 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Item Tokenization for Transferable Generative Recommendation
Apr 06, 2025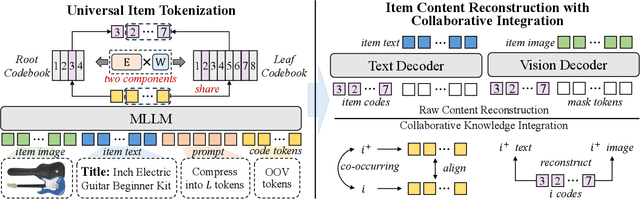
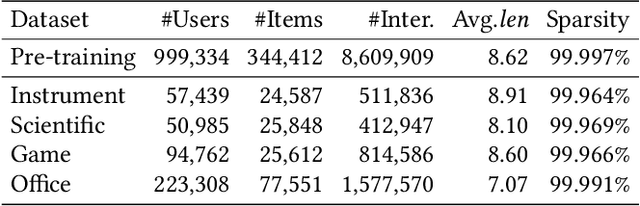
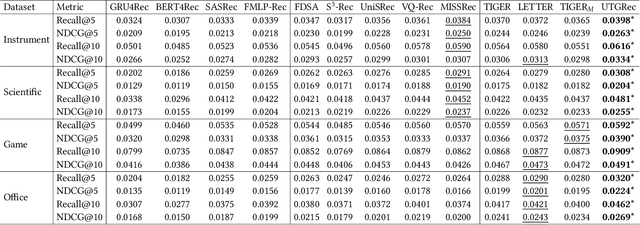
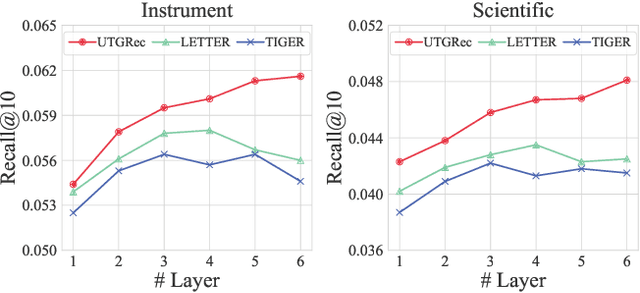
Recently, generative recommendation has emerged as a promising paradigm, attracting significant research attention. The basic framework involves an item tokenizer, which represents each item as a sequence of codes serving as its identifier, and a generative recommender that predicts the next item by autoregressively generating the target item identifier. However, in existing methods, both the tokenizer and the recommender are typically domain-specific, limiting their ability for effective transfer or adaptation to new domains. To this end, we propose UTGRec, a Universal item Tokenization approach for transferable Generative Recommendation. Specifically, we design a universal item tokenizer for encoding rich item semantics by adapting a multimodal large language model (MLLM). By devising tree-structured codebooks, we discretize content representations into corresponding codes for item tokenization. To effectively learn the universal item tokenizer on multiple domains, we introduce two key techniques in our approach. For raw content reconstruction, we employ dual lightweight decoders to reconstruct item text and images from discrete representations to capture general knowledge embedded in the content. For collaborative knowledge integration, we assume that co-occurring items are similar and integrate collaborative signals through co-occurrence alignment and reconstruction. Finally, we present a joint learning framework to pre-train and adapt the transferable generative recommender across multiple domains. Extensive experiments on four public datasets demonstrate the superiority of UTGRec compared to both traditional and generative recommendation baselines.
CSF: Fixed-outline Floorplanning Based on the Conjugate Subgradient Algorithm Assisted by Q-Learning
Apr 04, 2025To perform the fixed-outline floorplanning problem efficiently, we propose to solve the original nonsmooth analytic optimization model via the conjugate subgradient algorithm (CSA), which is further accelerated by adaptively regulating the step size with the assistance of Q-learning. The objective for global floorplanning is a weighted sum of the half-perimeter wirelength, the overlapping area and the out-of-bound width, and the legalization is implemented by optimizing the weighted sum of the overlapping area and the out-of-bound width. Meanwhile, we also propose two improved variants for the legalizaiton algorithm based on constraint graphs (CGs). Experimental results demonstrate that the CSA assisted by Q-learning (CSAQ) can address both global floorplanning and legalization efficiently, and the two stages jointly contribute to competitive results on the optimization of wirelength. Meanwhile, the improved CG-based legalization methods also outperforms the original one in terms of runtime and success rate.
