 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020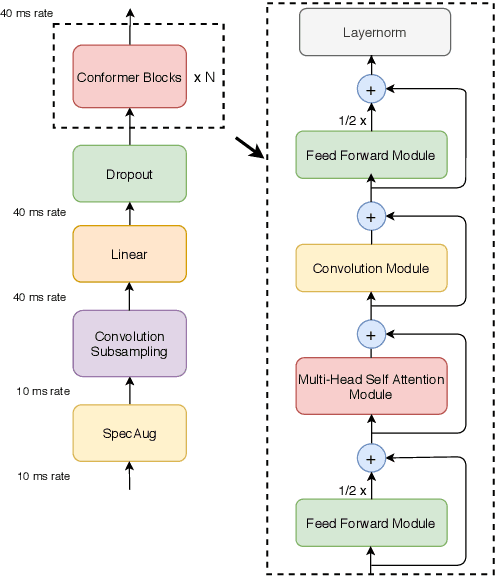
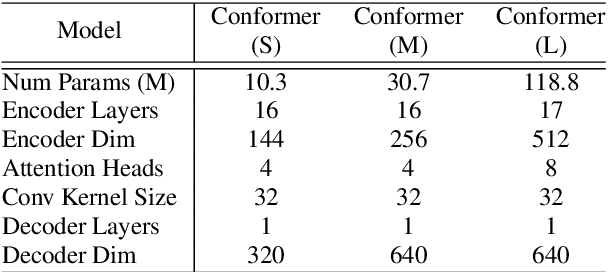

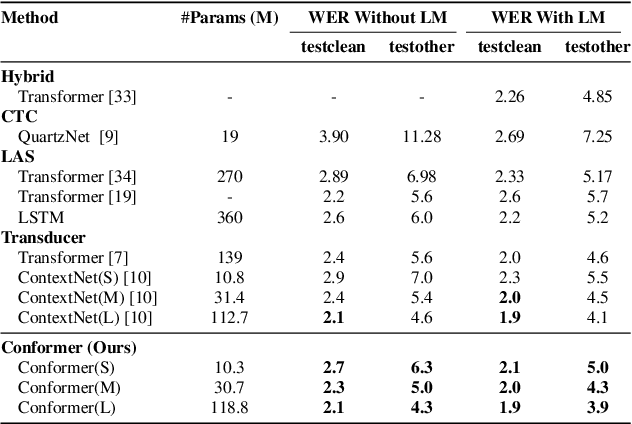
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020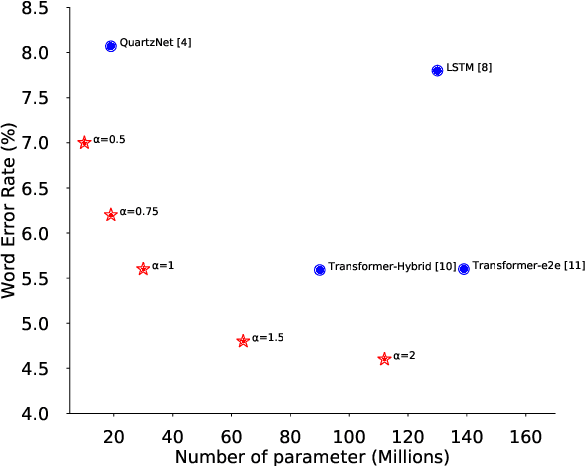
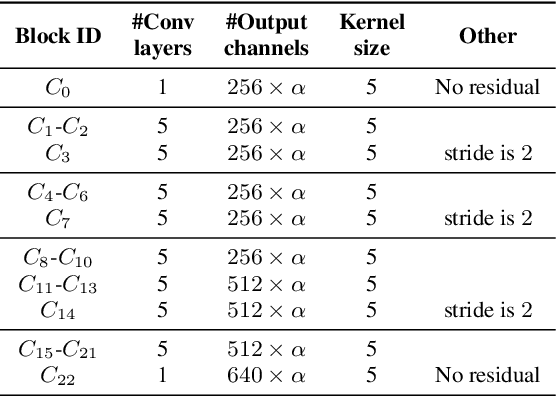
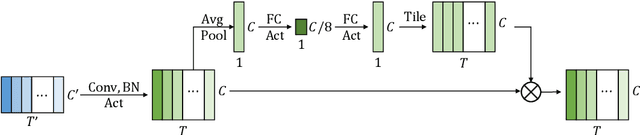
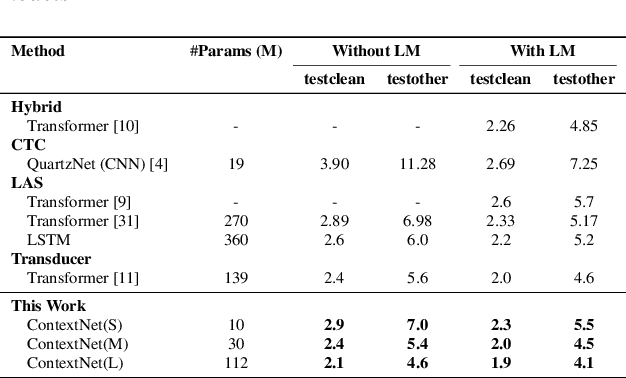
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
Interpretable Learning-to-Rank with Generalized Additive Models
May 14, 2020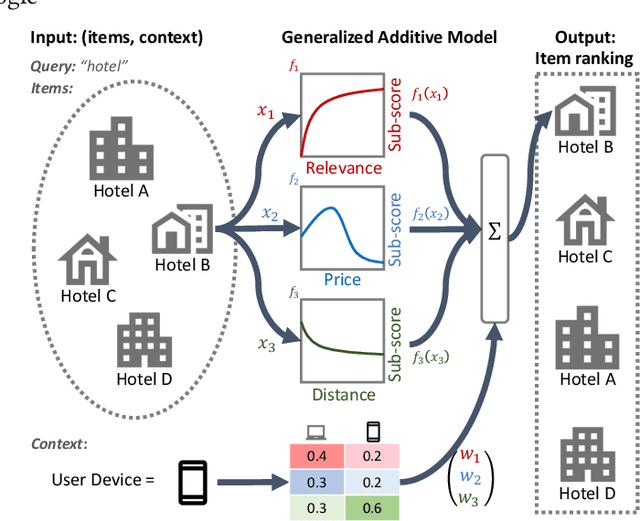

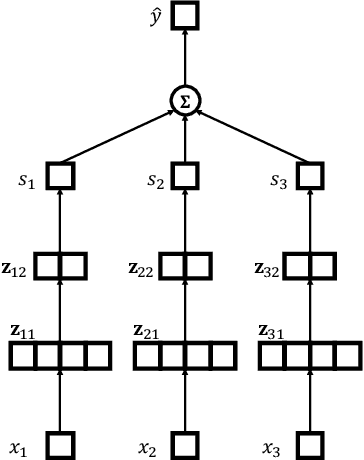
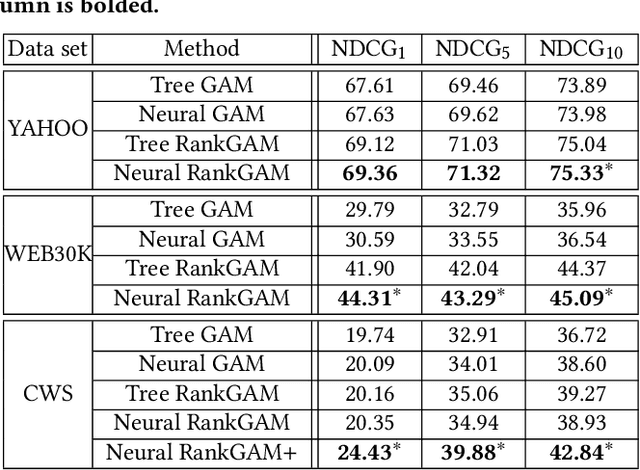
Interpretability of learning-to-rank models is a crucial yet relatively under-examined research area. Recent progress on interpretable ranking models largely focuses on generating post-hoc explanations for existing black-box ranking models, whereas the alternative option of building an intrinsically interpretable ranking model with transparent and self-explainable structure remains unexplored. Developing fully-understandable ranking models is necessary in some scenarios (e.g., due to legal or policy constraints) where post-hoc methods cannot provide sufficiently accurate explanations. In this paper, we lay the groundwork for intrinsically interpretable learning-to-rank by introducing generalized additive models (GAMs) into ranking tasks. Generalized additive models (GAMs) are intrinsically interpretable machine learning models and have been extensively studied on regression and classification tasks. We study how to extend GAMs into ranking models which can handle both item-level and list-level features and propose a novel formulation of ranking GAMs. To instantiate ranking GAMs, we employ neural networks instead of traditional splines or regression trees. We also show that our neural ranking GAMs can be distilled into a set of simple and compact piece-wise linear functions that are much more efficient to evaluate with little accuracy loss. We conduct experiments on three data sets and show that our proposed neural ranking GAMs can achieve significantly better performance than other traditional GAM baselines while maintaining similar interpretability.
Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
May 11, 2020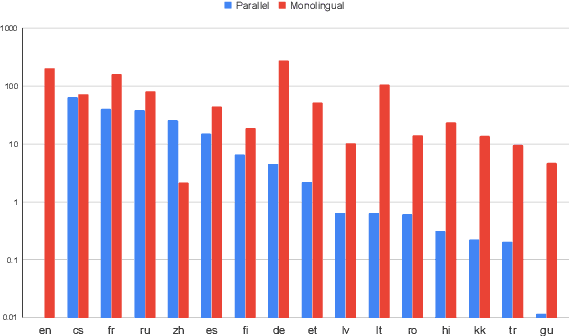

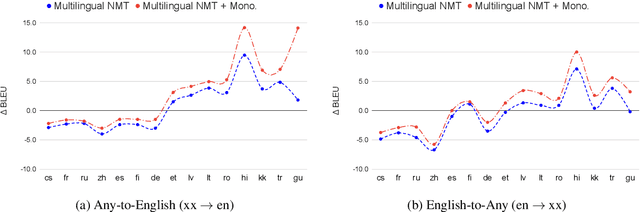
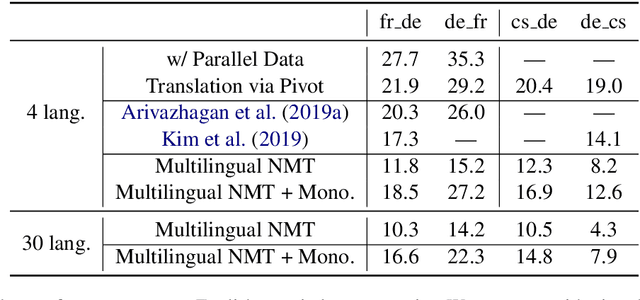
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020
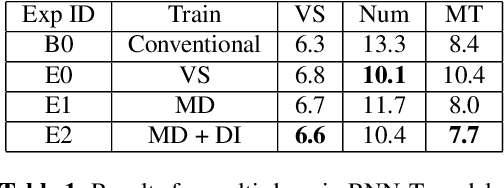
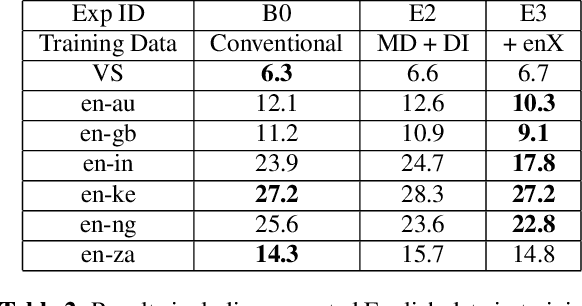
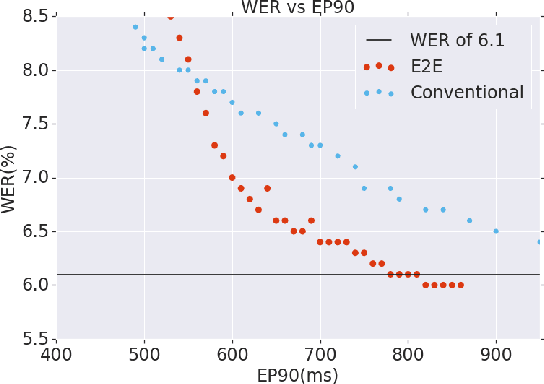
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Fully-hierarchical fine-grained prosody modeling for interpretable speech synthesis
Feb 06, 2020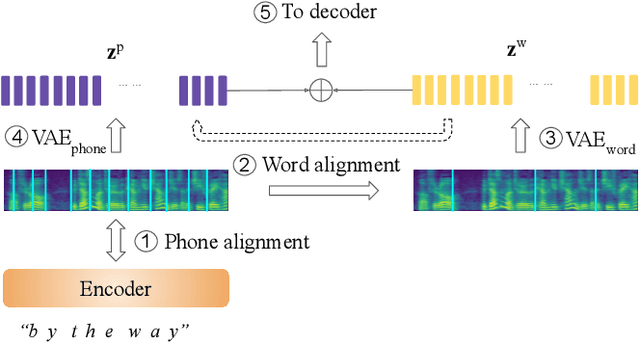
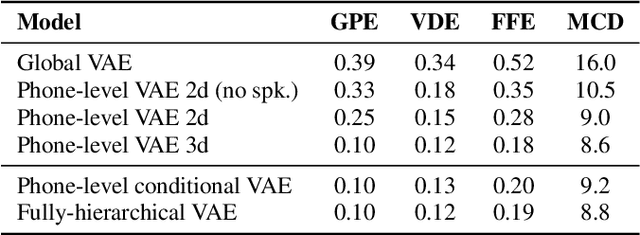
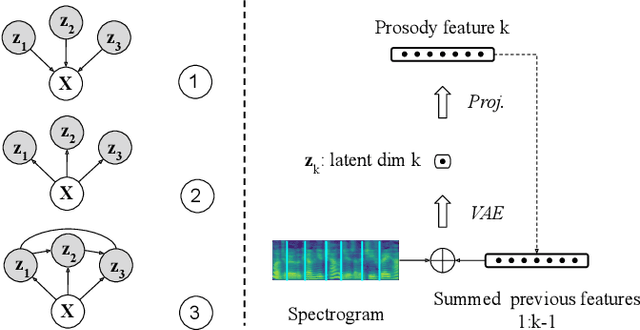
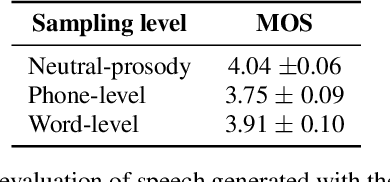
This paper proposes a hierarchical, fine-grained and interpretable latent variable model for prosody based on the Tacotron 2 text-to-speech model. It achieves multi-resolution modeling of prosody by conditioning finer level representations on coarser level ones. Additionally, it imposes hierarchical conditioning across all latent dimensions using a conditional variational auto-encoder (VAE) with an auto-regressive structure. Evaluation of reconstruction performance illustrates that the new structure does not degrade the model while allowing better interpretability. Interpretations of prosody attributes are provided together with the comparison between word-level and phone-level prosody representations. Moreover, both qualitative and quantitative evaluations are used to demonstrate the improvement in the disentanglement of the latent dimensions.
