 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal2Local: A Joint-Hierarchical Attention for Video Captioning
Mar 13, 2022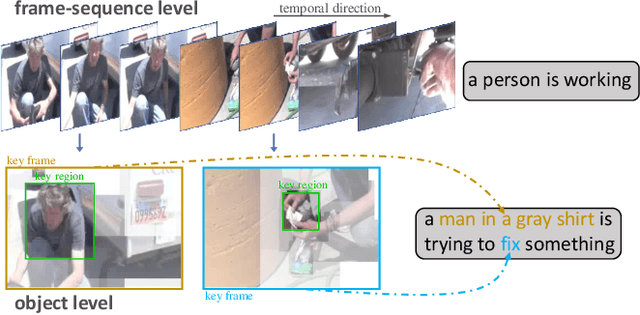
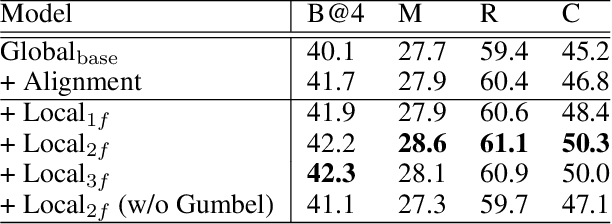
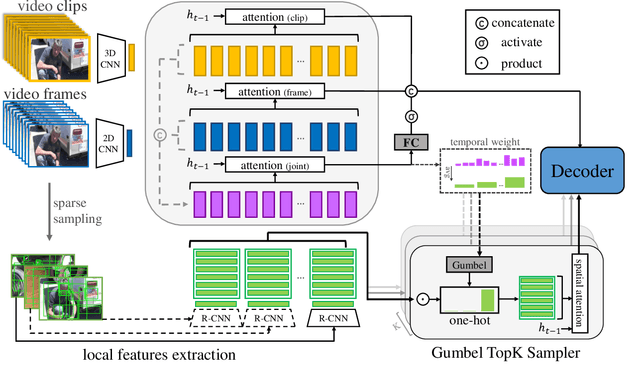
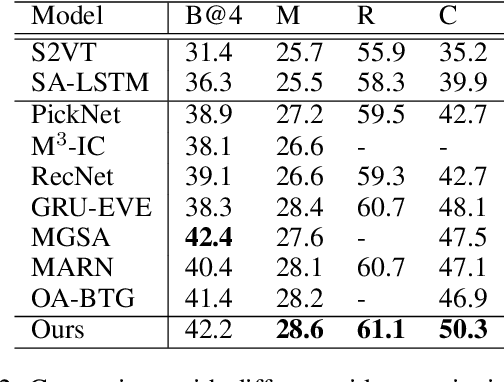
Recently, automatic video captioning has attracted increasing attention, where the core challenge lies in capturing the key semantic items, like objects and actions as well as their spatial-temporal correlations from the redundant frames and semantic content. To this end, existing works select either the key video clips in a global level~(across multi frames), or key regions within each frame, which, however, neglect the hierarchical order, i.e., key frames first and key regions latter. In this paper, we propose a novel joint-hierarchical attention model for video captioning, which embeds the key clips, the key frames and the key regions jointly into the captioning model in a hierarchical manner. Such a joint-hierarchical attention model first conducts a global selection to identify key frames, followed by a Gumbel sampling operation to identify further key regions based on the key frames, achieving an accurate global-to-local feature representation to guide the captioning. Extensive quantitative evaluations on two public benchmark datasets MSVD and MSR-VTT demonstrates the superiority of the proposed method over the state-of-the-art methods.