MSSFC-Net:Enhancing Building Interpretation with Multi-Scale Spatial-Spectral Feature Collaboration
Apr 01, 2025



Building interpretation from remote sensing imagery primarily involves two fundamental tasks: building extraction and change detection. However, most existing methods address these tasks independently, overlooking their inherent correlation and failing to exploit shared feature representations for mutual enhancement. Furthermore, the diverse spectral,spatial, and scale characteristics of buildings pose additional challenges in jointly modeling spatial-spectral multi-scale features and effectively balancing precision and recall. The limited synergy between spatial and spectral representations often results in reduced detection accuracy and incomplete change localization.To address these challenges, we propose a Multi-Scale Spatial-Spectral Feature Cooperative Dual-Task Network (MSSFC-Net) for joint building extraction and change detection in remote sensing images. The framework integrates both tasks within a unified architecture, leveraging their complementary nature to simultaneously extract building and change features. Specifically,a Dual-branch Multi-scale Feature Extraction module (DMFE) with Spatial-Spectral Feature Collaboration (SSFC) is designed to enhance multi-scale representation learning, effectively capturing shallow texture details and deep semantic information, thus improving building extraction performance. For temporal feature aggregation, we introduce a Multi-scale Differential Fusion Module (MDFM) that explicitly models the interaction between differential and dual-temporal features. This module refines the network's capability to detect large-area changes and subtle structural variations in buildings. Extensive experiments conducted on three benchmark datasets demonstrate that MSSFC-Net achieves superior performance in both building extraction and change detection tasks, effectively improving detection accuracy while maintaining completeness.
Derivation and analysis of power offset in fiber-longitudinal power profile estimation using pre-FEC hard-decision data
Mar 26, 2025Utilizing the precise reference waveform regenerated by post-forward error correction (FEC) data, the fiber-longitudinal power profile estimation based on the minimum-mean-square-error method (MMSE-PPE) has been validated as an effective tool for absolute power monitoring. However, when post-FEC data is unavailable, it becomes necessary to rely on pre-FEC hard-decision data, which inevitably introduces hard-decision errors. These hard-decision errors will result in a power offset that undermines the accuracy of absolute power monitoring. In this paper, we present the first analytical expression for power offset in MMSE-PPE when using pre-FEC hard-decision data, achieved by introducing a virtual hard-decision nonlinear perturbation term. Based on this analytical expression, we also establish the first nonlinear relationship between the power offset and the symbol error rate (SER) of M-ary quadrature amplitude modulation (M-QAM) formats based on Gaussian assumptions. Verified in a numerical 130-GBaud single-wavelength coherent optical fiber transmission system, the correctness of the analytical expression of power offset has been confirmed with 4-QAM, 16-QAM, and 64-QAM formats under different SER situations. Furthermore, the nonlinear relationship between the power offset and SER of $M$-QAM formats has also been thoroughly validated under both linear scale (measured in mW) and logarithmic scale (measured in dB). These theoretical insights offer significant contributions to the design of potential power offset mitigation strategies in MMSE-PPE, thereby enhancing its real-time application.
SharedAssembly: A Data Collection Approach via Shared Tele-Assembly
Mar 15, 2025Assembly is a fundamental skill for robots in both modern manufacturing and service robotics. Existing datasets aim to address the data bottleneck in training general-purpose robot models, falling short of capturing contact-rich assembly tasks. To bridge this gap, we introduce SharedAssembly, a novel bilateral teleoperation approach with shared autonomy for scalable assembly execution and data collection. User studies demonstrate that the proposed approach enhances both success rates and efficiency, achieving a 97.0% success rate across various sub-millimeter-level assembly tasks. Notably, novice and intermediate users achieve performance comparable to experts using baseline teleoperation methods, significantly enhancing large-scale data collection.
