model can exploit (overfit), leading to degraded accuracy on real speech. To address this issue, we propose applying an adversarial training method to prevent the KWS model from learning TTS-specific features when trained on large amounts of TTS data. Experimental results demonstrate that KWS model accuracy on real speech data can be improved by up to 12% when adversarial loss is used in addition to the original KWS loss. Surprisingly, we also observed that the adversarial setup improves accuracy by up to 8%, even when trained solely on TTS and real negative speech data, without any real positive examples.
Utilizing TTS Synthesized Data for Efficient Development of Keyword Spotting Model
Jul 26, 2024



This paper explores the use of TTS synthesized training data for KWS (keyword spotting) task while minimizing development cost and time. Keyword spotting models require a huge amount of training data to be accurate, and obtaining such training data can be costly. In the current state of the art, TTS models can generate large amounts of natural-sounding data, which can help reducing cost and time for KWS model development. Still, TTS generated data can be lacking diversity compared to real data. To pursue maximizing KWS model accuracy under the constraint of limited resources and current TTS capability, we explored various strategies to mix TTS data and real human speech data, with a focus on minimizing real data use and maximizing diversity of TTS output. Our experimental results indicate that relatively small amounts of real audio data with speaker diversity (100 speakers, 2k utterances) and large amounts of TTS synthesized data can achieve reasonably high accuracy (within 3x error rate of baseline), compared to the baseline (trained with 3.8M real positive utterances).
Extending Multilingual Speech Synthesis to 100+ Languages without Transcribed Data
Feb 29, 2024



Collecting high-quality studio recordings of audio is challenging, which limits the language coverage of text-to-speech (TTS) systems. This paper proposes a framework for scaling a multilingual TTS model to 100+ languages using found data without supervision. The proposed framework combines speech-text encoder pretraining with unsupervised training using untranscribed speech and unspoken text data sources, thereby leveraging massively multilingual joint speech and text representation learning. Without any transcribed speech in a new language, this TTS model can generate intelligible speech in >30 unseen languages (CER difference of <10% to ground truth). With just 15 minutes of transcribed, found data, we can reduce the intelligibility difference to 1% or less from the ground-truth, and achieve naturalness scores that match the ground-truth in several languages.
High-precision Voice Search Query Correction via Retrievable Speech-text Embedings
Jan 08, 2024Automatic speech recognition (ASR) systems can suffer from poor recall for various reasons, such as noisy audio, lack of sufficient training data, etc. Previous work has shown that recall can be improved by retrieving rewrite candidates from a large database of likely, contextually-relevant alternatives to the hypothesis text using nearest-neighbors search over embeddings of the ASR hypothesis text to correct and candidate corrections. However, ASR-hypothesis-based retrieval can yield poor precision if the textual hypotheses are too phonetically dissimilar to the transcript truth. In this paper, we eliminate the hypothesis-audio mismatch problem by querying the correction database directly using embeddings derived from the utterance audio; the embeddings of the utterance audio and candidate corrections are produced by multimodal speech-text embedding networks trained to place the embedding of the audio of an utterance and the embedding of its corresponding textual transcript close together. After locating an appropriate correction candidate using nearest-neighbor search, we score the candidate with its speech-text embedding distance before adding the candidate to the original n-best list. We show a relative word error rate (WER) reduction of 6% on utterances whose transcripts appear in the candidate set, without increasing WER on general utterances.
Understanding Shared Speech-Text Representations
Apr 27, 2023Recently, a number of approaches to train speech models by incorpo-rating text into end-to-end models have been developed, with Mae-stro advancing state-of-the-art automatic speech recognition (ASR)and Speech Translation (ST) performance. In this paper, we expandour understanding of the resulting shared speech-text representationswith two types of analyses. First we examine the limits of speech-free domain adaptation, finding that a corpus-specific duration modelfor speech-text alignment is the most important component for learn-ing a shared speech-text representation. Second, we inspect the sim-ilarities between activations of unimodal (speech or text) encodersas compared to the activations of a shared encoder. We find that theshared encoder learns a more compact and overlapping speech-textrepresentation than the uni-modal encoders. We hypothesize that thispartially explains the effectiveness of the Maestro shared speech-textrepresentations.
R-MelNet: Reduced Mel-Spectral Modeling for Neural TTS
Jun 30, 2022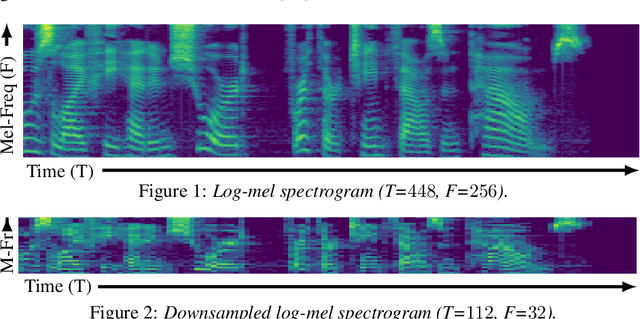
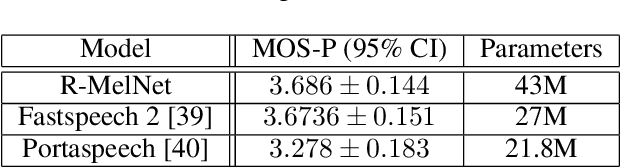
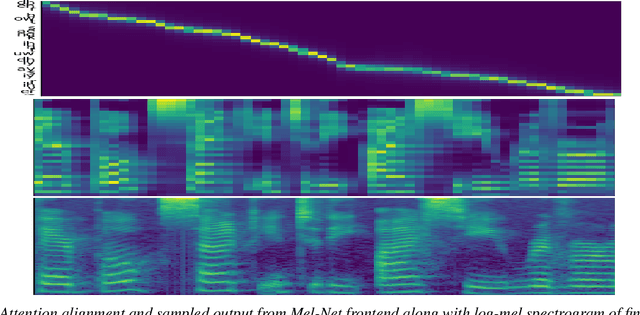