Generating diverse and natural text-to-speech samples using a quantized fine-grained VAE and auto-regressive prosody prior
Feb 06, 2020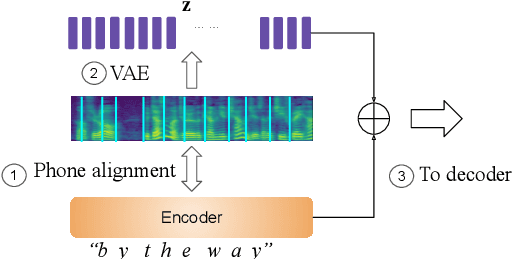
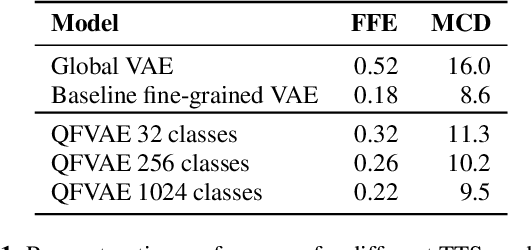
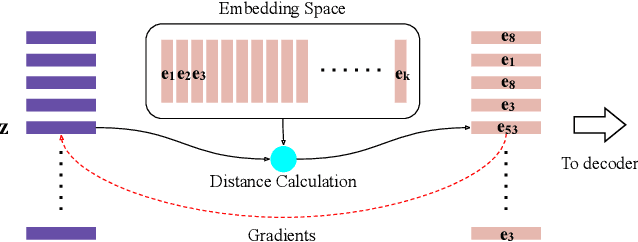
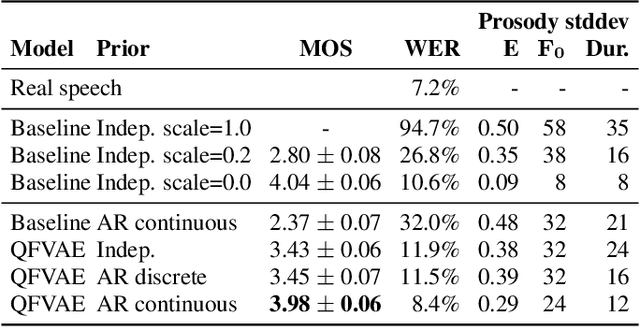
Recent neural text-to-speech (TTS) models with fine-grained latent features enable precise control of the prosody of synthesized speech. Such models typically incorporate a fine-grained variational autoencoder (VAE) structure, extracting latent features at each input token (e.g., phonemes). However, generating samples with the standard VAE prior often results in unnatural and discontinuous speech, with dramatic prosodic variation between tokens. This paper proposes a sequential prior in a discrete latent space which can generate more naturally sounding samples. This is accomplished by discretizing the latent features using vector quantization (VQ), and separately training an autoregressive (AR) prior model over the result. We evaluate the approach using listening tests, objective metrics of automatic speech recognition (ASR) performance, and measurements of prosody attributes. Experimental results show that the proposed model significantly improves the naturalness in random sample generation. Furthermore, initial experiments demonstrate that randomly sampling from the proposed model can be used as data augmentation to improve the ASR performance.
