 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan DeepFake Speech be Reliably Detected?
Oct 09, 2024



Recent advances in text-to-speech (TTS) systems, particularly those with voice cloning capabilities, have made voice impersonation readily accessible, raising ethical and legal concerns due to potential misuse for malicious activities like misinformation campaigns and fraud. While synthetic speech detectors (SSDs) exist to combat this, they are vulnerable to ``test domain shift", exhibiting decreased performance when audio is altered through transcoding, playback, or background noise. This vulnerability is further exacerbated by deliberate manipulation of synthetic speech aimed at deceiving detectors. This work presents the first systematic study of such active malicious attacks against state-of-the-art open-source SSDs. White-box attacks, black-box attacks, and their transferability are studied from both attack effectiveness and stealthiness, using both hardcoded metrics and human ratings. The results highlight the urgent need for more robust detection methods in the face of evolving adversarial threats.
Zero-shot Cross-lingual Voice Transfer for TTS
Sep 20, 2024

In this paper, we introduce a zero-shot Voice Transfer (VT) module that can be seamlessly integrated into a multi-lingual Text-to-speech (TTS) system to transfer an individual's voice across languages. Our proposed VT module comprises a speaker-encoder that processes reference speech, a bottleneck layer, and residual adapters, connected to preexisting TTS layers. We compare the performance of various configurations of these components and report Mean Opinion Score (MOS) and Speaker Similarity across languages. Using a single English reference speech per speaker, we achieve an average voice transfer similarity score of 73% across nine target languages. Vocal characteristics contribute significantly to the construction and perception of individual identity. The loss of one's voice, due to physical or neurological conditions, can lead to a profound sense of loss, impacting one's core identity. As a case study, we demonstrate that our approach can not only transfer typical speech but also restore the voices of individuals with dysarthria, even when only atypical speech samples are available - a valuable utility for those who have never had typical speech or banked their voice. Cross-lingual typical audio samples, plus videos demonstrating voice restoration for dysarthric speakers are available here (google.github.io/tacotron/publications/zero_shot_voice_transfer).
Hierarchical Recurrent Adapters for Efficient Multi-Task Adaptation of Large Speech Models
Mar 25, 2024