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022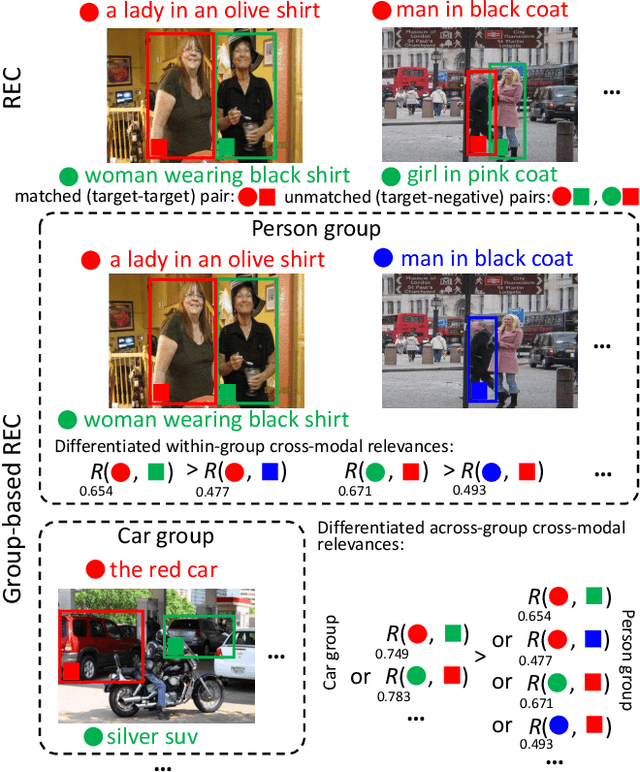
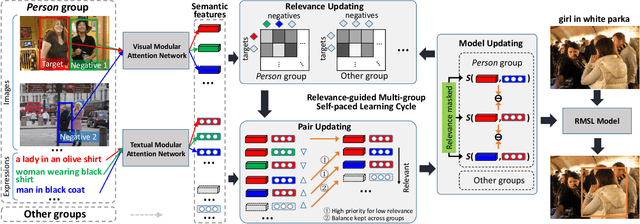

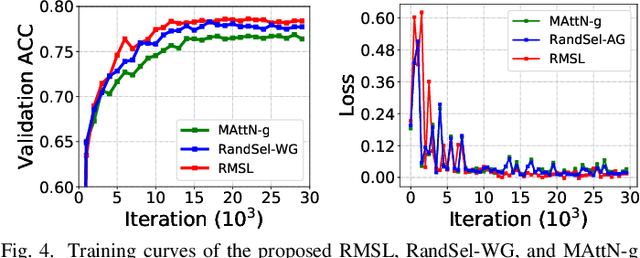
Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
Dynamic Dual Trainable Bounds for Ultra-low Precision Super-Resolution Networks
Mar 10, 2022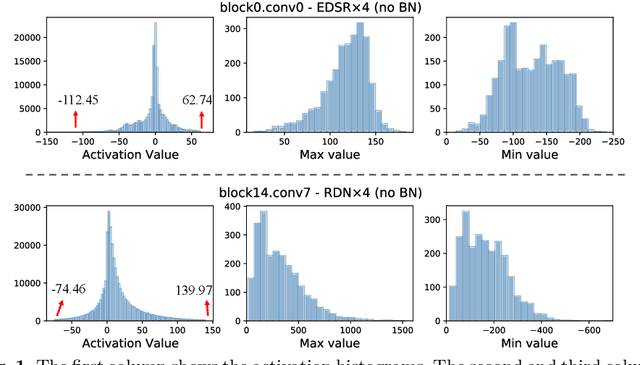
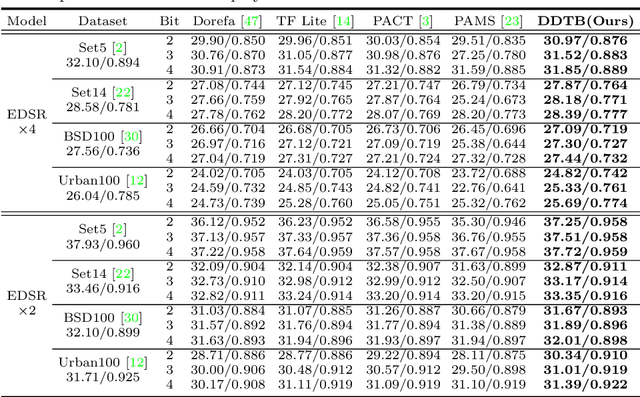
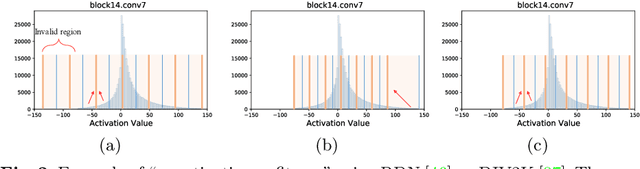
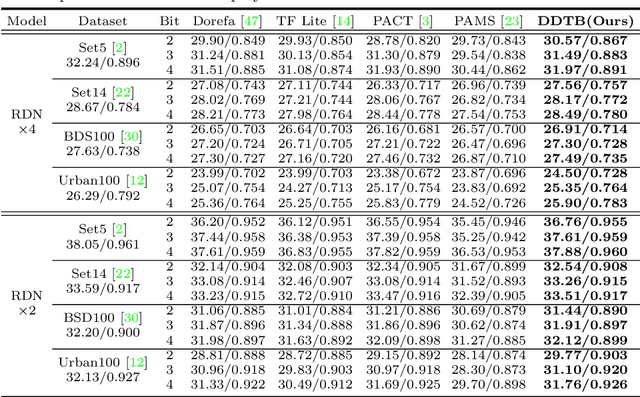
Light-weight super-resolution (SR) models have received considerable attention for their serviceability in mobile devices. Many efforts employ network quantization to compress SR models. However, these methods suffer from severe performance degradation when quantizing the SR models to ultra-low precision (e.g., 2-bit and 3-bit) with the low-cost layer-wise quantizer. In this paper, we identify that the performance drop comes from the contradiction between the layer-wise symmetric quantizer and the highly asymmetric activation distribution in SR models. This discrepancy leads to either a waste on the quantization levels or detail loss in reconstructed images. Therefore, we propose a novel activation quantizer, referred to as Dynamic Dual Trainable Bounds (DDTB), to accommodate the asymmetry of the activations. Specifically, DDTB innovates in: 1) A layer-wise quantizer with trainable upper and lower bounds to tackle the highly asymmetric activations. 2) A dynamic gate controller to adaptively adjust the upper and lower bounds at runtime to overcome the drastically varying activation ranges over different samples.To reduce the extra overhead, the dynamic gate controller is quantized to 2-bit and applied to