Continuous K-Max Bandits
Feb 19, 2025We study the $K$-Max combinatorial multi-armed bandits problem with continuous outcome distributions and weak value-index feedback: each base arm has an unknown continuous outcome distribution, and in each round the learning agent selects $K$ arms, obtains the maximum value sampled from these $K$ arms as reward and observes this reward together with the corresponding arm index as feedback. This setting captures critical applications in recommendation systems, distributed computing, server scheduling, etc. The continuous $K$-Max bandits introduce unique challenges, including discretization error from continuous-to-discrete conversion, non-deterministic tie-breaking under limited feedback, and biased estimation due to partial observability. Our key contribution is the computationally efficient algorithm DCK-UCB, which combines adaptive discretization with bias-corrected confidence bounds to tackle these challenges. For general continuous distributions, we prove that DCK-UCB achieves a $\widetilde{\mathcal{O}}(T^{3/4})$ regret upper bound, establishing the first sublinear regret guarantee for this setting. Furthermore, we identify an important special case with exponential distributions under full-bandit feedback. In this case, our proposed algorithm MLE-Exp enables $\widetilde{\mathcal{O}}(\sqrt{T})$ regret upper bound through maximal log-likelihood estimation, achieving near-minimax optimality.
Finite-Time Analysis of Discrete-Time Stochastic Interpolants
Feb 13, 2025The stochastic interpolant framework offers a powerful approach for constructing generative models based on ordinary differential equations (ODEs) or stochastic differential equations (SDEs) to transform arbitrary data distributions. However, prior analyses of this framework have primarily focused on the continuous-time setting, assuming a perfect solution of the underlying equations. In this work, we present the first discrete-time analysis of the stochastic interpolant framework, where we introduce an innovative discrete-time sampler and derive a finite-time upper bound on its distribution estimation error. Our result provides a novel quantification of how different factors, including the distance between source and target distributions and estimation accuracy, affect the convergence rate and also offers a new principled way to design efficient schedules for convergence acceleration. Finally, numerical experiments are conducted on the discrete-time sampler to corroborate our theoretical findings.
ATLAS: Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data
Feb 08, 2025Autoformalization, the process of automatically translating natural language mathematics into machine-verifiable formal language, has demonstrated advancements with the progress of large language models (LLMs). However, a key obstacle to further advancements is the scarcity of paired datasets that align natural language with formal language. To address this challenge, we introduce ATLAS (Autoformalizing Theorems through Lifting, Augmentation, and Synthesis of Data), an iterative data generation framework designed to produce large-scale, high-quality parallel theorem statements. With the proposed ATLAS running for 10 iterations, we construct an undergraduate-level dataset comprising 300k theorem statements and develop the ATLAS translator, achieving accuracies of 80.59% (pass@8) and 92.99% (pass@128) on ProofNet, significantly outperforming the base model (23.99% and 47.17%) and InternLM2-Math-Plus-7B (50.94% and 80.32%). Furthermore, the ATLAS translator also achieves state-of-the-art performance on both the high-school-level miniF2F dataset and the graduate-level MathQual dataset introduced in this work. The datasets, model, and code will be released to the public soon.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
Image Quality Assessment: Investigating Causal Perceptual Effects with Abductive Counterfactual Inference
Dec 22, 2024Existing full-reference image quality assessment (FR-IQA) methods often fail to capture the complex causal mechanisms that underlie human perceptual responses to image distortions, limiting their ability to generalize across diverse scenarios. In this paper, we propose an FR-IQA method based on abductive counterfactual inference to investigate the causal relationships between deep network features and perceptual distortions. First, we explore the causal effects of deep features on perception and integrate causal reasoning with feature comparison, constructing a model that effectively handles complex distortion types across different IQA scenarios. Second, the analysis of the perceptual causal correlations of our proposed method is independent of the backbone architecture and thus can be applied to a variety of deep networks. Through abductive counterfactual experiments, we validate the proposed causal relationships, confirming the model's superior perceptual relevance and interpretability of quality scores. The experimental results demonstrate the robustness and effectiveness of the method, providing competitive quality predictions across multiple benchmarks. The source code is available at https://anonymous.4open.science/r/DeepCausalQuality-25BC.