Parameter efficient adaptation methods have become a key mechanism to train large pre-trained models for downstream tasks. However, their per-task parameter overhead is considered still high when the number of downstream tasks to adapt for is large. We introduce an adapter module that has a better efficiency in large scale multi-task adaptation scenario. Our adapter is hierarchical in terms of how the adapter parameters are allocated. The adapter consists of a single shared controller network and multiple task-level adapter heads to reduce the per-task parameter overhead without performance regression on downstream tasks. The adapter is also recurrent so the entire adapter parameters are reused across different layers of the pre-trained model. Our Hierarchical Recurrent Adapter (HRA) outperforms the previous adapter-based approaches as well as full model fine-tuning baseline in both single and multi-task adaptation settings when evaluated on automatic speech recognition tasks.
A Scalable Model Specialization Framework for Training and Inference using Submodels and its Application to Speech Model Personalization
Mar 23, 2022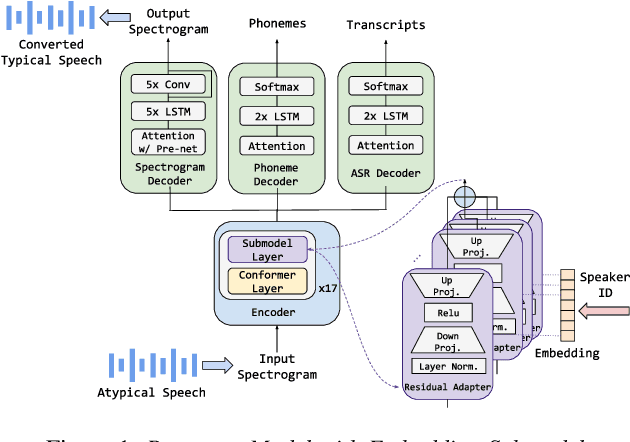
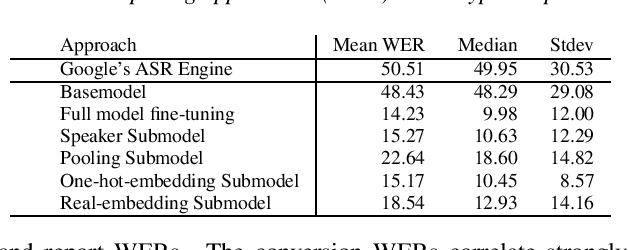
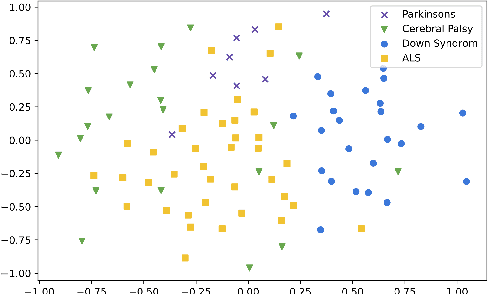
Model fine-tuning and adaptation have become a common approach for model specialization for downstream tasks or domains. Fine-tuning the entire model or a subset of the parameters using light-weight adaptation has shown considerable success across different specialization tasks. Fine-tuning a model for a large number of domains typically requires starting a new training job for every domain posing scaling limitations. Once these models are trained, deploying them also poses significant scalability challenges for inference for real-time applications. In this paper, building upon prior light-weight adaptation techniques, we propose a modular framework that enables us to substantially improve scalability for model training and inference. We introduce Submodels that can be quickly and dynamically loaded for on-the-fly inference. We also propose multiple approaches for training those Submodels in parallel using an embedding space in the same training job. We test our framework on an extreme use-case which is speech model personalization for atypical speech, requiring a Submodel for each user. We obtain 128x Submodel throughput with a fixed computation budget without a loss of accuracy. We also show that learning a speaker-embedding space can scale further and reduce the amount of personalization training data required per speaker.
SpecAugment on Large Scale Datasets
Dec 11, 2019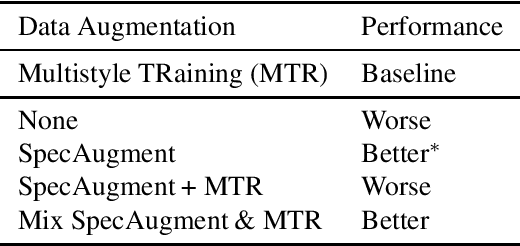
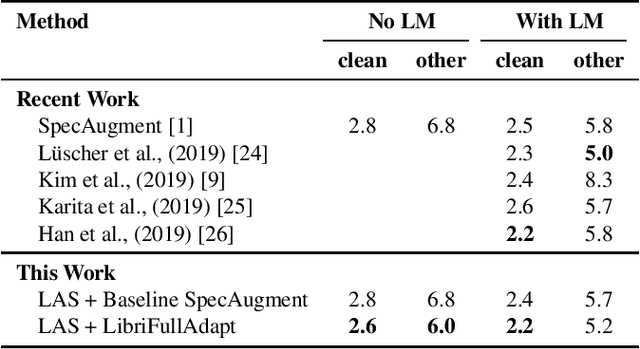
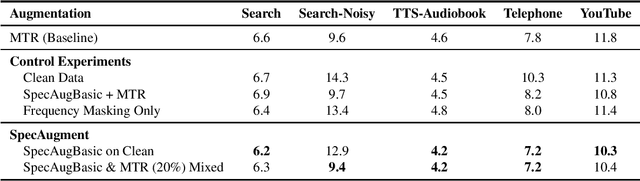
Recently, SpecAugment, an augmentation scheme for automatic speech recognition that acts directly on the spectrogram of input utterances, has shown to be highly effective in enhancing the performance of end-to-end networks on public datasets. In this paper, we demonstrate its effectiveness on tasks with large scale datasets by investigating its application to the Google Multidomain Dataset (Narayanan et al., 2018). We achieve improvement across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model. We also introduce a modification of SpecAugment that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks. By using adaptive masking, we are able to further improve the performance of the Listen, Attend and Spell model on LibriSpeech to 2.2% WER on test-clean and 5.2% WER on test-other.