only part of the SR networks according to the introduced dynamic intensity. Extensive experiments demonstrate that our DDTB exhibits significant performance improvements in ultra-low precision. For example, our DDTB achieves a 0.70dB PSNR increase on Urban100 benchmark when quantizing EDSR to 2-bit and scaling up output images to x4. Code is at \url{https://github.com/zysxmu/DDTB}.
Coarse-to-Fine Vision Transformer
Mar 08, 2022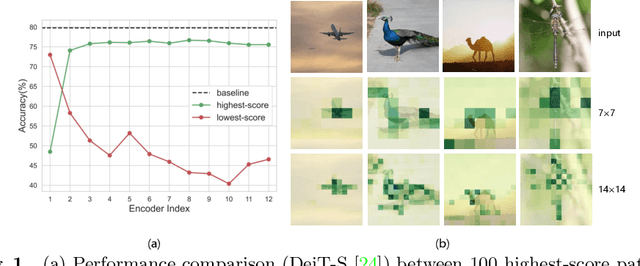
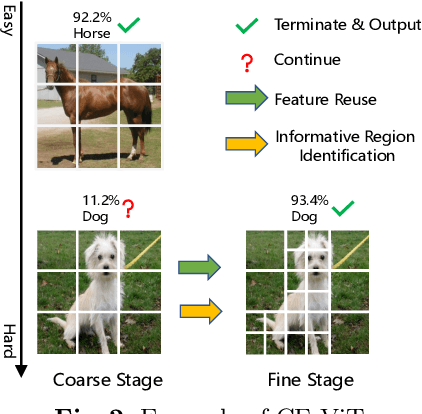
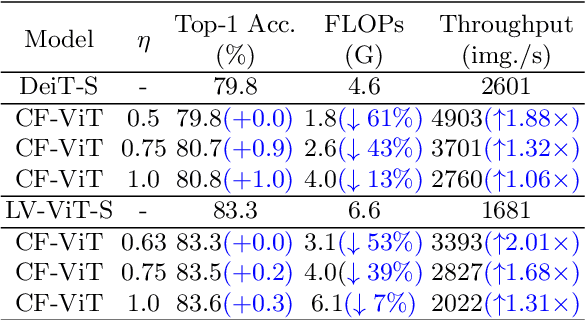
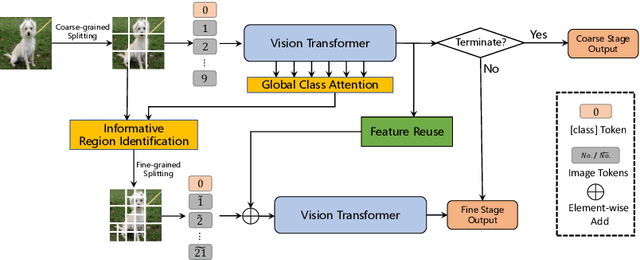
Vision Transformers (ViT) have made many breakthroughs in computer vision tasks. However, considerable redundancy arises in the spatial dimension of an input image, leading to massive computational costs. Therefore, We propose a coarse-to-fine vision transformer (CF-ViT) to relieve computational burden while retaining performance in this paper. Our proposed CF-ViT is motivated by two important observations in modern ViT models: (1) The coarse-grained patch splitting can locate informative regions of an input image. (2) Most images can be well recognized by a ViT model in a small-length token sequence. Therefore, our CF-ViT implements network inference in a two-stage manner. At coarse inference stage, an input image is split into a small-length patch sequence for a computationally economical classification. If not well recognized, the informative patches are identified and further re-split in a fine-grained granularity. Extensive experiments demonstrate the efficacy of our CF-ViT. For example, without any compromise on performance, CF-ViT reduces 53% FLOPs of LV-ViT, and also achieves 2.01x throughput.