This paper introduces R-MelNet, a two-part autoregressive architecture with a frontend based on the first tier of MelNet and a backend WaveRNN-style audio decoder for neural text-to-speech synthesis. Taking as input a mixed sequence of characters and phonemes, with an optional audio priming sequence, this model produces low-resolution mel-spectral features which are interpolated and used by a WaveRNN decoder to produce an audio waveform. Coupled with half precision training, R-MelNet uses under 11 gigabytes of GPU memory on a single commodity GPU (NVIDIA 2080Ti). We detail a number of critical implementation details for stable half precision training, including an approximate, numerically stable mixture of logistics attention. Using a stochastic, multi-sample per step inference scheme, the resulting model generates highly varied audio, while enabling text and audio based controls to modify output waveforms. Qualitative and quantitative evaluations of an R-MelNet system trained on a single speaker TTS dataset demonstrate the effectiveness of our approach.
MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling
Dec 17, 2021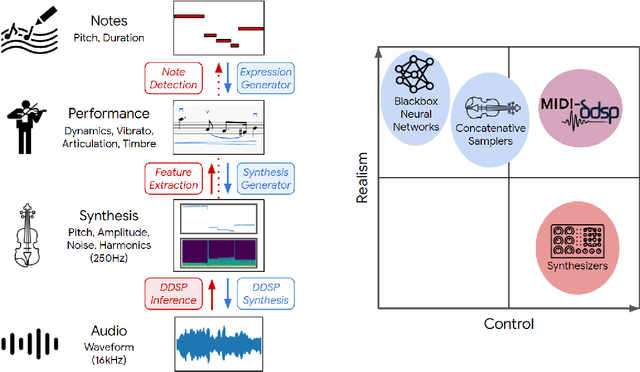
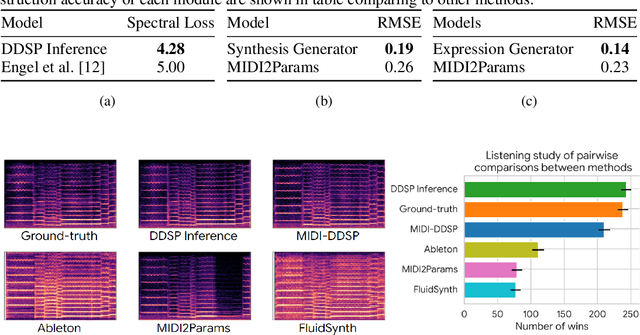
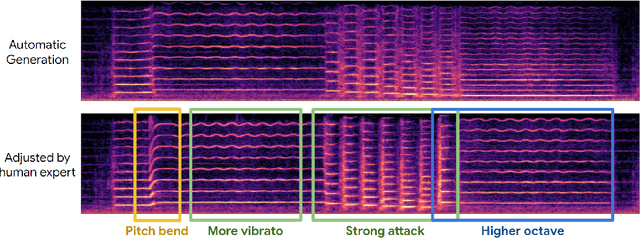
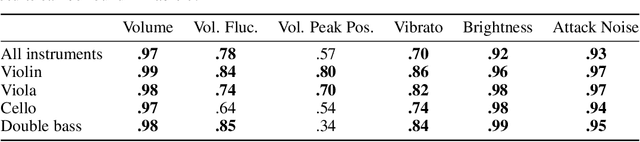
Musical expression requires control of both what notes are played, and how they are performed. Conventional audio synthesizers provide detailed expressive controls, but at the cost of realism. Black-box neural audio synthesis and concatenative samplers can produce realistic audio, but have few mechanisms for control. In this work, we introduce MIDI-DDSP a hierarchical model of musical instruments that enables both realistic neural audio synthesis and detailed user control. Starting from interpretable Differentiable Digital Signal Processing (DDSP) synthesis parameters, we infer musical notes and high-level properties of their expressive performance (such as timbre, vibrato, dynamics, and articulation). This creates a 3-level hierarchy (notes, performance, synthesis) that affords individuals the option to intervene at each level, or utilize trained priors (performance given notes, synthesis given performance) for creative assistance. Through quantitative experiments and listening tests, we demonstrate that this hierarchy can reconstruct high-fidelity audio, accurately predict performance attributes for a note sequence, independently manipulate the attributes of a given performance, and as a complete system, generate realistic audio from a novel note sequence. By utilizing an interpretable hierarchy, with multiple levels of granularity, MIDI-DDSP opens the door to assistive tools to empower individuals across a diverse range of musical experience.
Planning in Dynamic Environments with Conditional Autoregressive Models
Nov 25, 2018

We demonstrate the use of conditional autoregressive generative models (van den Oord et al., 2016a) over a discrete latent space (van den Oord et al., 2017b) for forward planning with MCTS. In order to test this method, we introduce a new environment featuring varying difficulty levels, along with moving goals and obstacles. The combination of high-quality frame generation and classical planning approaches nearly matches true environment performance for our task, demonstrating the usefulness of this method for model-based planning in dynamic environments.