SpecAugment on Large Scale Datasets
Dec 11, 2019
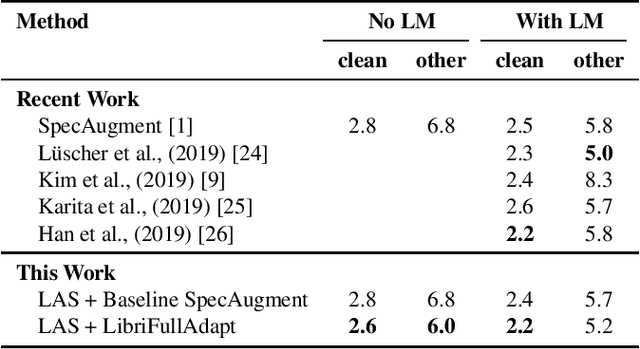
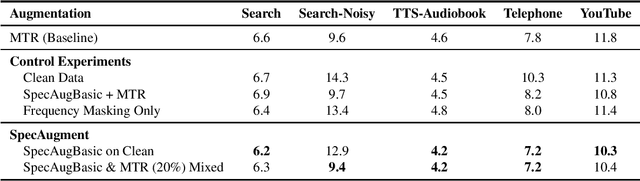
Recently, SpecAugment, an augmentation scheme for automatic speech recognition that acts directly on the spectrogram of input utterances, has shown to be highly effective in enhancing the performance of end-to-end networks on public datasets. In this paper, we demonstrate its effectiveness on tasks with large scale datasets by investigating its application to the Google Multidomain Dataset (Narayanan et al., 2018). We achieve improvement across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model. We also introduce a modification of SpecAugment that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks. By using adaptive masking, we are able to further improve the performance of the Listen, Attend and Spell model on LibriSpeech to 2.2% WER on test-clean and 5.2% WER on test-other.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019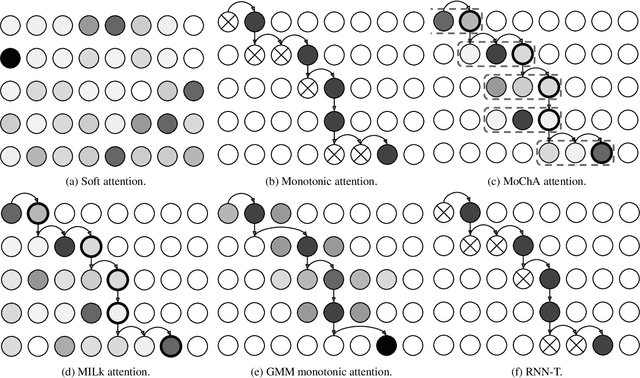

End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
Identifying Cancer Patients at Risk for Heart Failure Using Machine Learning Methods
Oct 01, 2019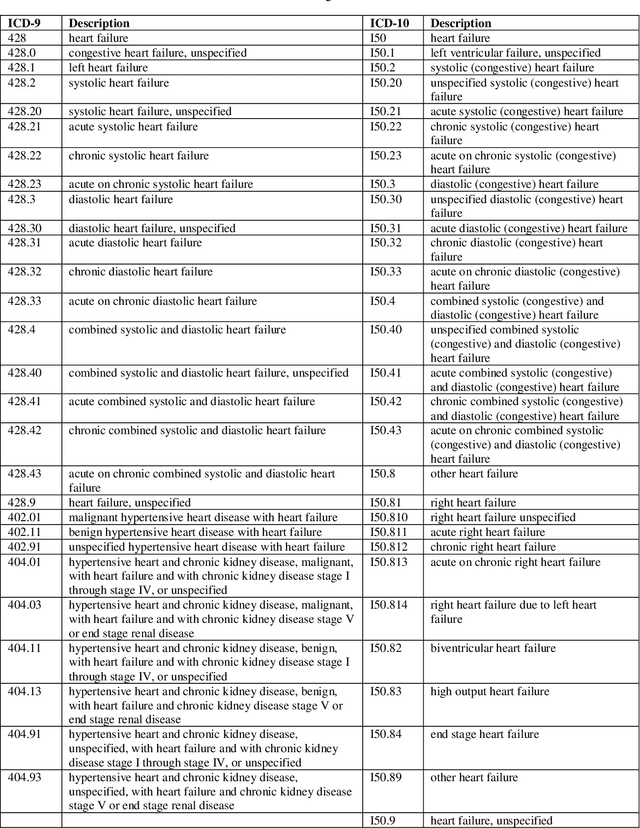
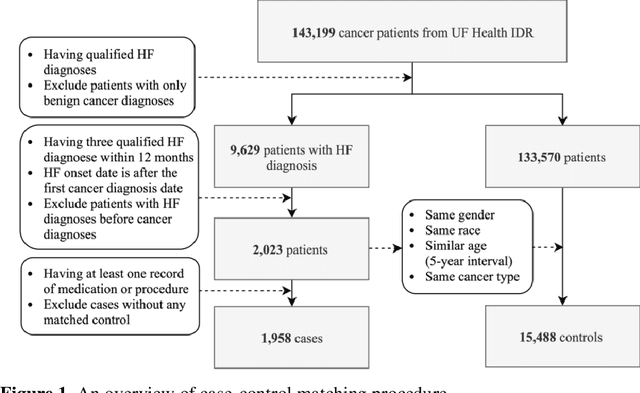
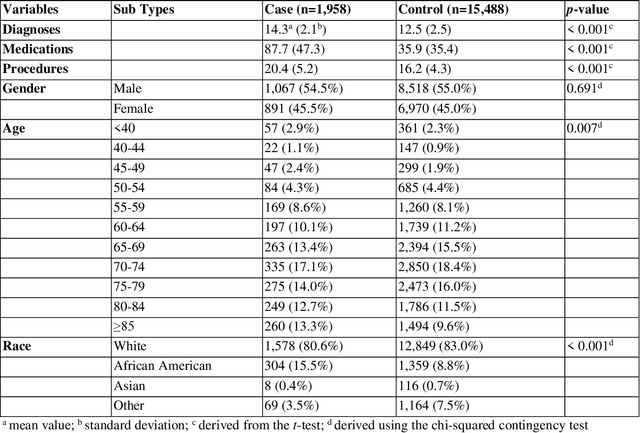
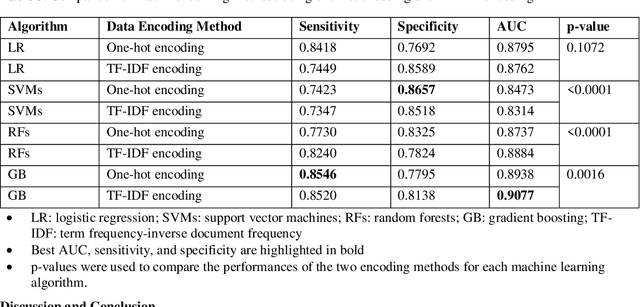
Cardiotoxicity related to cancer therapies has become a serious issue, diminishing cancer treatment outcomes and quality of life. Early detection of cancer patients at risk for cardiotoxicity before cardiotoxic treatments and providing preventive measures are potential solutions to improve cancer patients's quality of life. This study focuses on predicting the development of heart failure in cancer patients after cancer diagnoses using historical electronic health record (EHR) data. We examined four machine learning algorithms using 143,199 cancer patients from the University of Florida Health (UF Health) Integrated Data Repository (IDR). We identified a total number of 1,958 qualified cases and matched them to 15,488 controls by gender, age, race, and major cancer type. Two feature encoding strategies were compared to encode variables as machine learning features. The gradient boosting (GB) based model achieved the best AUC score of 0.9077 (with a sensitivity of 0.8520 and a specificity of 0.8138), outperforming other machine learning methods. We also looked into the subgroup of cancer patients with exposure to chemotherapy drugs and observed a lower specificity score (0.7089). The experimental results show that machine learning methods are able to capture clinical factors that are known to be associated with heart failure and that it is feasible to use machine learning methods to identify cancer patients at risk for cancer therapy-related heart failure.