Optimizing Gradient-driven Criteria in Network Sparsity: Gradient is All You Need
Jan 30, 2022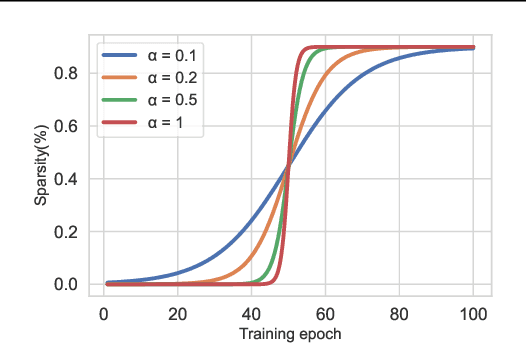
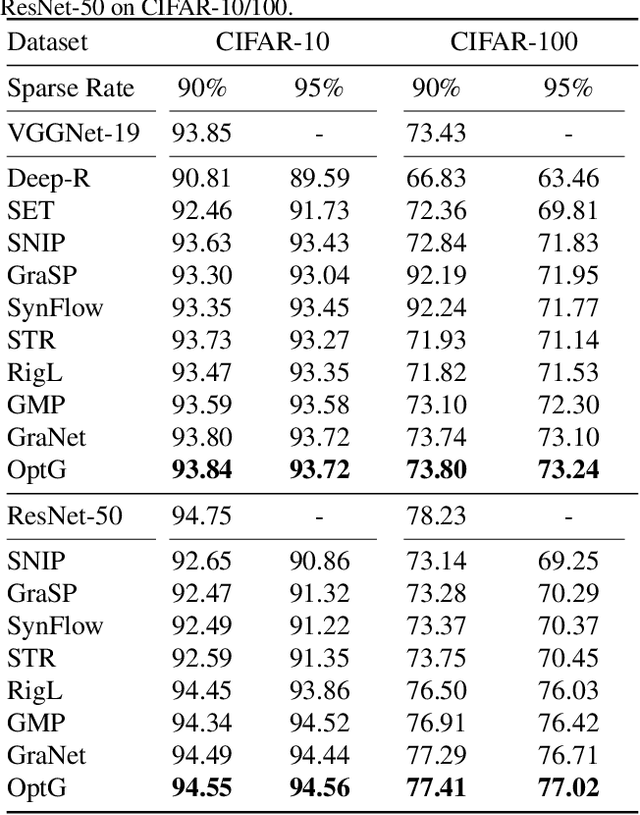
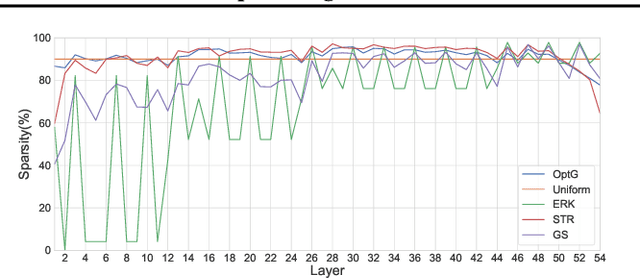
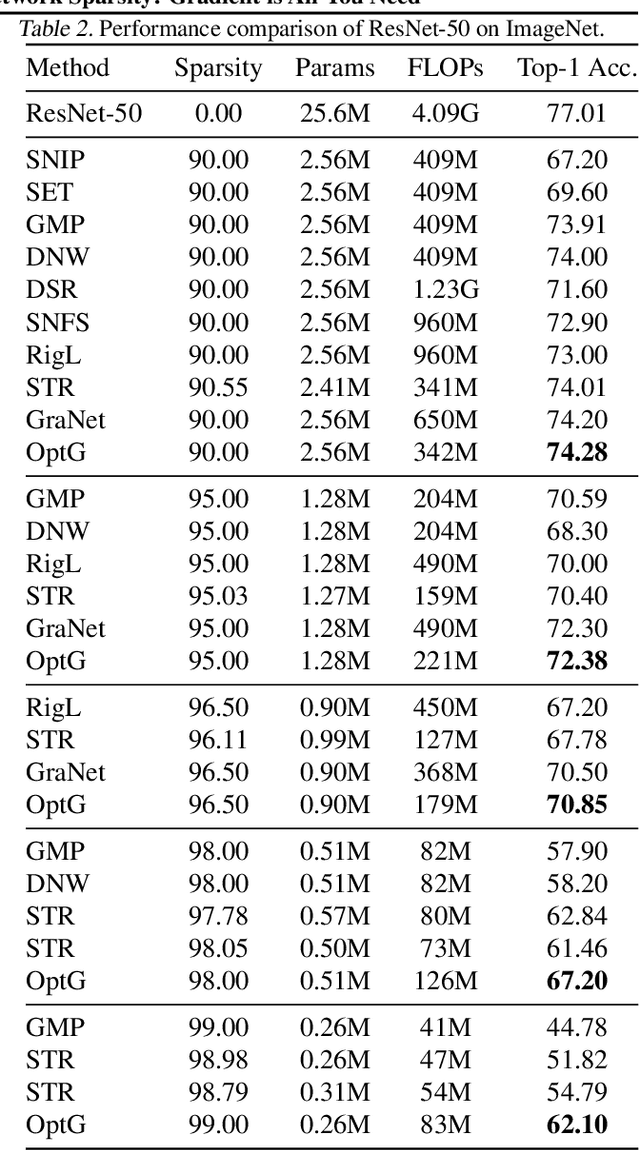
Network sparsity receives popularity mostly due to its capability to reduce the network complexity. Extensive studies excavate gradient-driven sparsity. Typically, these methods are constructed upon premise of weight independence, which however, is contrary to the fact that weights are mutually influenced. Thus, their performance remains to be improved. In this paper, we propose to further optimize gradient-driven sparsity (OptG) by solving this independence paradox. Our motive comes from the recent advances on supermask training which shows that sparse subnetworks can be located in a randomly initialized network by simply updating mask values without modifying any weight. We prove that supermask training is to accumulate the weight gradients and can partly solve the independence paradox. Consequently, OptG integrates supermask training into gradient-driven sparsity, and a specialized mask optimizer is designed to solve the independence paradox. Experiments show that OptG can well surpass many existing state-of-the-art competitors. Our code is available at \url{https://github.com/zyxxmu/OptG}.
Towards Language-guided Visual Recognition via Dynamic Convolutions
Oct 17, 2021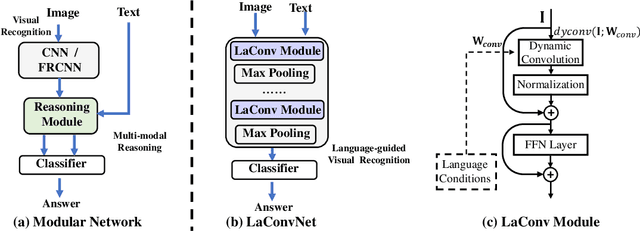
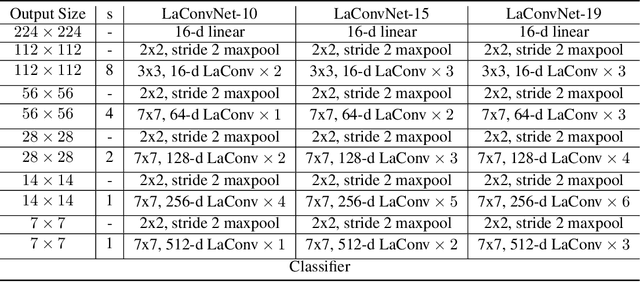
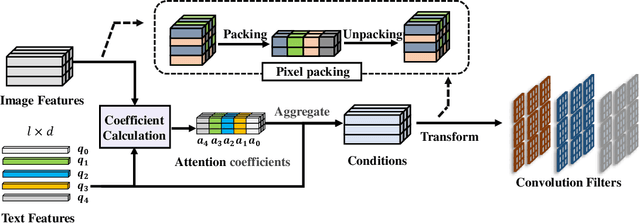
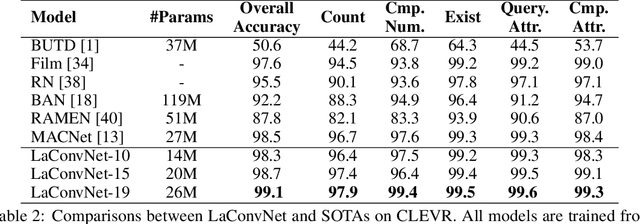
In this paper, we are committed to establishing an unified and end-to-end multi-modal network via exploring the language-guided visual recognition. To approach this target, we first propose a novel multi-modal convolution module called Language-dependent Convolution (LaConv). Its convolution kernels are dynamically generated based on natural language information, which can help extract differentiated visual features for different multi-modal examples. Based on the LaConv module, we further build the first fully language-driven convolution network, termed as LaConvNet, which can unify the visual recognition and multi-modal reasoning in one forward structure. To validate LaConv and LaConvNet, we conduct extensive experiments on four benchmark datasets of two vision-and-language tasks, i.e., visual question answering (VQA) and referring expression comprehension (REC). The experimental results not only shows the performance gains of LaConv compared to the existing multi-modal modules, but also witness the merits of LaConvNet as an unified network, including compact network, high generalization ability and excellent performance, e.g., +4.7% on RefCOCO+.
Fine-grained Data Distribution Alignment for Post-Training Quantization
Sep 09, 2021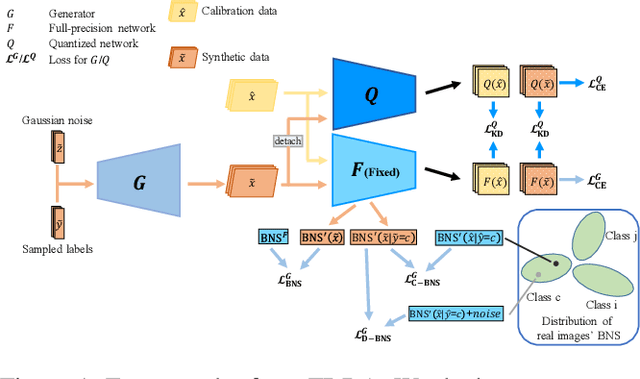
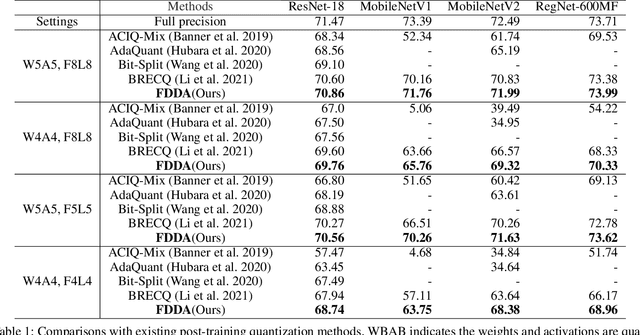

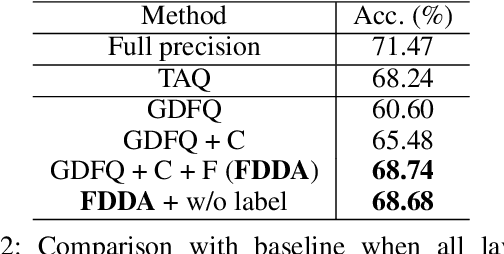
While post-training quantization receives popularity mostly due to its evasion in accessing the original complete training dataset, its poor performance also stems from this limitation. To alleviate this limitation, in this paper, we leverage the synthetic data introduced by zero-shot quantization with calibration dataset and we propose a fine-grained data distribution alignment (FDDA) method to boost the performance of post-training quantization. The method is based on two important properties of batch normalization statistics (BNS) we observed in deep layers of the trained network, i.e., inter-class separation and intra-class incohesion. To preserve this fine-grained distribution information: 1) We calculate the per-class BNS of the calibration dataset as the BNS centers of each class and propose a BNS-centralized loss to force the synthetic data distributions of different classes to be close to their own centers. 2) We add Gaussian noise into the centers to imitate the incohesion and propose a BNS-distorted loss to force the synthetic data distribution of the same class to be close to the distorted centers. By introducing these two fine-grained losses, our method shows the state-of-the-art performance on ImageNet, especially when the first and last layers are quantized to low-bit as well. Our project is available at https://github.com/viperit/FDDA.
HifiFace: 3D Shape and Semantic Prior Guided High Fidelity Face Swapping
Jun 18, 2021
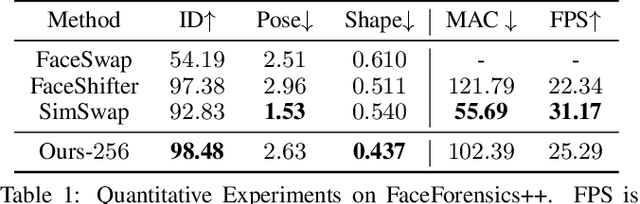
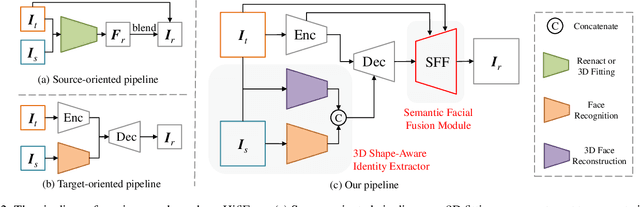
In this work, we propose a high fidelity face swapping method, called HifiFace, which can well preserve the face shape of the source face and generate photo-realistic results. Unlike other existing face swapping works that only use face recognition model to keep the identity similarity, we propose 3D shape-aware identity to control the face shape with the geometric supervision from 3DMM and 3D face reconstruction method. Meanwhile, we introduce the Semantic Facial Fusion module to optimize the combination of encoder and decoder features and make adaptive blending, which makes the results more photo-realistic. Extensive experiments on faces in the wild demonstrate that our method can preserve better identity, especially on the face shape, and can generate more photo-realistic results than previous state-of-the-art methods.
Black-Box Dissector: Towards Erasing-based Hard-Label Model Stealing Attack
May 03, 2021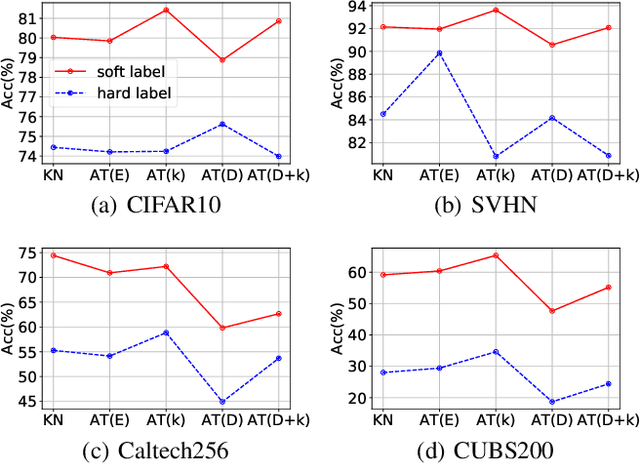
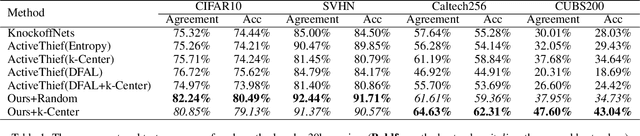
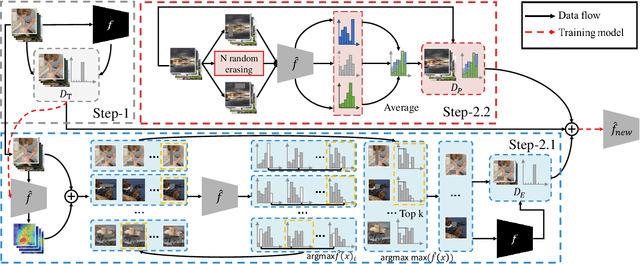
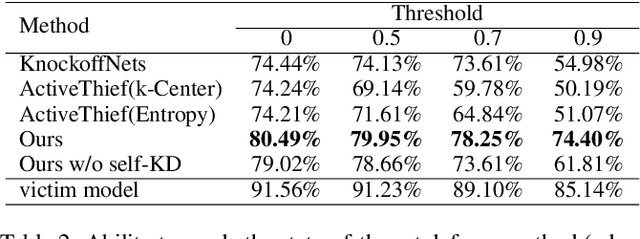
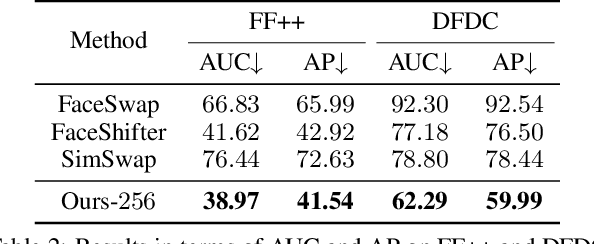
Model stealing attack aims to create a substitute model that steals the ability of the victim target model. However, most of the existing methods depend on the full probability outputs from the victim model, which is unavailable in most realistic scenarios. Focusing on the more practical hard-label setting, due to the lack of rich information in the probability prediction, the existing methods suffer from catastrophic performance degradation. Inspired by knowledge distillation, we propose a novel hard-label model stealing method termed \emph{black-box dissector}, which includes a CAM-driven erasing strategy to mine the hidden information in hard labels from the victim model, and a random-erasing-based self-knowledge distillation module utilizing soft labels from substitute model to avoid overfitting and miscalibration caused by hard labels. Extensive experiments on four widely-used datasets consistently show that our method outperforms state-of-the-art methods, with an improvement of at most $9.92\%$. In addition, experiments on real-world APIs further prove the effectiveness of our method. Our method also can invalidate existing defense methods which further demonstrates the practical potential of our methods.
Carrying out CNN Channel Pruning in a White Box
Apr 24, 2021
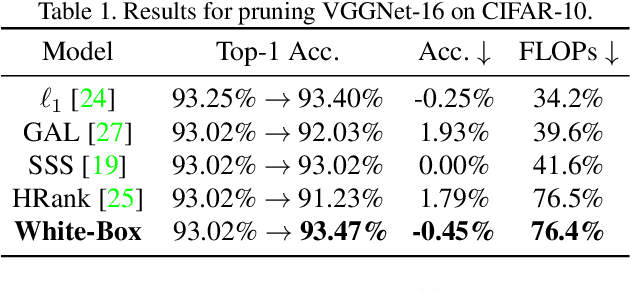
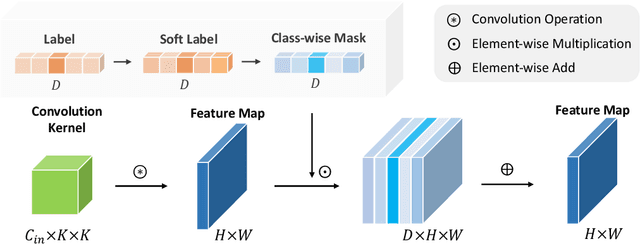
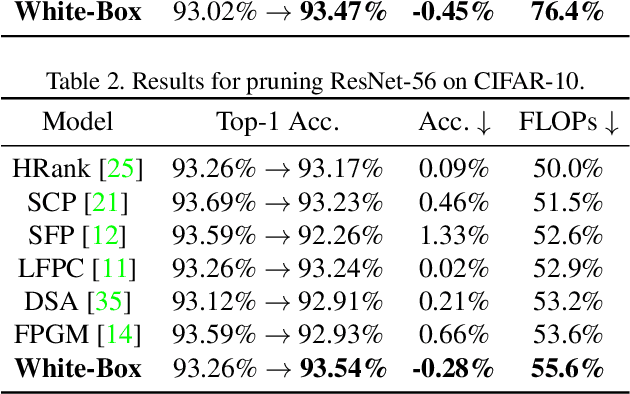
Channel Pruning has been long adopted for compressing CNNs, which significantly reduces the overall computation. Prior works implement channel pruning in an unexplainable manner, which tends to reduce the final classification errors while failing to consider the internal influence of each channel. In this paper, we conduct channel pruning in a white box. Through deep visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we choose to preserve channels contributing to most categories. Specifically, to model the contribution of each channel to differentiating categories, we develop a class-wise mask for each channel, implemented in a dynamic training manner w.r.t. the input image's category. On the basis of the learned class-wise mask, we perform a global voting mechanism to remove channels with less category discrimination. Lastly, a fine-tuning process is conducted to recover the performance of the pruned model. To our best knowledge, it is the first time that CNN interpretability theory is considered to guide channel pruning. Extensive experiments demonstrate the superiority of our White-Box over many state-of-the-arts. For instance, on CIFAR-10, it reduces 65.23% FLOPs with even 0.62% accuracy improvement for ResNet-110. On ILSVRC-2012, White-Box achieves a 45.6% FLOPs reduction with only a small loss of 0.83% in the top-1 accuracy for ResNet-50. Code, training logs and pruned models are anonymously at https://github.com/zyxxmu/White-Box.